list = ["01", "02", "03", "04"] # 1 for num inlist: print(num) # 2 for i inrange(len(list)): print(list[i]) # 3 for num initer(list): print(num) # 4 for obj inenumerate(list): print(obj) for index, value inenumerate(list): print("index =", index, "value =", value)
比较list元素, [False, True, True, False]
# 使用列表推导式 print([x > 2for x in a])
# 使用 map 函数 print(list(map(lambda x: x > 2, a)))
dict
defmulti_word_search(doc_list, keywords): """ Takes list of documents (each document is a string) and a list of keywords. Returns a dictionary where each key is a keyword, and the value is a list of indices (from doc_list) of the documents containing that keyword >>> doc_list = ["The Learn Python Challenge Casino.", "They bought a car and a casino", "Casinoville"] >>> keywords = ['casino', 'they'] >>> multi_word_search(doc_list, keywords) {'casino': [0, 1], 'they': [1]} """ indices = {} for x in keywords: indices[x] = [] for i, doc inenumerate(doc_list): tokens = doc.split() normalized = [token.rstrip('.,').lower() for token in tokens] for x in keywords: if x.lower() in normalized: indices[x].append(i) return indices
🚨 BREAKING NEWS 🔴 Raja Live all Slot Channels Welcome 🎰
18.07.05
Wt9Gkpmbt44
TheBigJackpot
24
2018-05-07T06:58:59.000Z
Slot Machine|”win”|”Gambling”|”Big Win”|”raja”…
28973
2167
175
10
…
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
🚨Active Shooter at YouTube Headquarters
18.04.04
Az72jrKbANA
Right Side Broadcasting Network
25
2018-04-03T23:12:37.000Z
YouTube shooter|”YouTube active shooter”|”acti…
103513
1722
181
76
…
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
Intro to ML
DecisionTreeRegressor
# Code you have previously used to load data import pandas as pd from sklearn.metrics import mean_absolute_error from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor
# Path of the file to read iowa_file_path = '../input/home-data-for-ml-course/train.csv'
home_data = pd.read_csv(iowa_file_path) # Create target object and call it y y = home_data.SalePrice # Create X features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd'] X = home_data[features]
# Split into validation and training data train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
# Specify Model iowa_model = DecisionTreeRegressor(random_state=1) # Fit Model iowa_model.fit(train_X, train_y)
# Make validation predictions and calculate mean absolute error val_predictions = iowa_model.predict(val_X) val_mae = mean_absolute_error(val_predictions, val_y) print("Validation MAE: {:,.0f}".format(val_mae))
优化DecisionTreeRegressor
改变决策树的最大深度
defget_mae(max_leaf_nodes, train_X, val_X, train_y, val_y): model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0) model.fit(train_X, train_y) preds_val = model.predict(val_X) mae = mean_absolute_error(val_y, preds_val) return(mae)
from sklearn.ensemble import RandomForestRegressor
# Define the model. Set random_state to 1 rf_model = RandomForestRegressor(random_state = 1)
# fit your model rf_model.fit(train_X, train_y)
# Calculate the mean absolute error of your Random Forest model on the validation data rf_val_mae = mean_absolute_error(rf_model.predict(val_X), val_y)
print("Validation MAE for Random Forest Model: {}".format(rf_val_mae))
Intermediate ML
处理缺失值
处理缺失值的三种方法:
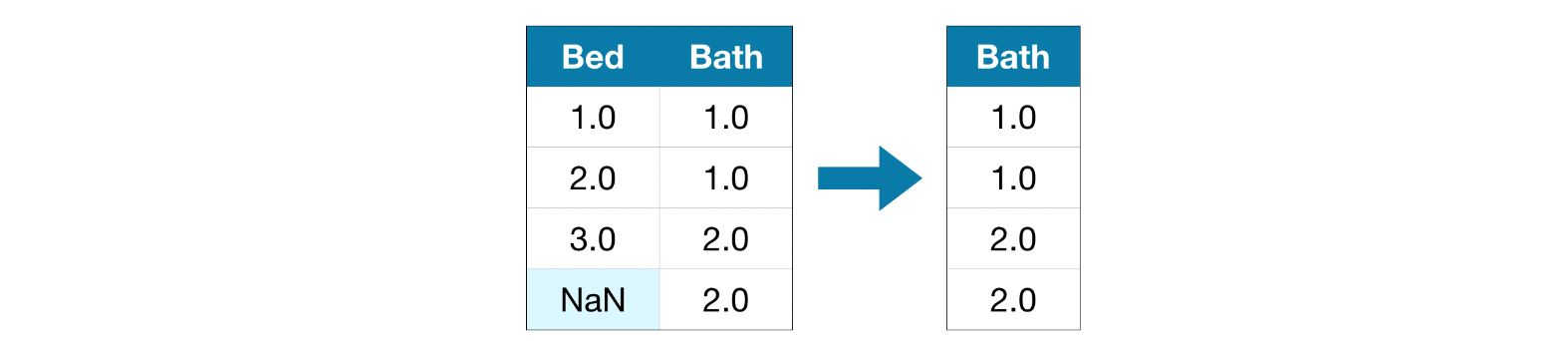
A Simple Option: Drop Columns with Missing Values
A Better Option: Imputation 归因
Imputation fills in the missing values with some number. For instance, we can fill in the mean value along each column.
