MySQL
注释
# 单行注释 |
数据库管理
查看已有的数据库(文件夹)
show databases;
创建数据库(文件夹)
create database gx_day14 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
删除数据库(文件夹)
drop database gx_day14;
进入数据库(进入文件夹)
use gx_day14;
查看文件夹下所有的数据表(文件)
show tables;
数据表的管理
进入数据库(进入文件夹)
use gx_day14;
查看当前数据库下的所有 表(文件)
show tables;
创建表(文件文件)
create table 表名称(
列名称 类型,
列名称 类型,
列名称 类型
)default charset=utf8;
create table tb1(
id int,
name varchar(16),
age int
) default charset=utf8;create table tb1(
id int,
name varchar(16) not null, -- 不允许为空
age int null -- 允许为空(默认)
) default charset=utf8;create table tb1(
id int,
name varchar(16),
age int default 3 -- 插入数据时,age列的值默认3
) default charset=utf8;create table tb1(
id int primary key, -- 主键(不允许为空,不允许重复)
name varchar(16),
age int
) default charset=utf8;主键一般用于表示当前行的数据的编号(类似于人的身份证)。
create table tb1(
id int auto_increment primary key, -- 内部维护,自增
name varchar(16),
age int
) default charset=utf8;一般情况下,我们再创建表时都会这样来写:【标准】
create table tb1(
id int not null auto_increment primary key,
name varchar(16),
age int
) default charset=utf8;mysql> desc tb1;
# desc +表名用来显示表的状态,包括列名(column name),
# 各个列的类型(Type),各个列的值类型,主外键(Key),默认值,其他;示例如下:
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(16) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)删除表
drop table 表名称;
常用数据类型
tinyint
有符号,取值范围:-128 ~ 127 (有正有负)【默认】
无符号,取值范围:0 ~ 255(只有正)create table tb2(
id int not null auto_increment primary key,
age tinyint -- 有符号:取值范围:-128 ~ 127
) default charset=utf8;create table tb3(
id int not null auto_increment primary key,
age tinyint unsigned -- 无符号:取值范围:0 ~ 255
) default charset=utf8;int
int 表示有符号,取值范围:-2147483648 ~ 2147483647
int unsigned 表示无符号,取值范围:0 ~ 4294967295bigint
有符号,取值范围:-9223372036854775808 ~ 9223372036854775807
无符号,取值范围:0 ~ 18446744073709551615练习题:
# 创建表
create table tb2(
id bigint not null auto_increment primary key,
salary int,
age tinyint
) default charset=utf8;
# 插入数据
insert into tb2(salary,age) values(10000,18);
insert into tb2(salary,age) values(20000,28);
insert into tb2(salary,age) values(30000,38),(40000,40);
# 查看表中的数据
select * from tb2;mysql> show tables;
+--------------------+
| Tables_in_gx_day14 |
+--------------------+
| tb1 |
+--------------------+
1 row in set (0.00 sec)
mysql> create table tb2(
-> id bigint not null auto_increment primary key,
-> salary int,
-> age tinyint
-> ) default charset=utf8;
Query OK, 0 rows affected (0.03 sec)
mysql> show tables;
+--------------------+
| Tables_in_gx_day14 |
+--------------------+
| tb1 |
| tb2 |
+--------------------+
2 rows in set (0.00 sec)
mysql> insert into tb2(salary,age) values(10000,18);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tb2(salary,age) values(20000,28);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tb2(salary,age) values(30000,38),(40000,40);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from tb2;
+----+--------+------+
| id | salary | age |
+----+--------+------+
| 1 | 10000 | 18 |
| 2 | 20000 | 28 |
| 3 | 30000 | 38 |
| 4 | 40000 | 40 |
+----+--------+------+
4 rows in set (0.00 sec)float
double
decimal
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
例如:
create table tb3(
id int not null primary key auto_increment,
