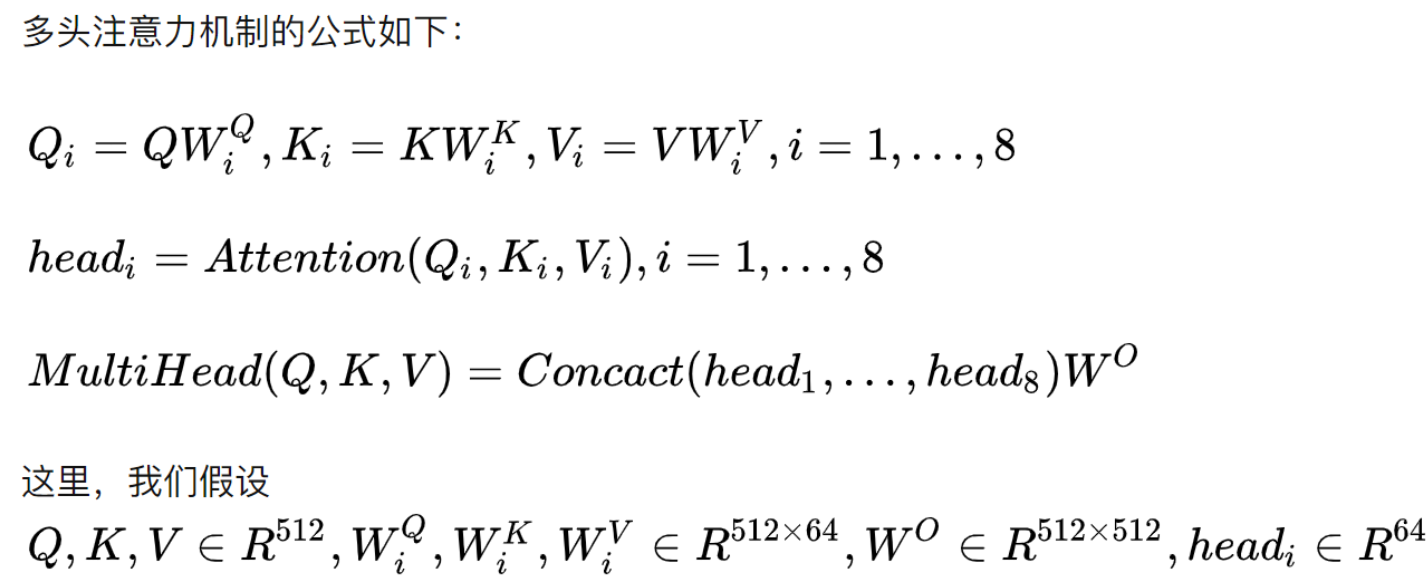import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
device = 'cpu'
epochs = 100
sentences = [
['我 有 一 个 好 朋 友 P', 'S i have a good friend .', 'i have a good friend . E'],
['我 有 零 个 女 朋 友 P', 'S i have zero girl friend .', 'i have zero girl friend . E']
]
src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3, '个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9}
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P': 0, 'i': 1, 'have': 2, 'a': 3, 'good': 4, 'friend': 5, 'zero': 6, 'girl': 7, 'S': 8, 'E': 9, '.': 10}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 8
tgt_len = 7
d_model = 512
d_ff = 2048
d_k = d_v = 64
n_layers = 6
n_heads = 8
def make_data(sentences):
"""把单词序列转换为数字序列"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
class MyDataSet(Data.Dataset):
"""自定义DataLoader"""
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
def get_attn_pad_mask(seq_q, seq_k):
"""这里的q,k表示的是两个序列(跟注意力机制的q,k没有关系),例如encoder_inputs (x1,x2,..xm)和encoder_inputs (x1,x2..xm)
encoder和decoder都可能调用这个函数,所以seq_len视情况而定
seq_q: [batch_size, seq_len] 两个句子,每个句子单词个数
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
"""
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.expand(batch_size, len_q, len_k)
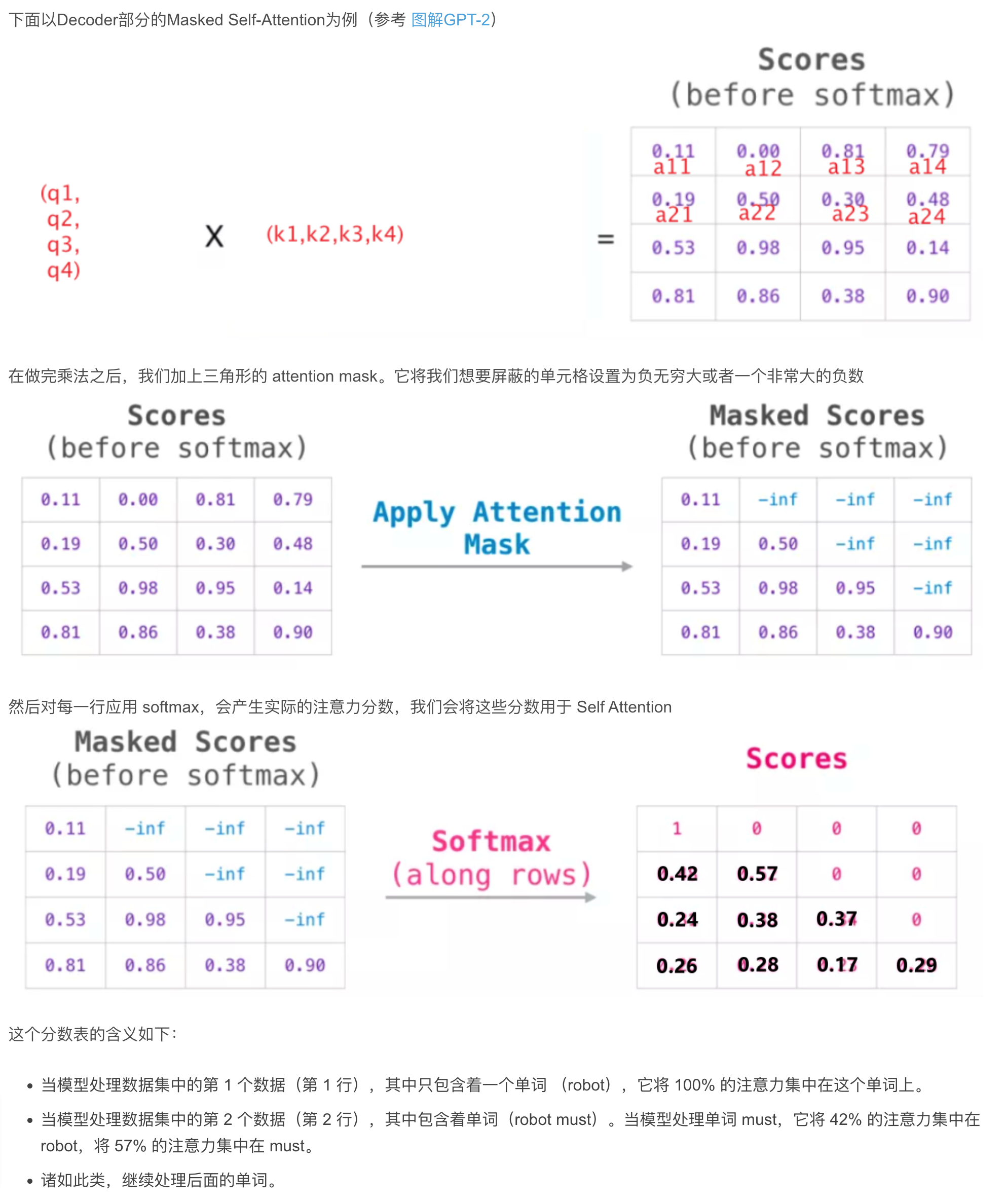
def get_attn_subsequence_mask(seq):
"""建议打印出来看看是什么的输出(一目了然)
seq: [batch_size, tgt_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
"""
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
说明:在encoder-decoder的Attention层中len_q(q1,..qt)和len_k(k1,...km)可能不同
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
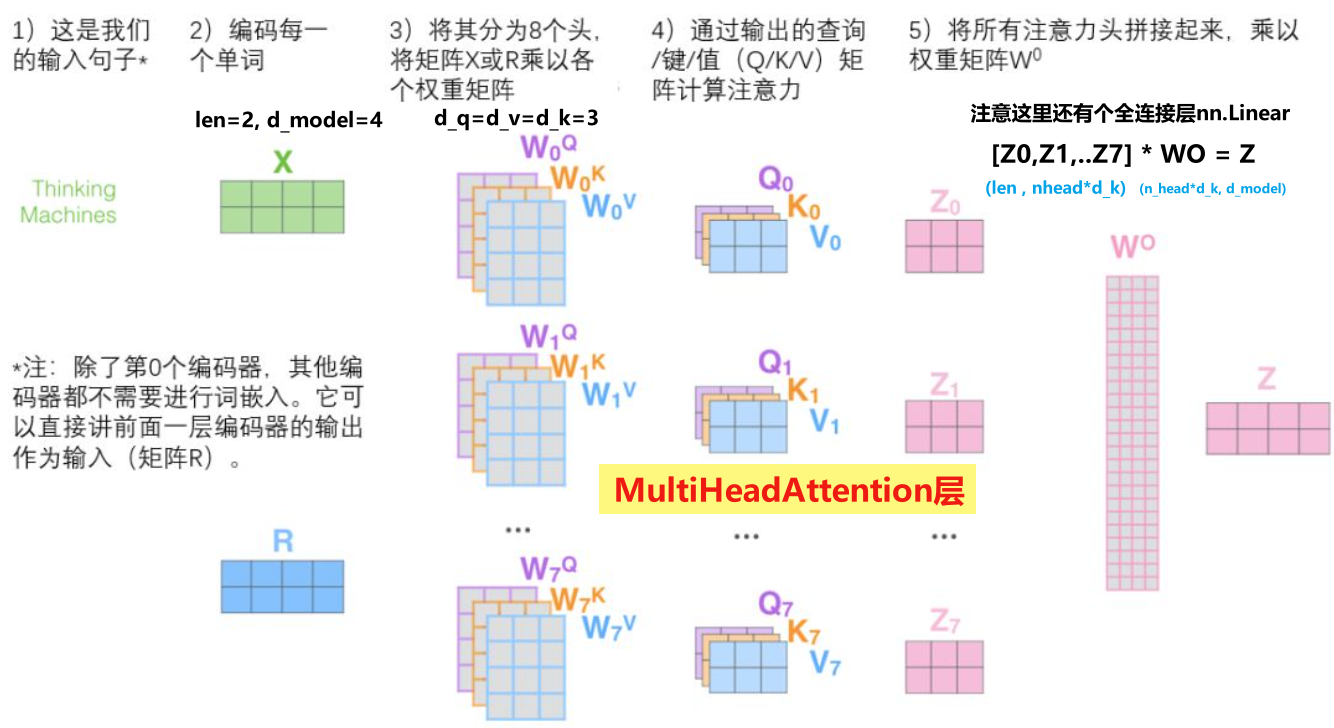
class MultiHeadAttention(nn.Module):