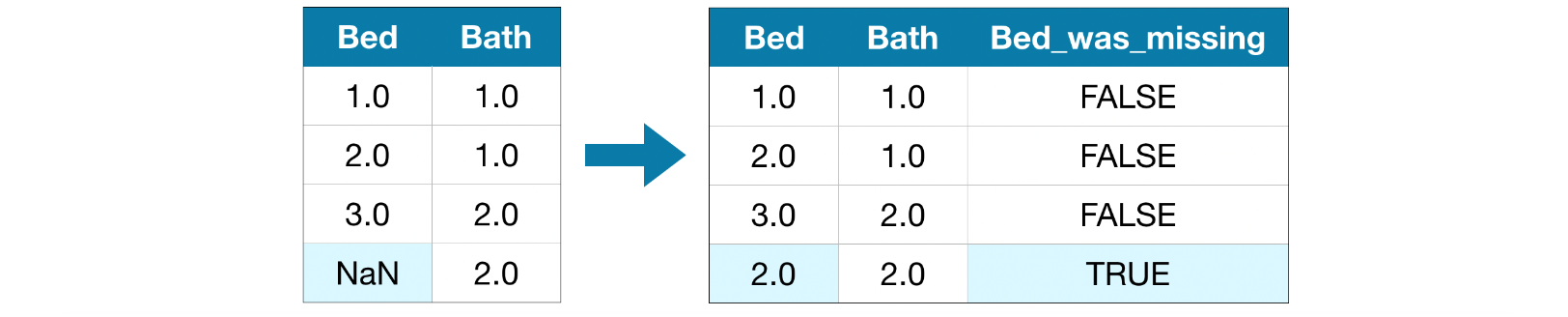
An Extension To Imputation
Example
import pandas as pd from sklearn.model_selection import train_test_split
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv') y = data.Price # Select target
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches defscore_dataset(X_train, X_valid, y_train, y_valid): model = RandomForestRegressor(n_estimators=10, random_state=0) model.fit(X_train, y_train) preds = model.predict(X_valid) return mean_absolute_error(y_valid, preds)
Score of Approach 1(drop)
# Get names of columns with missing values cols_with_missing = [col for col in X_train.columns if X_train[col].isnull().any()]
# Drop columns in training and validation data reduced_X_train = X_train.drop(cols_with_missing, axis=1) reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):") print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid)) # MAE from Approach 1 (Drop columns with missing values): 183550.22137772635
print("MAE from Approach 2 (Imputation):") print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid)) # MAE from Approach 2 (Imputation): 178166.46269899711
Score of Approach 3 (Extension to Imputation)
# Make copy to avoid changing original data (when imputing) X_train_plus = X_train.copy() X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed for col in cols_with_missing: X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull() X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation removed column names; put them back imputed_X_train_plus.columns = X_train_plus.columns imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):") print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid)) # MAE from Approach 3 (An Extension to Imputation): 178927.503183954
import pandas as pd from sklearn.model_selection import train_test_split
# Read the data data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Separate target from predictors y = data.Price X = data.drop(['Price'], axis=1)
# Divide data into training and validation subsets X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
# Drop columns with missing values (simplest approach) cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()] X_train_full.drop(cols_with_missing, axis=1, inplace=True) X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# "Cardinality" means the number of unique values in a column 