Notes
| 01-introduction.pdf | 2022-01-07 10:55 | 88K | |
| 02-advancedsql.pdf | 2022-01-07 10:55 | 107K | |
| 03-storage1.pdf | 2022-01-07 10:55 | 68K | |
| 04-storage2.pdf | 2022-01-07 10:55 | 290K | |
| 05-bufferpool.pdf | 2022-01-07 10:55 | 256K | |
| 06-hashtables.pdf | 2022-01-07 10:55 | 76K | |
| 07-trees.pdf | 2022-01-07 10:55 | 255K | |
| 08-indexconcurrency.pdf | 2022-01-07 10:55 | 77K | |
| 09-sorting.pdf | 2022-01-07 10:55 | 118K | |
| 10-joins.pdf | 2022-01-07 10:55 | 163K | |
| 11-queryexecution1.pdf | 2022-01-07 10:55 | 770K | |
| 12-queryexecution2.pdf | 2022-01-07 10:55 | 677K | |
| 13-optimization1.pdf | 2022-01-07 10:55 | 628K | |
| 14-optimization2.pdf | 2022-01-07 10:55 | 839K | |
| 15-concurrencycontrol.pdf | 2022-01-07 10:55 | 89K | |
| 16-twophaselocking.pdf | 2022-01-07 10:55 | 89K | |
| 17-timestampordering.pdf | 2022-01-07 10:55 | 86K | |
| 18-multiversioning.pdf | 2022-01-07 10:55 | 59K | |
| 19-logging.pdf | 2022-01-07 10:55 | 284K | |
| 20-recovery.pdf | 2022-01-07 10:55 | 451K | |
| 21-distributed.pdf | 2022-01-07 10:55 | 454K | |
| 22-distributedoltp.pdf | 2022-01-07 10:55 | 67K | |
| 23-distributedolap.pdf | 2022-01-07 10:55 | 268K |
章节
01 - introduction
1 Databases
数据库是一个可以模拟真实世界的某些方面的有组织的, 相互关联的数据的集合
数据库与数据库管理系统(DBMS, 如MySQL, Oracle, MongoDB)不同. DBMS是管理数据库的软件
2 Flat File Strawman
没有数据库之前,我们用简单的文件存储数据,有几个问题 (用开发音乐软件举例) :
- Data Integrity 数据完整性
– How do we ensure that the artist is the same for each album entry?
– What if somebody overwrites the album year with an invalid string?
– How do we treat multiple artists on one album?
– What happens when we delete an artist with an album?
- Implementation 实现
– How do we find a particular record?
– What if we now want to create a new application that uses the same database?
– What if two threads try to write to the same file at the same time?
- Durability 持久性
– What if the machine crashes while our program is updating a record?
– What if we want to replicate the database on multiple machines for high availability?
3 DBMS
DBMS用于定义、创建、查询、更新和管理数据库
DBMS很难构建和维护,因为逻辑层和物理层之间存在紧密耦合。
逻辑层描述数据库具有哪些实体和属性,而物理层是那些实体和属性被存储的方式。在早期,物理层被定义在应用软件中,如果我们想
更改应用程序正在使用的物理层,我们必须更改所有代码以匹配新的物理层。
4 Relational Model 关系模型
Ted Codd注意到,每当人们想要更改物理层时,他们都会重写DBMS,因此在1970年,他提出了关系模型来避免这种情况。
这个关系模型有三个关键点:
将数据库存储在简单的数据结构(关系)中。
通过高级语言访问数据。
待实现的物理存储。
数据模型(Data Model) 是用于描述数据库中数据的概念的集合。关系模型是一个数据模型的示例。
架构(Schema) 给定数据模型下对特定的数据集的描述
关系数据模型定义了三个概念:
结构:关系及其内容的定义。
完整性:确保数据库的内容满足约束。一个约束的例子是year属性的任何值都必须是一个数字。
操作:如何访问和修改数据库的内容。
关系 是包含表示实体的属性关系的无序集。关系是无序的,DBMS可以以任何它想要的方式存储它们,允许优化。
元组(Tuple) 是关系中的一组属性值(也称为它的域)。每个属性都可以是特殊的value, NULL,这意味着对于给定的元组,属性是未定义的。
n-ary关系 具有n个属性的关系称为n-ary关系。
主键 关系的主键唯一标识单个元组。一些dbms自动创建一个内部主键如果你没定义的话
外键 指定一个关系中的属性必须映射到另一个关系中的元组(若不想加一列外键,可以使用中间表使两表关联)
5 数据操作语言(DML)
DML增删改查
从数据库中存储和检索信息的语言。有两类:
- 过程性(Procedural) 查询指定了DBMS应该使用的(高级)策略来查找所需的数据结果。
- 非过程性(Non-Procedural) 查询只指定需要什么数据,而不指定如何查找它
6 Relational Algebra
关系代数是一组用于检索和操作关系中的元组的基本操作。
每一个运算符接受一个或多个关系作为输入,并输出一个新的关系。
Relational algebra is a procedural language because it defines the high level-steps of how to compute a query.
关系代数属于过程性DMLs
Select