"""这个Attention类可以实现:
Encoder的Self-Attention
Decoder的Masked Self-Attention
Encoder-Decoder的Attention
输入:seq_len x d_model
输出:seq_len x d_model
"""
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
"""
residual, batch_size = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2)
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v)
output = self.fc(context)
return nn.LayerNorm(d_model).to(device)(output + residual), attn
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
inputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).to(device)(output + residual)
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
"""E
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask or sequence mask)
"""
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
"""
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
"""
enc_inputs: [batch_size, src_len]
"""
enc_outputs = self.src_emb(enc_inputs)
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs,
enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model] # 用在Encoder-Decoder Attention层
"""
dec_outputs = self.tgt_emb(dec_inputs)
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).to(
device)
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).to(device)
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(
device)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0).to(device)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0).to(device)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().to(device)
self.decoder = Decoder().to(device)
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).to(device)
def forward(self, enc_inputs, dec_inputs):
"""Transformers的输入:两个序列
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
"""
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs)
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
model = Transformer().to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
for epoch in range(epochs):
for enc_inputs, dec_inputs, dec_outputs in loader:
"""
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
def greedy_decoder(model, enc_input, start_symbol):
"""贪心编码
For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
:param model: Transformer Model
:param enc_input: The encoder input
:param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
:return: The target input
"""
enc_outputs, enc_self_attns = model.encoder(enc_input)
dec_input = torch.zeros(1, 0).type_as(enc_input.data)
terminal = False
next_symbol = start_symbol
while not terminal:
dec_input = torch.cat([dec_input.to(device), torch.tensor([[next_symbol]], dtype=enc_input.dtype).to(device)],
-1)
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[-1]
next_symbol = next_word
if next_symbol == tgt_vocab["E"]:
terminal = True
greedy_dec_predict = dec_input[:, 1:]
return greedy_dec_predict
sentences = [
['我 有 零 个 女 朋 友 P', '', '']
]
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
test_loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
enc_inputs, _, _ = next(iter(test_loader))
print()
print("="*30)
print("利用训练好的Transformer模型将中文句子'我 有 零 个 女 朋 友' 翻译成英文句子: ")
for i in range(len(enc_inputs)):
greedy_dec_predict = greedy_decoder(model, enc_inputs[i].view(1, -1).to(device), start_symbol=tgt_vocab["S"])
print(enc_inputs[i], '->', greedy_dec_predict.squeeze())
print([src_idx2word[t.item()] for t in enc_inputs[i]], '->',
[idx2word[n.item()] for n in greedy_dec_predict.squeeze()])
|