选择基数 < 10 的列 # Select categorical columns with relatively low cardinality (convenient but arbitrary) low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and X_train_full[cname].dtype == "object"]
# Select numerical columns numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
print("MAE from Approach 1 (Drop categorical variables):") print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid)) # MAE from Approach 1 (Drop categorical variables): 175703.48185157913
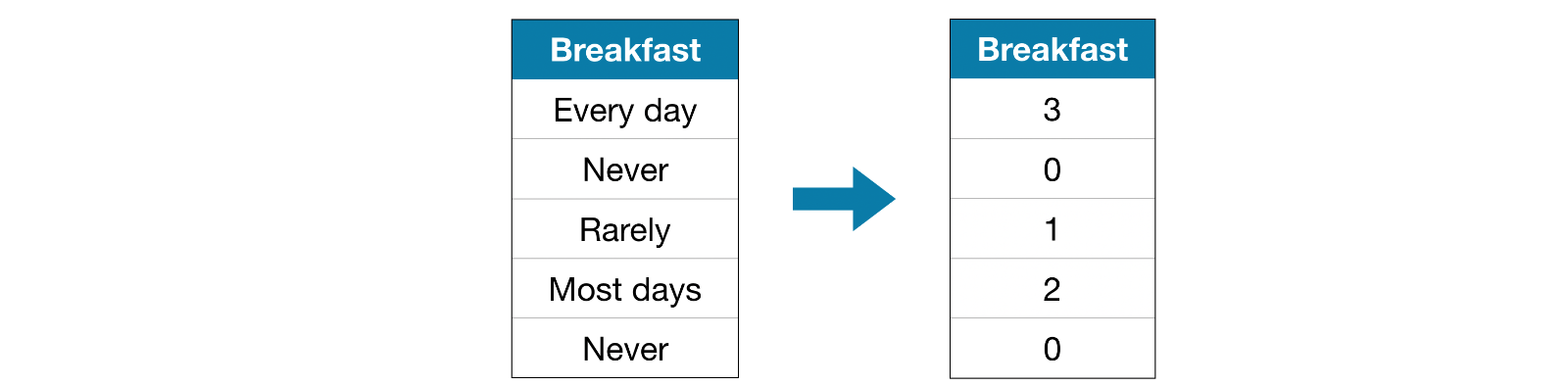
Score of Approach 2 (Ordinal Encoding)
from sklearn.preprocessing import OrdinalEncoder
label_X_train = X_train.copy() # Make copy to avoid changing original data label_X_valid = X_valid.copy()
# Apply ordinal encoder to each column with categorical data ordinal_encoder = OrdinalEncoder() label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols]) label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):") print(score_dataset(label_X_train, label_X_valid, y_train, y_valid)) # MAE from Approach 2 (Ordinal Encoding): 165936.40548390493
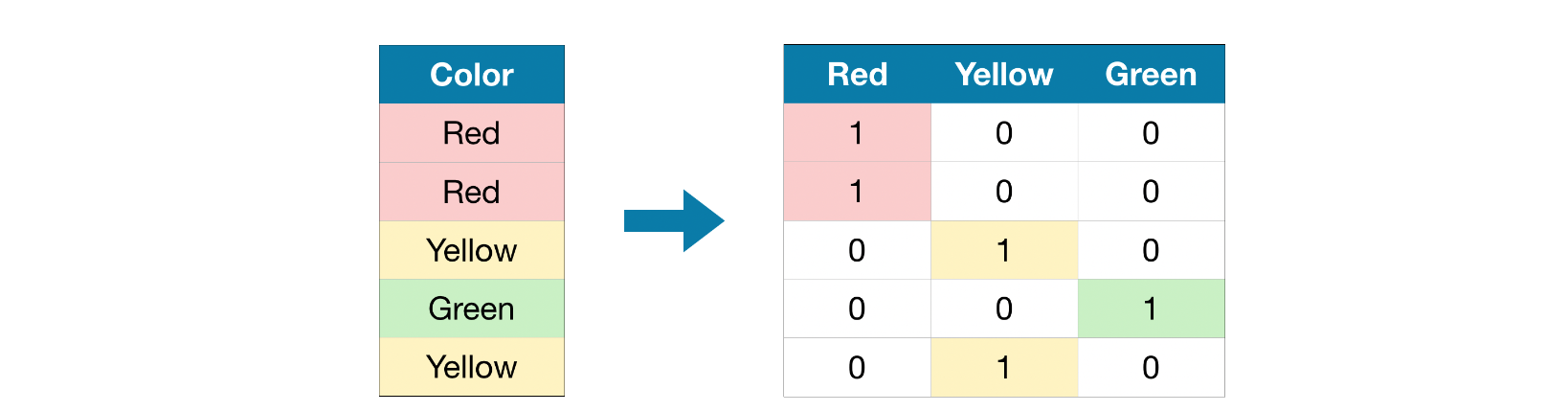
Score of Approach 3 (One-Hot Encoding)
from sklearn.preprocessing import OneHotEncoder
# Apply one-hot encoder to each column with categorical data OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False) OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols])) OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding removed index; put it back OH_cols_train.index = X_train.index OH_cols_valid.index = X_valid.index
import pandas as pd from sklearn.model_selection import train_test_split
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
y = data.Price X = data.drop(['Price'], axis=1)
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
categorical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10and X_train_full[cname].dtype == "object"] numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']] my_cols = categorical_cols + numerical_cols
# we use the ColumnTransformer class to bundle together different preprocessing steps from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from sklearn.impute import SimpleImputer from sklearn.preprocessing import OneHotEncoder
# Preprocessing for numerical data numerical_transformer = SimpleImputer(strategy='constant')
# Preprocessing for categorical data