Projection 投影

Union
SQL中UNION ALL是不去重的, UNION是去重的

Intersection

Difference

Product 笛卡尔积

Join

* 相关词汇
plagiarize [ˈpleɪdʒəraɪz] v.剽窃,抄袭
manipulate v.操作
coordinate v. 协调,配合
formula n.公式
fledged adj.成熟的
redundant adj.多余的
internal n.内部结构
inter-related adj.相互关联的
coupling n.耦合
procedural adj.程序上的,过程上的
algebra n.代数
02 - Advanced SQL
1 关系语言
SQL 是 Structured Query Language 的缩写,中文译为“结构化查询语言”。SQL 是一种计算机语言,用来存储、检索和修改关系型数据库中存储的数据。
SQL 是关系型数据库的标准语言,所有的关系型数据库管理系统(RDBMS),比如 MySQL、Oracle、SQL Server、MS Access、Sybase、Informix、Postgres 等,都将 SQL 作为其标准处理语言。
此外,SQL 也有一些变种,就像中文有很多方言,比如:
微软的 SQL Server 使用 T-SQL;
Oracle 使用 PL/SQL;
微软 Access 版本的 SQL 被称为 JET SQL(本地格式)。
关系代数基于集合(无序的,无重复的)。SQL基于包(无序的,有重复)。
2 SQL History
SQL是关系数据库的声明式查询语言。它最初是在20世纪70年代作为IBM系统R项目。IBM最初将其称为“SEQUEL”(结构化英语查询语言)
在20世纪80年代被改为“SQL”(结构化查询语言)。
该语言由不同的命令类组成:
数据操作语言(DML): SELECT、INSERT、UPDATE和DELETE语句。
数据定义语言(DDL):表、索引、视图和其他对象的模式定义。
数据控制语言(DCL):安全、访问控制。
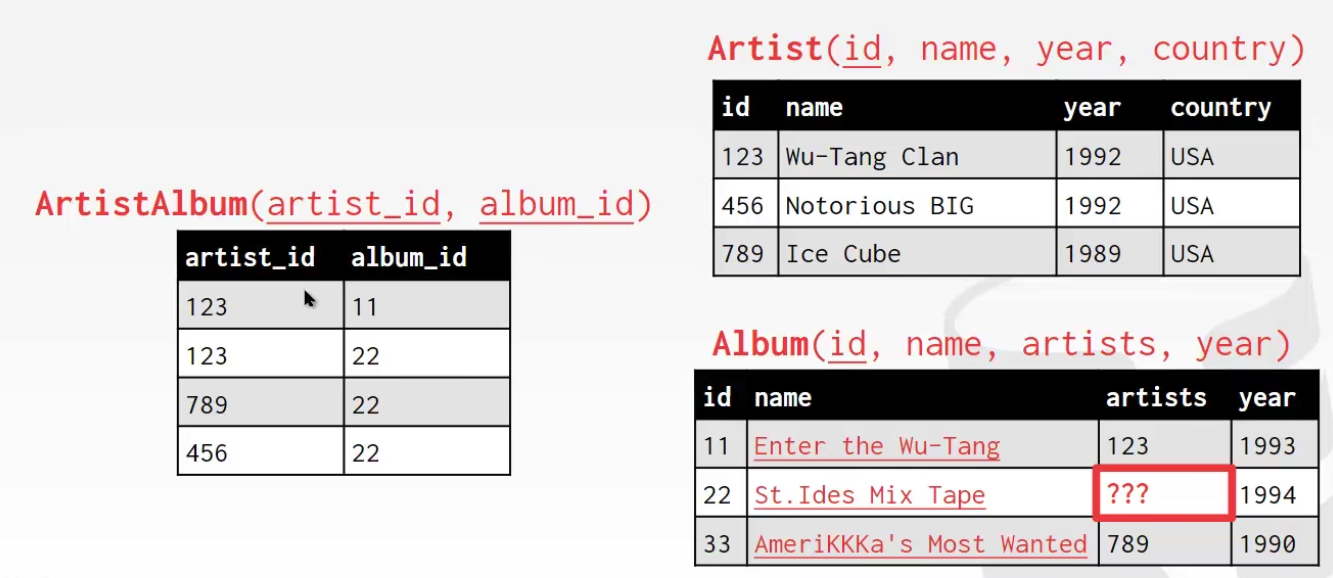
*EXAMPLE DATABASE
3 Joins
略
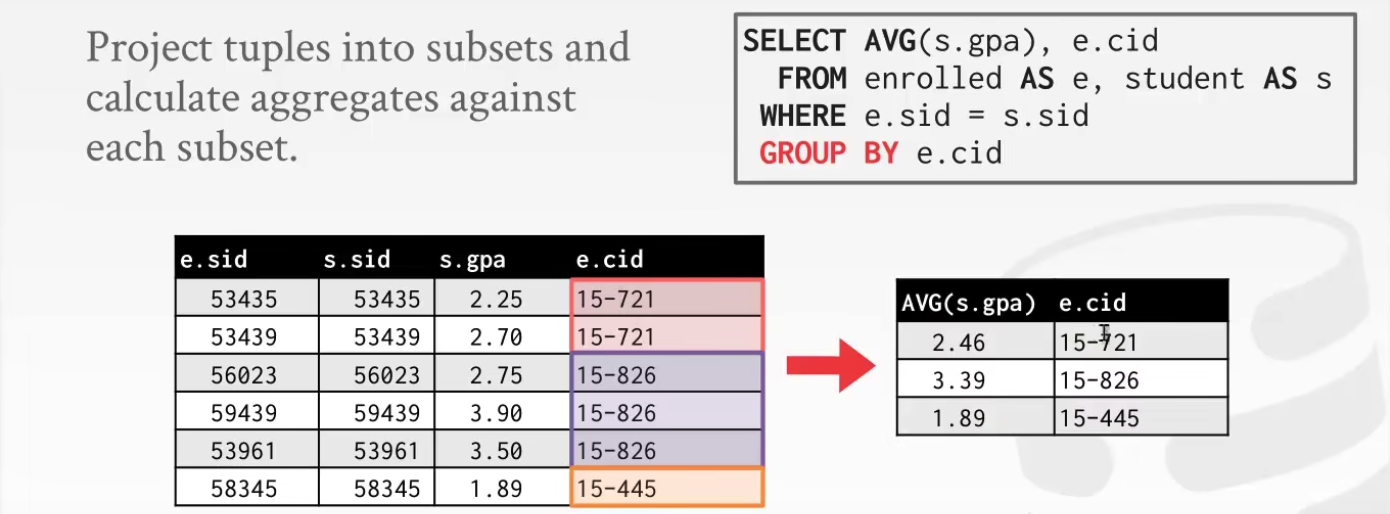
4 Aggregates


