文件结构
/Users/jiangangkong/workSpace/vscodeWorkSpace/6.824 |
Lab 1: MapReduce
Introduction
在本实验中,您将构建一个MapReduce系统。您将实现一个调用应用程序Map和Reduce函数并处理文件读写的工作进程,以及一个将任务分发给workers进程并处理失败的工作进程的master进程。您将构建与MapReduce论文类似的东西
Getting started
cd /Users/jiangangkong/workSpace/vscodeWorkSpace |
git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824 |
我们在 src/main/mrsequential.go为你提供了一个简单的 sequential mapreduce 实现 It runs the maps and reduces one at a time, in a single process.
We also provide you with a couple of MapReduce applications:
单词计数器 mrapps/wc.go, 文本索引器 mrapps/indexer.go. 你可以按如下指令运行它们
cd /Users/jiangangkong/workSpace/vscodeWorkSpace/6.824 |
请随意从mrsequence .go中借用代码。您还应该看看mrapps/wc。去看看MapReduce应用程序代码是什么样的
Your Job
您的工作是实现一个分布式MapReduce,由两个程序组成, the master and the worker. There will be just one master process, and one or more worker processes executing in parallel.
The workers will talk to the master via RPC. Each worker process will ask the master for a task, read the task’s input from one or more files, execute the task, and write the task’s output to one or more files. The master should notice if a worker hasn’t completed its task in a reasonable amount of time (for this lab, use ten seconds), and give the same task to a different worker.
为方便你开始,The “main” routines for the master and worker are in main/mrmaster.go and main/mrworker.go;
don’t change these files. Put your implementation in mr/master.go, mr/worker.go, and mr/rpc.go.
Run your code
Here’s how to run your code on the word-count MapReduce application.
First, make sure the word-count plugin is freshly built:
go build -buildmode=plugin ../mrapps/wc.go |
In the main directory, run the master.
rm mr-out* |
The pg-*.txt arguments to mrmaster.go are the input files; each file corresponds to one “split”, and is the input to one Map task.
In one or more other windows, run some workers:
go run mrworker.go wc.so |
When the workers and master have finished, look at the output in mr-out-*. When you’ve completed the lab, the sorted union of the output files should match the sequential output, like this:
cat mr-out-* | sort | more |
We supply you with a test script in main/test-mr.sh. The tests check that the wc and indexer MapReduce applications produce the correct output when given the pg-xxx.txt files as input. The tests also check that your implementation runs the Map and Reduce tasks in parallel, and that your implementation recovers from workers that crash while running tasks.
If you run the test script now, it will hang because the master never finishes:
cd ~/6.824/src/main |
You can change ret := false to true in the Done function in mr/master.go so that the master exits immediately. Then:
sh ./test-mr.sh |
The test script expects to see output in files named mr-out-X, one for each reduce task. The empty implementations of mr/master.go and mr/worker.go don’t produce those files (or do much of anything else), so the test fails.
When you’ve finished, the test script output should look like this:
sh ./test-mr.sh |
You’ll also see some errors from the Go RPC package that look like
2019/12/16 13:27:09 rpc.Register: method "Done" has 1 input parameters; needs exactly three |
Ignore these messages.
A few rules:
map 阶段 should divide the intermediate keys into buckets for
nReducereduce tasks, wherenReduceis the argument thatmain/mrmaster.gopasses toMakeMaster().The worker implementation should put the output of the X’th reduce task in the file
mr-out-X.A
mr-out-Xfile should contain one line per Reduce function output. The line should be generated with the Go"%v %v"format, called with the key and value. Have a look inmain/mrsequential.gomain/mrmaster.goexpectsmr/master.goto implement aDone()method that returns true when the MapReduce job is completely finished; at that point,mrmaster.gowill exit.When the job is completely finished, the worker processes should exit. A simple way to implement this is to use the return value from
call(): if the worker fails to contact the master, it can assume that the master has exited because the job is done, and so the worker can terminate too. Depending on your design, you might also find it helpful to have a “please exit” pseudo-task (伪任务) that the master can give to workers
Hints
One way to get started is to modify
mr/worker.go中的Worker()to send an RPC to the master asking for a task. Then modify the master to respond with the file name of an 尚未启动的 map task. Then modify the worker to read that file and call the application Map function, as inmrsequential.go.中间文件的合理命名约定是mr-X-Y,其中X是Map任务编号,Y是reduce任务编号
Workers的map部分可以使用ihash(key)函数为给定的key选择reduce任务
Workers 有时需要等待,reduces can’t start until the last map has finished. One possibility is for workers to periodically ask the master for work, sleeping with
time.Sleep()between each request. Another possibility is for the relevant RPC handler in the master to have a loop that waits, either withtime.Sleep()orsync.Cond. Go runs the handler for each RPC in its own thread, so the fact that one handler is waiting won’t prevent the master from processing other RPCs.