salary decimal(8,2)
)default charset=utf8;
insert into tb3(salary) values(1.28);
insert into tb3(salary) values(5.289);
insert into tb3(salary) values(5.282);
insert into tb3(salary) values(122115.11);
select * from tb3;char(m),速度快。
定长字符串,m代表字符串的长度,最多可容纳255个字符。
char(11),固定用11个字符串进行存储,哪怕真是没有11个字符,也会按照11存储。
create table tb4(
id int not null primary key auto_increment,
mobile char(11)
)default charset=utf8;
insert into tb4(mobile) values("151");
insert into tb4(mobile) values("15131255555");varchar(m),节省空间。
变长字符串,m代表字符的长度。 最大65535字节/3 = 最大的m
varchar(11),真实数据有多少长久按照多长存储。
create table tb5(
id int not null primary key auto_increment,
mobile varchar(11)
)default charset=utf8;
insert into tb5(mobile) values("151");
insert into tb5(mobile) values("15131255555");text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
一般情况下,长文本会用text类型。例如:文章、新闻等。
create table tb6(
id int not null primary key auto_increment,
title varchar(128),
content text
)default charset=utf8;mediumtext
A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1)
datetime
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59)
date
YYYY-MM-DD(1000-01-01/9999-12-31)
MySQL还有很多其他的数据类型,例如:set、enum、TinyBlob、Blob、MediumBlob、LongBlob 等,详细见官方文档:https://dev.mysql.com/doc/refman/5.7/en/data-types.html
数据行操作
新增数据
insert into 表名(列名,列名) values(值,值); |
删除数据
delete from 表名; |
delete from tb7; |
修改数据
update 表名 set 列=值; |
update tb7 set password="哈哈哈"; |
查询数据
select * from 表名称; |
select * from tb7; |
连接查询
- 内连接
与等值连接在效果上完全一致。但是开发中建议使用内连接,因为等值连接在查询的时候会将2个表会先进行笛卡尔乘积运算,生成一个新表格,占据在电脑内存里,当表的数据量很大时,很耗内存,这种方法效率比较低;内连接查询时会将2个表根据共同ID进行逐条匹配,不会出现笛卡尔乘积的现象,效率比较高。
select A.c1,B.c2 from A inner join B on A.c3 = B.c3; |
- 自然连接
是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果中把重复的属性列去掉。而等值连接并不去掉重复的属性列。
- 左外连接
包含左边表的全部行(不管右边的表中是否存在与它们匹配的行)以及右边表中全部匹配的行
select A.c1,B.c2 from A left join B on A.c3 = B.c3; |
- 右外连接
包含右边表的全部行(不管左边的表中是否存在与它们匹配的行)以及左边表中全部匹配的行
select A.c1,B.c2 from A right join B on A.c3 = B.c3; |
- 全外连接
包含左、右两个表的全部行,不管在另一边的表中是否存在与它们匹配的行
select A.c1,B.c2 from A full join B on A.c3 = B.c3; |
- (theta)连接
使用等值以外的条件来匹配左、右两个表中的行
select A.c1,B.c2 from A join B on A.c3 != B.c3; |
- 交叉连接
- 自连接(自己和自己做笛卡尔积)
生成笛卡尔积——它不使用任何匹配或者选取条件,而是直接将一个数据源中的每个行与另一个数据源的每个行一一匹配
通俗的说就是查询所得的结果行数是两张表行数的乘积。
select A.c1,B.c2 from A,B; |
聚合函数、GROUP BY、HAVING
聚合函数
计数(Count)、求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN)
GROUP BY、HAVING
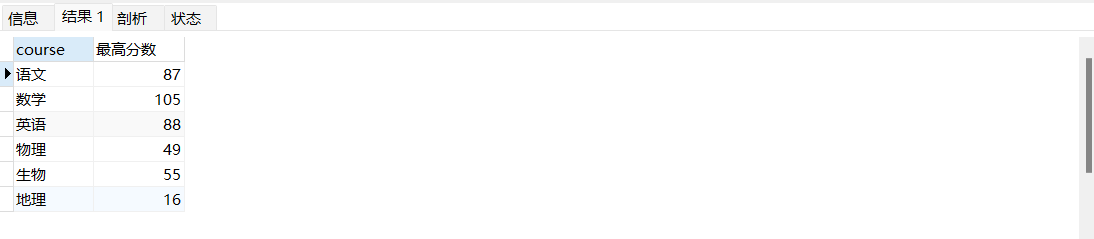
- 想知道每门学科的最高分
SELECT course ,Max(score) AS 最高分数 FROM `t_user` t GROUP BY course |
- 想知道考试时间在2022-09-07号之前每门学科的最高分
SELECT course ,MAX(score) AS 最高分数 FROM `t_user` t WHERE t.create_time > '2022-09-07' GROUP BY course |

- 想知道考试时间在2022-09-07号之前每门学科最高分数在70以上有多少人
SELECT course ,MAX(score) AS 最高分数 FROM `t_user` t WHERE t.create_time > '2022-09-07' GROUP BY course HAVING(最高分数) > 70 |
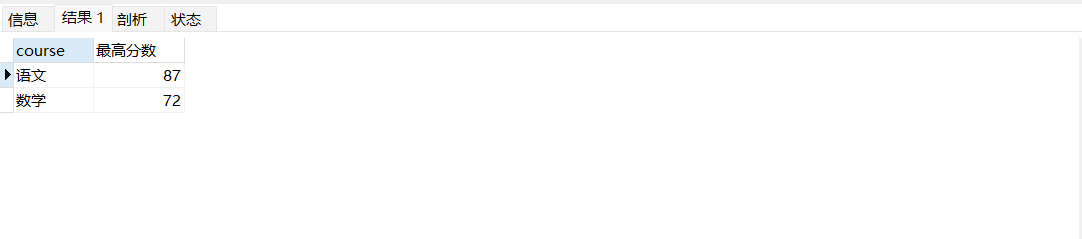
可以发现 我们用了having,对分组之后的结果进行了一个筛选。
关键字顺序 SD FJ OW GWHOL
时代峰峻 欧文 管委会OL
- SELECT
- DISTINCT
<select_list> - FROM
<left_table> <join_type>JOIN<right_table>- ON
<join_condition> - WHERE
<where_condition> - GROUP BY
<group_by_list> - WITH
{CUBE|ROLLUP} - HAVING
<having_condition> - ORDER BY
<order_by_condition> - LIMIT
<limit_number>