这里三种方式都可以
count(login) : 数一下login列不为NULL的个数


GROUP BY
HAVING

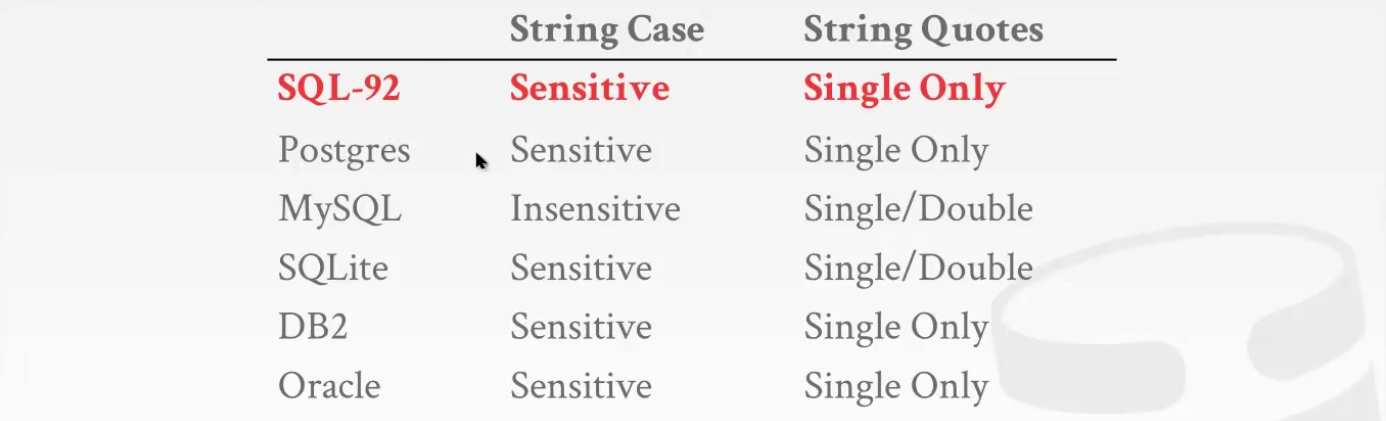
5 String Operations
大小写问题
LIKE

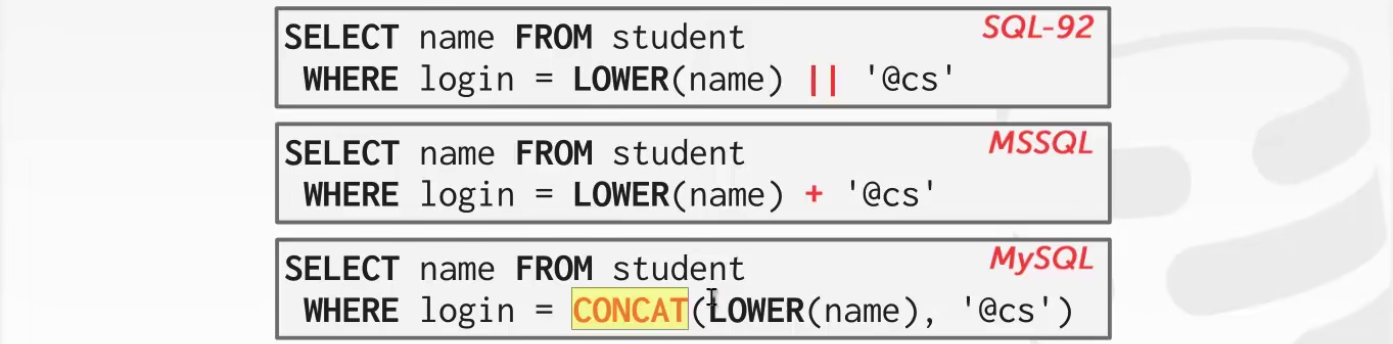
字符串操作

6 Date and Time
略
7 Output Redirection
使用输出建表

8 Output Control
ORDER BY

LIMIT[OFFSET]
控制输出的行数[从第几行开始] 
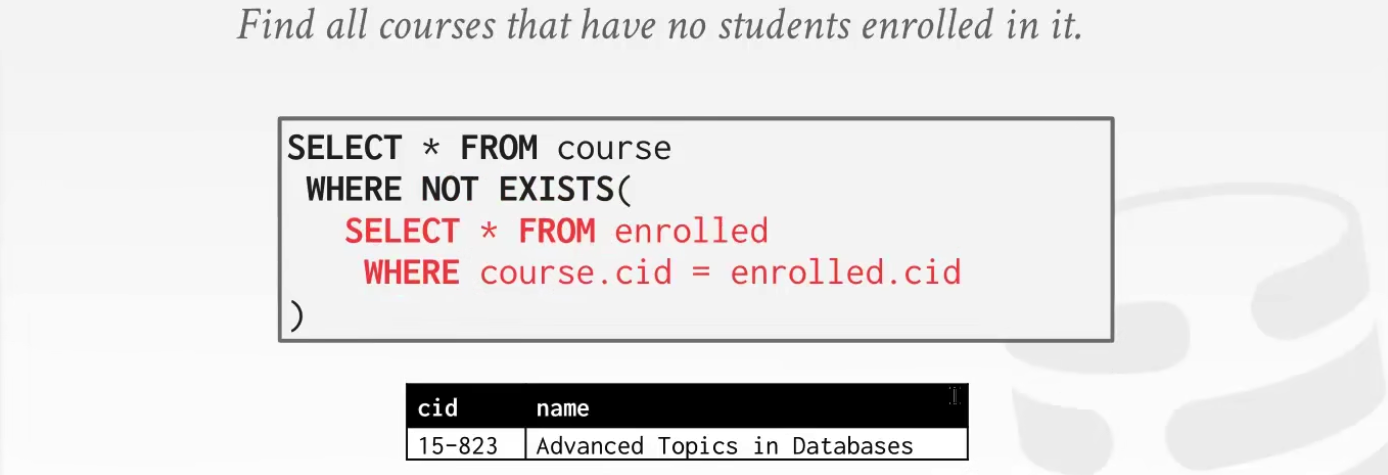
9 Nested Queries 子查询