※流程
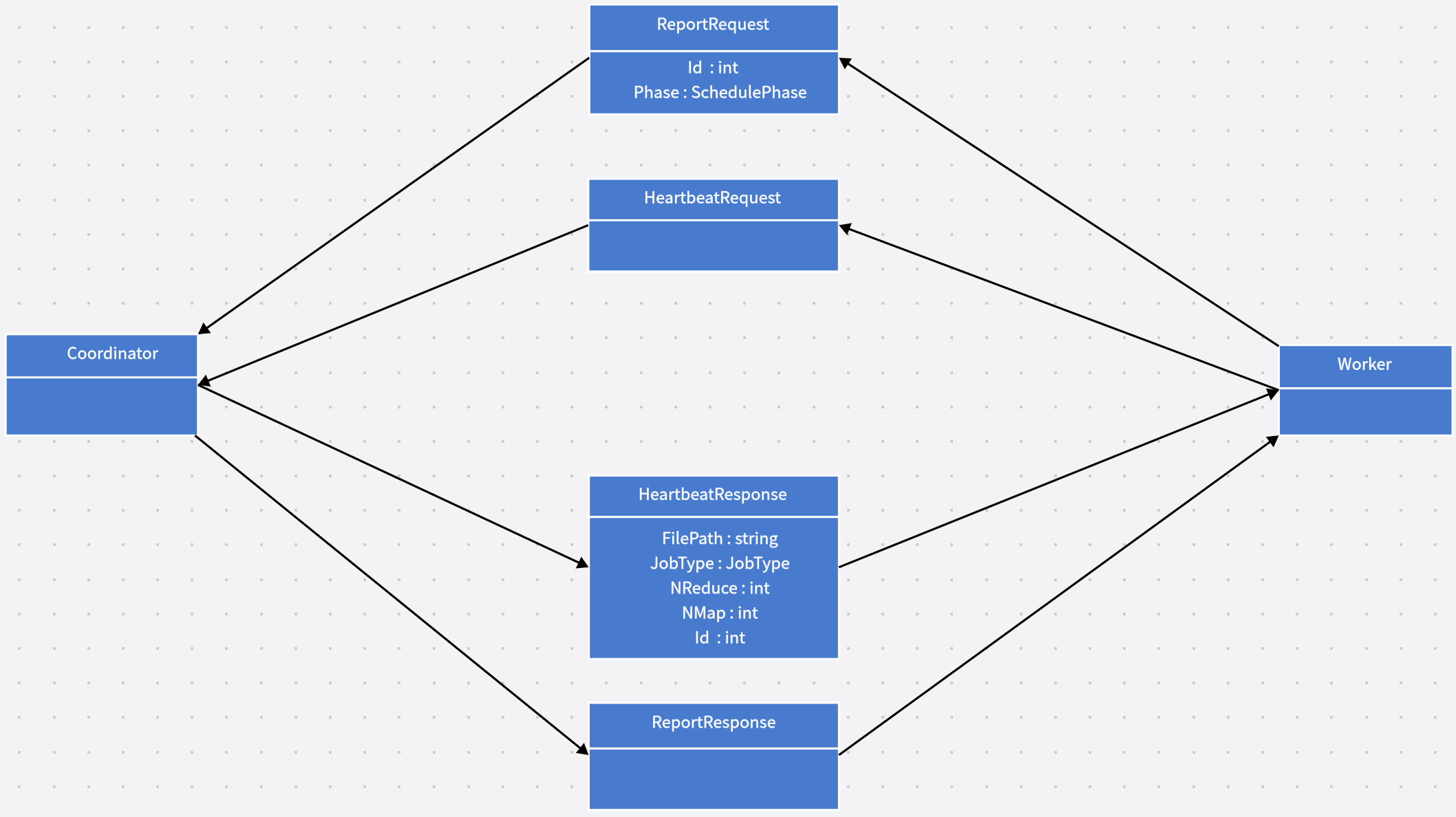
run main/mrcoordinator.go XXX*.txt |
func (c *Coordinator) schedule() { |
Worker 模块
// 只有 doHeartbeat 可能引起状态的转换,doReport 是一个worker 进程完成了 |
func doHeartbeat() *HeartbeatResponse { |
Lab 2A: Raft
选举:
1. 一开始,集群内所有节点都是follower状态,term都为1,各节点维护自己的election_timeout |
type Raft struct { |
func (rf *Raft) GetState() (int, bool) |
Lab3:高可用的 KV 存储服务
1. Finding the cluster
当Raft被公开为网络服务时,客户机必须定位集群以便与复制状态机交互。对于具有固定成员的集群,这很简单;例如,服务器的网络地址可以静态存储在配置文件中。
然而当它的服务器集可以随时间变化时,发现集群是一个更大的挑战。一般有两种方法:
- 客户端可以使用广播或多播来查找所有集群服务器。然而,这将只能在支持这些特性的特定环境中工作。
- 是客户端通过外部目录服务(如DNS)找到集群中的服务器,并在集群成员更改时更新目录
LogCabin客户端目前使用DNS来查找集群。
LogCabin目前不自动更新DNS在成员更改之前和之后的记录(这交给管理脚本)

Clients 使用 ClientRequest RPC 修改 replicated state;
Clients 使用 ClientQuery RPC 查询 replicated state.
New Clients 通过 RegisterClient RPC 接收他们的 client identifier , which helps identify when session information needed for linearizability has been discarded.
不是leader 的服务器 redirect clients to the leader, and read-only requests are serviced without relying on clocks for linearizability (本文提出了替代方案).
2. Routing requests to the leader