categorical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='most_frequent')), ('onehot', OneHotEncoder(handle_unknown='ignore')) ])
# Bundle preprocessing for numerical and categorical data preprocessor = ColumnTransformer( transformers=[ ('num', numerical_transformer, numerical_cols), ('cat', categorical_transformer, categorical_cols) ])
We refer to the random forest method as an “ensemble method”. By definition, ensemble methods combine the predictions of several models (e.g., several trees, in the case of random forests).
Next, we’ll learn about another ensemble method called gradient boosting.
Example
import pandas as pd from sklearn.model_selection import train_test_split
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt'] X = data[cols_to_use] y = data.Price
data = pd.read_csv('../input/aer-credit-card-data/AER_credit_card_data.csv', true_values = ['yes'], false_values = ['no'])
y = data.card X = data.drop(['card'], axis=1)
print("Number of rows in the dataset:", X.shape[0]) # Number of rows in the dataset: 1319 X.head()
reports
age
income
share
expenditure
owner
selfemp
dependents
months
majorcards
active
0
0
37.66667
4.5200
0.033270
124.983300
True
False
3
54
1
12
1
0
33.25000
2.4200
0.005217
9.854167
False
False
3
34
1
13
2
0
33.66667
4.5000
0.004156
15.000000
True
False
4
58
1
5
3
0
30.50000
2.5400
0.065214
137.869200
False
False
0
25
1
7
4
0
32.16667
9.7867
0.067051
546.503300
True
False
2
64
1
5
from sklearn.pipeline import make_pipeline from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score
# Since there is no preprocessing, we don't need a pipeline (used anyway as best practice!) my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100)) cv_scores = cross_val_score(my_pipeline, X, y, cv=5, scoring='accuracy')
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \ %((expenditures_noncardholders == 0).mean())) print('Fraction of those who received a card and had no expenditures: %.2f' \ %(( expenditures_cardholders == 0).mean()))
# Fraction of those who did not receive a card and had no expenditures: 1.00 # Fraction of those who received a card and had no expenditures: 0.02
# Drop leaky predictors from dataset potential_leaks = ['expenditure', 'share', 'active', 'majorcards'] X2 = X.drop(potential_leaks, axis=1)
# Evaluate the model with leaky predictors removed cv_scores = cross_val_score(my_pipeline, X2, y, cv=5, scoring='accuracy')