完整语句


子查询与AGGREGATION

Example:
10 Window Functions 窗口函数

FUNC()可以是聚合函数或ROW_NUMBER()或RANK()
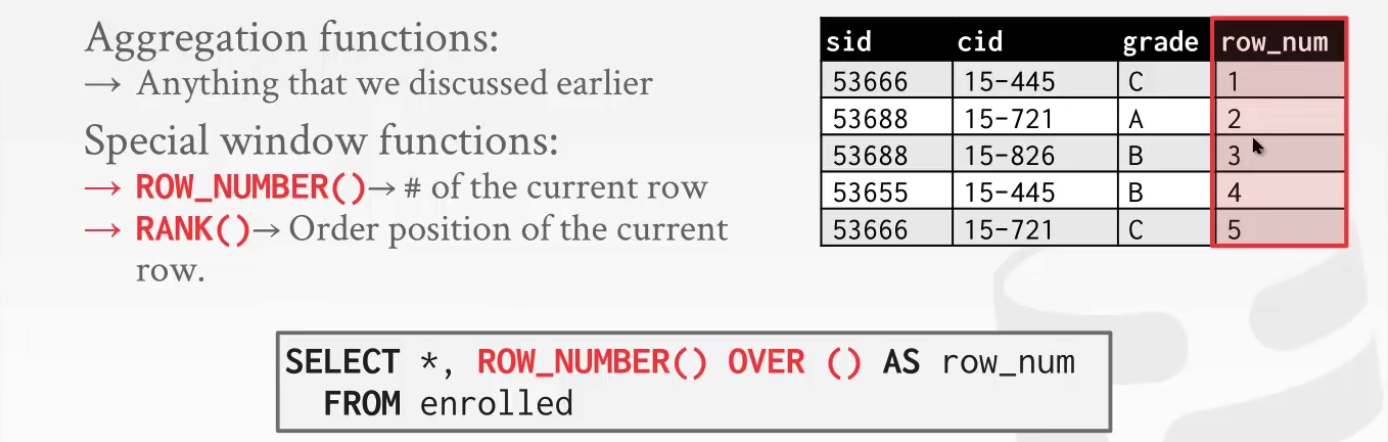
OVER()内可以用PARTITION BY 或者 ORDER BY

Example:

11 Common Table Expressions
视图,也相当于临时表

Example1:临时创建一个cteSource表, 有一列maxId, maxId是已经注册的最大的学号。然后内连接(等值连接)两表【笛卡尔积】…

Example2:

* 相关词汇
无
03 - Database Storage (Part I)
1 Storage
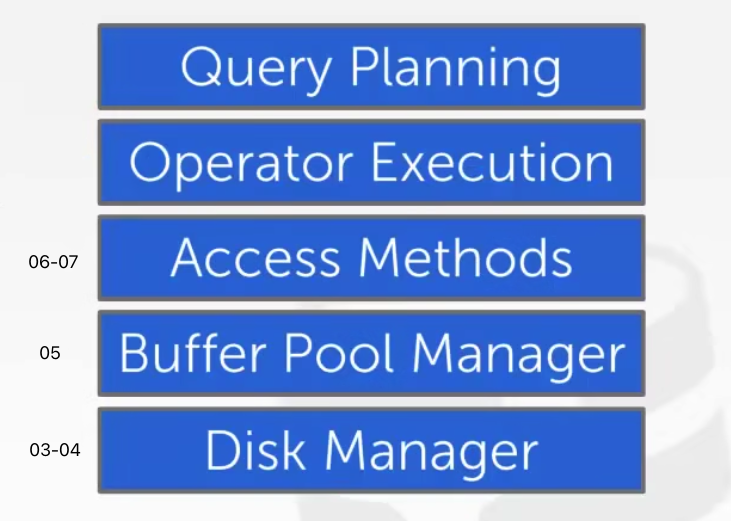
数据库组成部分由上而下:
Query Planning 查询规划
Operator Execution 操作执行
Access Methods 存取方法
Buffer Pool Manager 缓冲池管理器
Disk Manager 磁盘管理
DBMS假定主存储数据库位于非易失性磁盘上, 但一切操作性的行为都发生在内存中
存储等级(速度由慢到快,容量由大到小):
非易失性:Network Storage -> HDD(本地机械磁盘) -> SSD(固态硬盘) ->
易失性,但支持随机访问:DRAM(内存) -> CPU Caches(CPU高速缓存) -> CPU寄存器
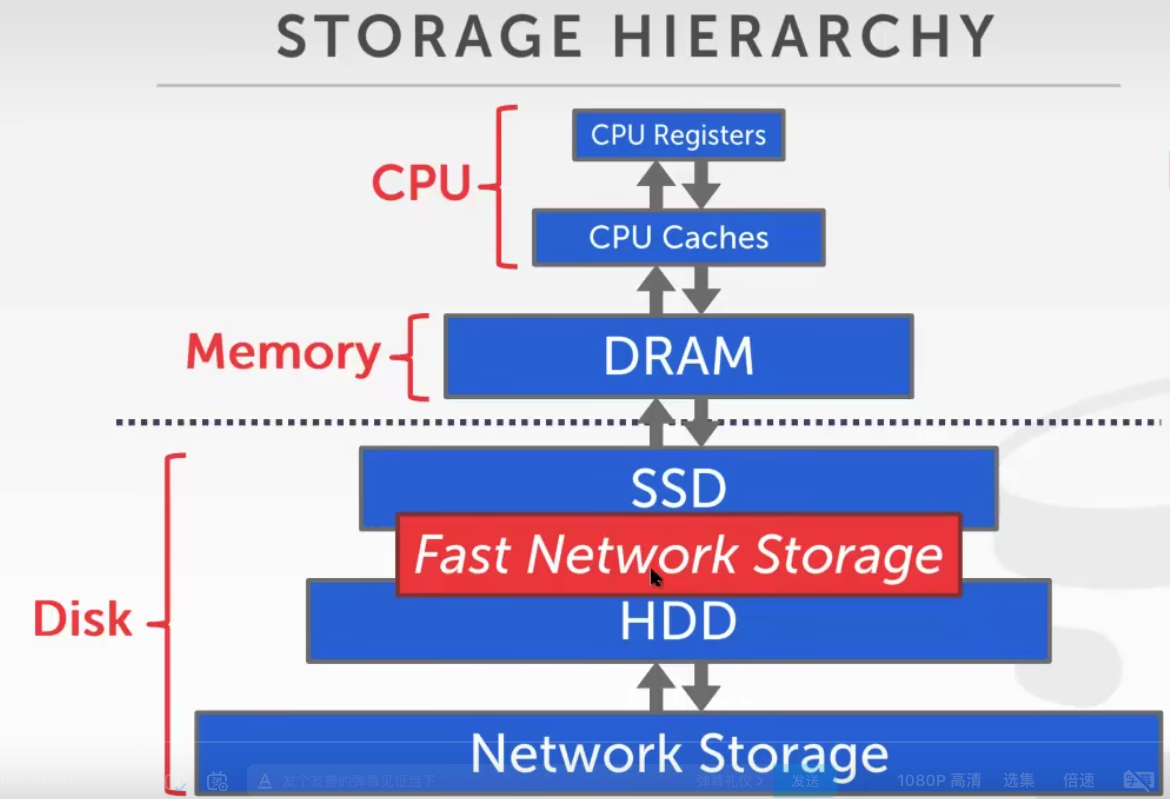
一个好的DBMS要实现的目标
允许DBMS管理超过可用的内存量。
读/写磁盘是昂贵的,所以必须如此小心地避开大型存储和性能下降。
对磁盘的随机访问通常要比顺序访问慢得多,所以DBMS想要最大化顺序访问
2 Disk-Oriented DBMS Overview
Disk-Oriented DBMS 即面向硬盘的数据库管理系统,数据最后都是要存到硬盘里的
Memory-Oriented DBMS 存在内存里比如Redis,断电就没了
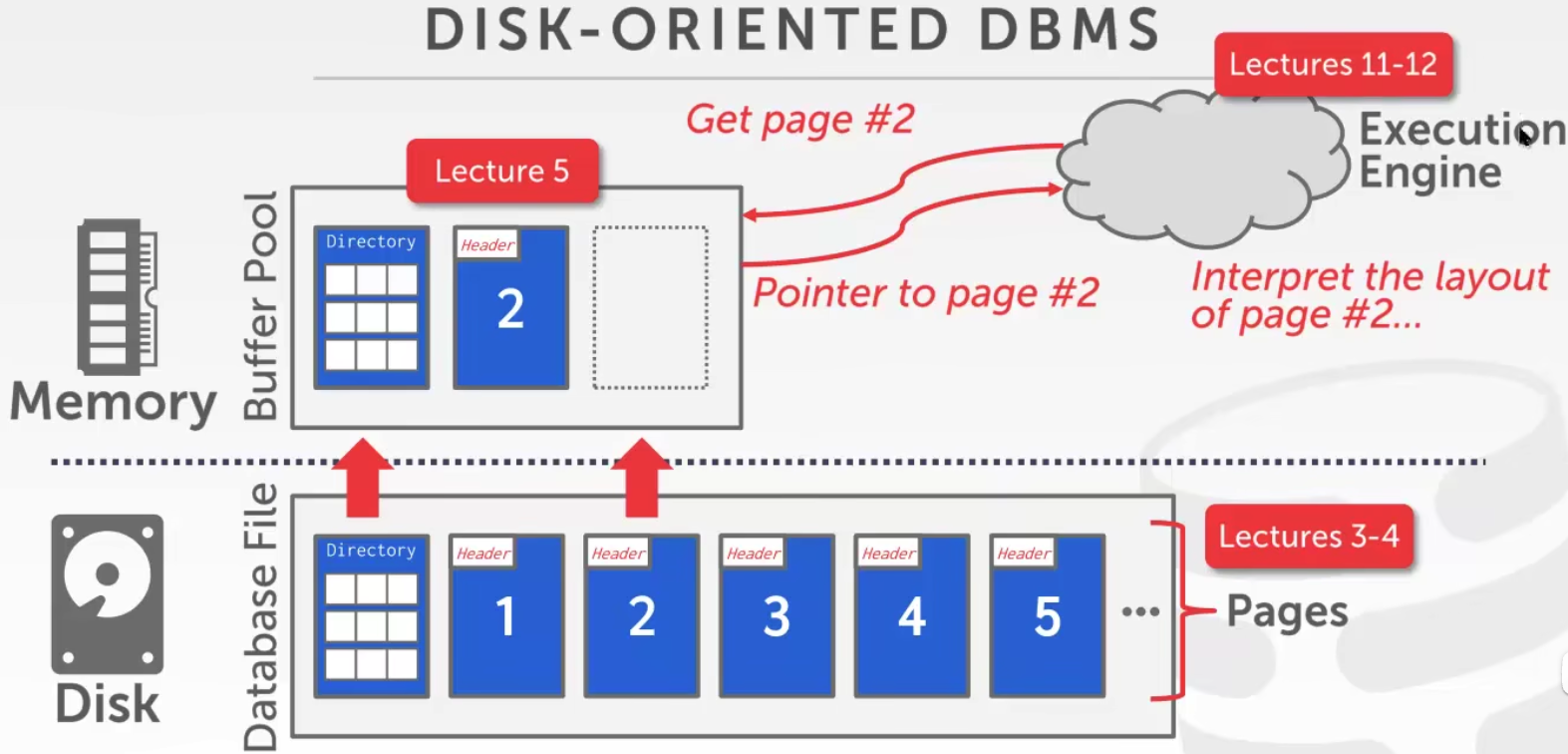
内存只给该DBMS分配那么多空间,但数据库文件在磁盘中很大
3 DBMS vs. OS
为什么不使用mmap方法?
因为一旦内存满了,OS不知道该替换哪一页了

不要将任何事交给OS!