Raft中的客户端请求是通过leader处理的。当客户端第一次启动时,它连接到一个随机选择的服务器。如果客户的选择不是leader,该服务器拒绝请求。如果客户端暴力枚举并标记选过的server,那么n大小的集群平均需要n+1/2次尝试,对于小的集群已经足够快了
通过简单的优化也可以更快地将请求路由到leader。follower服务器通常知道当前集群leader的地址,因为AppendEntries请求包括leader的地址。当不是leader的服务器接收到来自客户端的请求时,它可以执行两种操作中的一种:
- 我们推荐的也是LogCabin实现的,是让服务拒绝请求并返回leader的地址(如果已知)给客户端
- 服务器可以将客户端的请求代理给领导者。这可能更简单
Raft 还必须防止陈旧的leader信息无限期地延迟客户请求。信息可能会在整个系统中变得陈旧,包括leader、follower和client:
leader:A server might be in the leader state, but if it isn’t the current leader, it could be needlessly delaying client requests. For example, suppose a leader is partitioned from the rest of the cluster, but it can still communicate with a particular client. Without additional mechanism, it could delay a request from that client forever, being unable to replicate a log entry to any other servers.Meanwhile, there might be another leader of a newer term that is able to communicate with a majority of the cluster and would be able to commit the client’s request. Thus, a leader in Raft steps down if an election timeout elapses without a successful round of heartbeats to a majority of its cluster; this allows clients to retry their requests with another server.
follower:follower跟踪leader的身份,以便他们可以重定向或代理客户。 他们必须在开始新的选举或任期届满时丢弃这些信息。 否则,他们可能会不必要地延迟客户(例如,有可能两个服务器相互重定向,将客户端置于无限循环中)。
client:如果客户端失去与leader(或任何特定服务器)的连接,它应该只需使用随机服务器重试。 坚持能够联系最后一个已知的领导者.如果该服务器出现故障,将导致不必要的延迟。
3. Implementing linearizable semantics语义
即实现对KV 存储服务操作的幂等性
在后端开发中,幂等性指的是一个操作的执行结果在多次重复执行时,产生的效果与仅执行一次的效果相同。简单来说,就是对于同一个操作,多次执行所产生的结果和仅执行一次的结果相同。
幂等性是一个非常重要的概念,因为在分布式系统中,由于网络的不可靠性和消息重复的可能性,会导致同一个请求被多次执行,如果该请求是非幂等的,则可能会导致系统数据的错误或者不一致。而如果该请求是幂等的,则可以保证系统数据的正确性和一致性。
每个要做proposal的client需要一个唯一的identifier,它的每个不同proposal需要有一个顺序递增的序列号,client id和这个序列号由此可以唯一确定一个不同的proposal,从而使得各个raft节点可以记录保存各proposal应用以后的结果。
当一个proposal超时,client不提高proposal的序列号,使用原proposal序列号重试。
当一个proposal被成功提交并应用且被成功回复给client以后,client顺序提高proposal的序列号,并记录下收到的成功回复的proposal的序列号。raft节点收到一个proposal请求以后,得到请求中夹带的这个最大成功回复的proposal的序列号,它和它之前所有的应用结果都可以删去。proposal序列号和client id可用于判断这个proposal是否应用过,如果已经应用过,则不再再次应用,直接返回已保存的结果。等于是每个不同的proposal可以被commit多次,在log中出现多次,但永远只会被apply一次。
系统维护一定数量允许的client数量,比如可以用LRU策略淘汰。请求过来了,而client已经被LRU淘汰掉了,则让client直接fail掉。
这些已经注册的client信息,包括和这些client配套的上述proposal结果、各序列号等等,需要在raft组内一致的维护。也就是说,上述各raft端数据结构和它们的操作实际是state machine的一部分。在做snapshotting的时候,它们同样需要被保存与恢复。
以下是论文⬇️
假设一个client 向leader发送了一条命令 and the leader appends the command 并提交了log条目, 但是leader在回复client前崩溃了。
由于客户端没有收到确认,所以它将命令重新提交给新的leader,它反过来将命令作为一个新条目追加到它的日志中,并提交这个新条目。尽管客户端希望命令执行一次,但实际上执行了两次。
如果网络可以复制客户端的请求,即使没有客户端的参与,命令也可以应用多次。
这个问题并不是Raft独有的;它出现在大多数有状态的分布式系统中。然而,这些“至少一次”语义特别不适合基于共识的系统,在这种系统中客户通常需要更强的保证。
重复命令的问题可能会以微妙的方式表现出来,client很难从中恢复过来。
这些问题会导致不正确的结果或不正确的状态。 图 6.2 显示了一个错误结果的示例:状态机正在提供锁,而客户端发现它无法获取锁,因为它的原始请求——它没有收到确认——已经获取了锁。
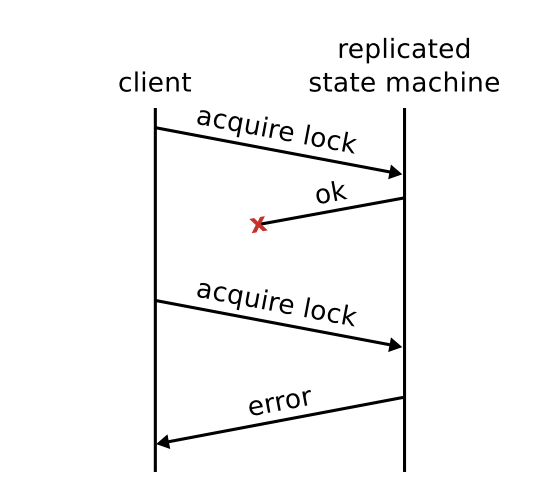
我们在 Raft 中的目标是实现可线性化的语义 ,从而避免这些类别的问题。 在可线性化中,每个操作都立即执行,精确的一次,在它的调用和响应之间的某一时间点。 这是一种强一致性形式,对于客户端进行推理,并且它不允许多次处理命令。
为了在Raft中实现线性化,服务器必须过滤掉重复的请求。基本思想是服务器保存客户端操作的结果,并使用它们跳过执行相同的请求。
为了实现这一点,每个client都有一个唯一的标识符,client为每个命令分配唯一的序列号。 每个server的状态机为每个client维护一个session。该会话跟踪被client处理的最新序列号,以及相关的响应。 如果server收到序列号已经被执行过的命令,它会立即响应,而不会重新执行该请求。
有了重复请求的过滤,Raft提供了线性化。Raft日志提供了一个在每台服务器上应用命令的串行顺序。命令根据它们在 Raft 日志中的第一次出现立即生效,并且恰好一次,因为任何后续出现都会被状态机过滤掉。