4 数据库存储两大问题
DBMS怎么将数据库表达成在磁盘上的文件的格式?
DBMS如何管理内存并将数据写回磁盘?
5 解决第一个问题
File Storage
DBMS将数据库存储为一个或多个文件在磁盘上,通常以专有格式的内容,操作系统不知道这些文件
Database Pages


Database Heap


Heap File 的两种实现方案


Page Layout

Page中Data的组织架构

Tuple-oriented:slot相当于索引,slot有序,后面Tuple可以是乱的;Record id就等于pageid + slot
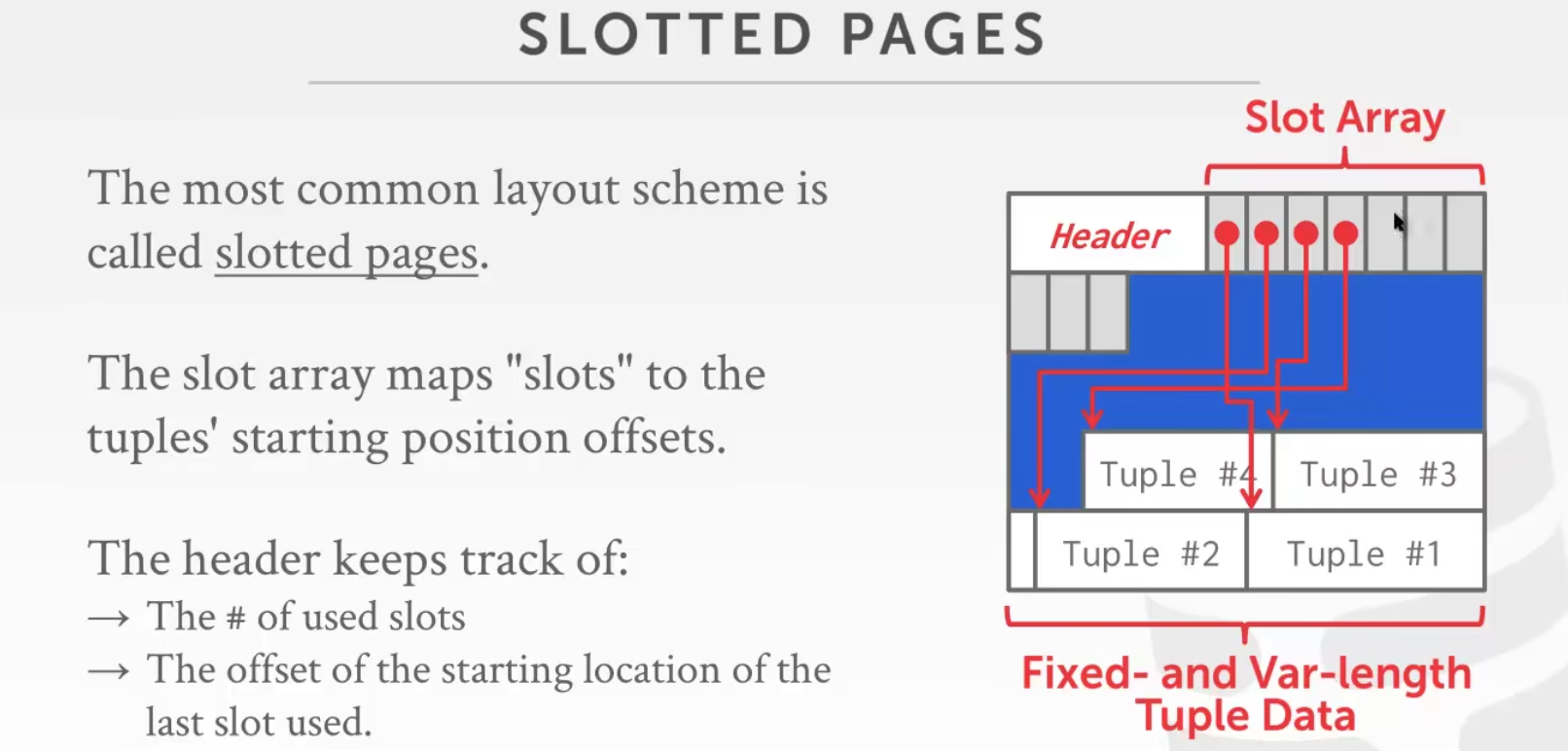
Log-Structered: 会定时压缩,方便更新,不方便读

Tuple Layout


6 总结
Database is organized in pages.
Different ways to track pages.(链表/ 目录)
Different ways to store pages.(Tuple形式【Slotted】/ Log形式【记录每次修改的信息】)
Different ways to store tuples.(就说了一种,见Tuple Layout)
04 - Database Storage (Part II)
1 Data Representation