client会记录它已经发送的请求序列号和对应的响应,以确保不会丢失或重复处理请求。同时,cilent还会告诉server它尚未收到的最低序列号,以确保server不会重复发送之前已经发送过的响应。server则会根据client的请求序列号和最低未收到响应的序列号,保证client能够正确处理所有请求。如果client已经收到了某个序列号的响应,那么它可以丢弃所有低于该序列号的响应,因为这些响应已经不再需要了
不幸的是,由于空间有限,会话不能永远保存。服务器最终必须决定终止客户端的会话,但这会产生两个问题:
- 服务器何时使客户端的会话过期
- 如何处理会话被过早终止的活动客户端
服务器必须就客户端会话何时过期达成一致; 否则,服务器的状态机可能会彼此不同。 例如,假设一个服务器使特定客户端的会话过期,然后重新应用该客户端的许多重复命令; 同时,其他服务器使会话保持活动状态并且不应用重复项。 复制的状态机将变得不一致。 为避免此类问题,会话过期必须是确定性的,就像正常的状态机操作一样。
一种选择是设置会话数量的上限并使用 LRU(最近最少使用)策略删除条目。
另一种选择是根据商定的时间源使会话过期。
在 LogCabin 中,领导者使用当前时间来增加它附加到 Raft 日志的每个命令。 作为提交日志条目的一部分,服务器就此时间达成一致; 然后,状态机确定性地使用这个时间输入来使非活动会话过期。 Live clients 在不活动期间发出 keep-alive 请求,这些请求也增加了 leader 的时间戳并提交到 Raft 日志,以维持他们的会话。
第二个问题是如何处理会话过期后继续运行的客户端。 我们希望这是一种特殊情况; 然而,它总是存在一些风险,因为通常无法知道客户何时退出。 一种选择是在没有记录的任何时候为客户端分配一个新会话,但这会冒重复执行的风险
在客户端的上一个会话过期之前执行的命令。 为了提供更严格的保证,服务器需要区分新客户端和会话已过期的客户端。 当客户端首次启动时,它可以使用 RegisterClient RPC 将自己注册到集群。 这会分配新客户端的会话并向客户端返回其标识符,客户端将其包含在所有后续命令中。 如果状态机遇到没有会话记录的命令,它不会处理该命令,而是向客户端返回错误。 在这种情况下,LogCabin 当前会导致客户端崩溃(大多数客户端可能不会优雅且正确地处理会话过期错误,但系统通常必须已经处理客户端崩溃)。
Lab 4: Sharded Key/Value Service
In this lab you’ll build a key/value storage system that “shards,” or partitions.
for example, all the keys starting with “a” might be one shard, all the keys starting with “b” another, etc
Your sharded key/value store will have two main components. First, a set of replica groups. Each replica group is responsible for a subset of the shards.A replica consists of a handful of servers that use Raft to replicate the group’s shards.
第二个组成部分是“shard controller”。分片控制器决定哪个复制组应该为每个分片提供服务;这些信息称为配置。配置随时间变化。客户端向分片控制器查询以找到密钥的复制组,而复制组向控制器查询以找出要提供服务的分片。整个系统只有一个分片控制器,使用Raft实现为容错服务。
难点
一个分片存储系统必须能够在复制组之间转移分片。一个原因是某些组可能比其他组负载更重,因此需要移动分片以平衡负载。另一个原因是复制组可能加入和离开系统:新的复制组可以添加以增加容量,或者现有的复制组可能因维修或退役而下线。
本实验的主要挑战在于处理重新配置 - 分配分片到组的更改。在单个复制组内,所有组成员必须在客户端Put/Append/Get请求与重新配置之间达成一致。例如,当一个Put到达时,可能同时发生了一个重新配置,导致复制组不再负责持有Put密钥的分片。组中的所有副本必须就Put是否发生在重新配置之前或之后达成一致。如果在之前,Put应该生效,分片的新所有者将看到其效果;如果在之后,Put将不会生效,客户端必须在新的所有者处重试。建议的方法是让每个复制组使用Raft来记录不仅是Put,Append和Get序列,还要记录重新配置的序列。您需要确保每个分片在任何时间内最多由一个复制组为请求提供服务。
重新配置还需要复制组之间的交互。例如,在配置10中,组G1可能负责分片S1。在配置11中,组G2可能负责分片S1。在从10到11的重新配置期间,G1和G2必须使用RPC将S1的内容(键/值对)从G1移动到G2。