系统目录:数据库的元数据都是一张张存在INFORMATION_SCHEMA中的表

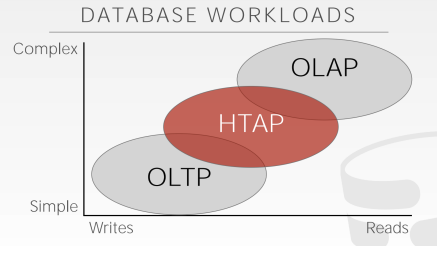
2 Workloads

OLTP专注于写, OLAP专注于读
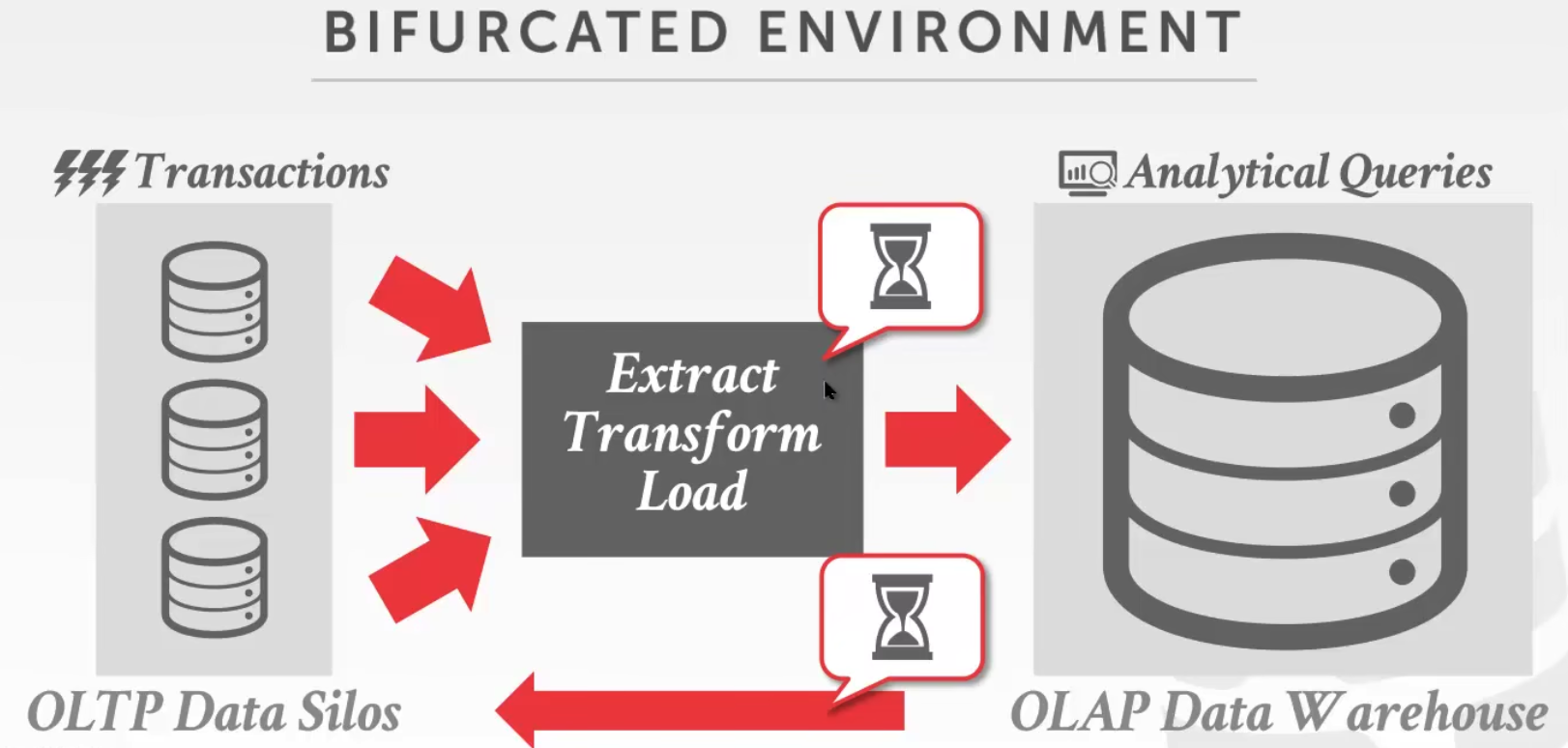
3 Storage Models
N-Ary Storage Model (NSM)
在n元存储模型中,DBMS将单个元组的所有属性连续地存储在单个页面中,因此NSM也被称为“行存储”。
这种方法非常适合OLTP工作负载,其中请求插入量大,事务往往只操作单个实体。它是理想的,因为它只需要一次获取就可以获得单个元组的所有属性。
优点:
快速插入、更新和删除
适合需要整个元组的查询。
缺点:
- 不适合扫描表的大部分(比如我们仅需要ID,却要一行行的扫描)或属性的子集。这是因为它会获取处理查询不需要的数据

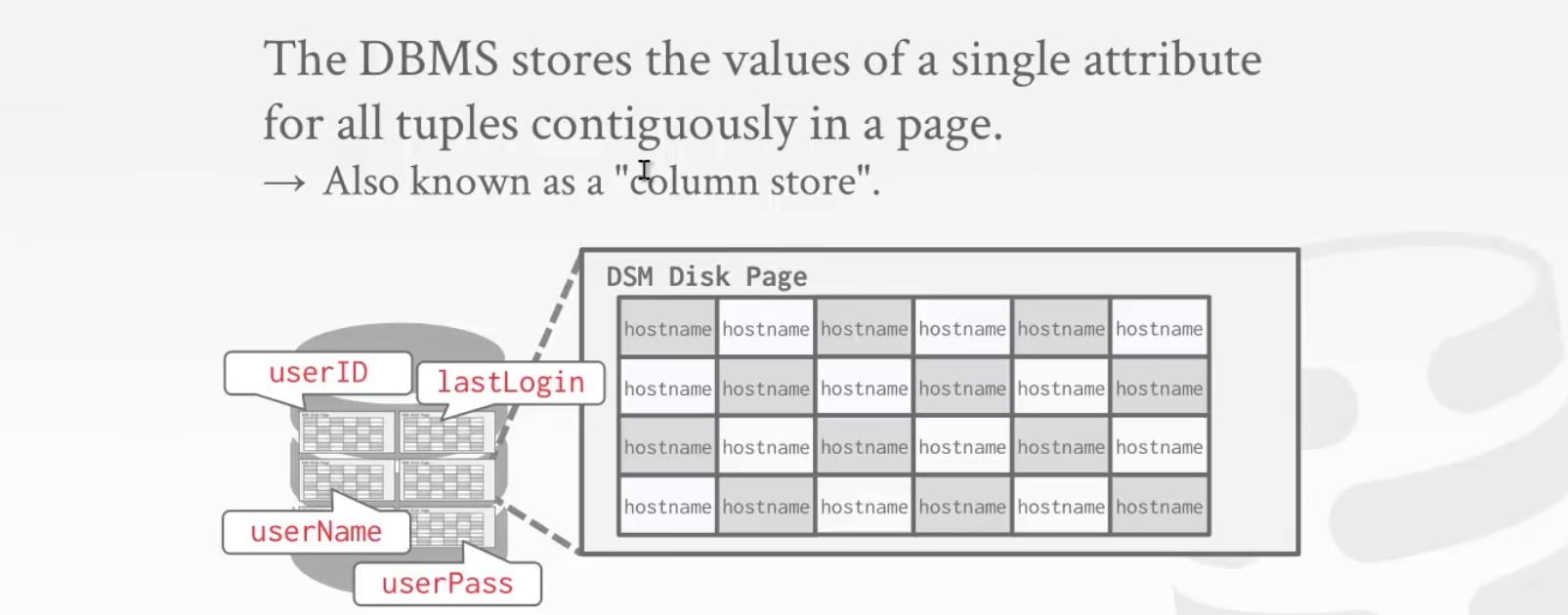
Decomposition Storage Model (DSM)
不同的页,存不同的列。因此,它也被称为“列存储”。
此模型非常适合OLAP工作负载许多只读查询在表的属性子集上执行大型扫描。
优点:
减少查询执行过程中浪费的工作量,因为DBMS只读取数据查询所需的。
支持更好的压缩,因为相同属性的所有值都是连续存储的。
缺点:
- 由于元组分裂/拼接,点查询、插入、更新和删除速度较慢。
05 - Buffer Pools
解决第二个问题:DBMS如何管理内存并将数据写回磁盘?
答:使用缓存池,读时要将附近的数据缓存下来,要写时写入缓存池,一定数量后统一写入磁盘
1 Introduction
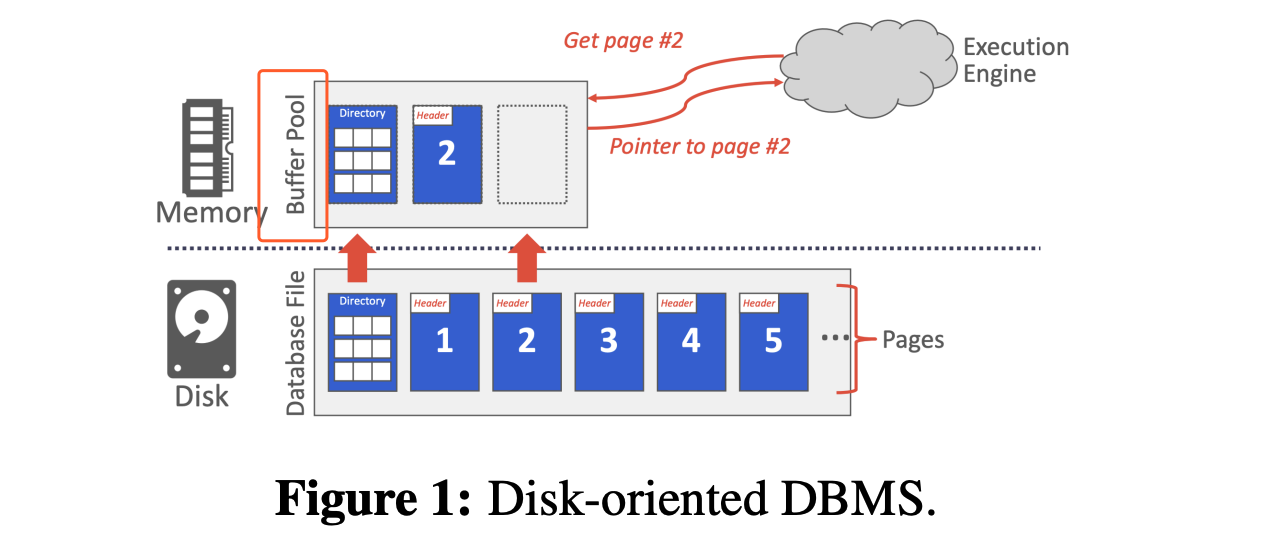
页表记录着该页是否被修改,引用数量

2 Locks vs. Latches
锁:锁是一种高级的逻辑原语,它保护数据库的内容(例如,元组、表、数据库)来自其他事务。事务将在其整个持续时间内持有一个锁。数据库系统可以向用户公开运行查询时持有哪些锁。锁需要能够回滚更改。
插销(Mutex):DBMS用于内部数据关键部分的低级保护原语结构(例如,哈希表,内存区域)。插销只在操作期间保持。插销不需要回滚
3 Page Directory vs. Page Table
Page Directory 是disk中记录DB File索引的, Page Table是内存中记录页表索引的
4 Buffer Pool
见上
5 Buffer Pool Optimizations
Multiple Buffer Pools


Pre-fetching
DBMS还可以根据查询计划预取页面进行优化。然后,当第一组页面是在处理过程中,第二个可以预取到缓冲池中。这种方法通常被DBMS使用按顺序访问多个页面。
Scan Sharing
共享扫描,可能出错
Buffer Pool Bypass
旁路缓存池:数据不进内存池,直接进内存,用完直接释放资源
6 OS Page Cache
不仅我们的数据库对文件有缓存,操作系统对于文件也有缓存。我们要绕过OS替我们操作的缓存。
7 Buffer Replacement Policies
当DBMS需要释放一个帧来为新页腾出空间时,它必须决定从缓冲池释放一个frame
替换策略的实现目标是改进正确性、准确性、速度和元数据开销
LRU算法
CLOCK算法
假设系统为某进程分配了五个内存块,并考虑到有以下页面号引用串:1,3,4,2,5,6,3,4,7
第一步:刚开始先将前五个页面装入五个物理块,这时五个页面均已被访问过,所以访问位置为1
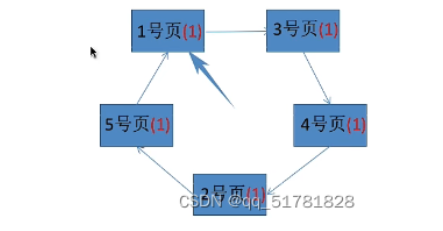
第二步:访问到6号页,需要换出一个页面。开始进行扫描,扫描一圈后,物理块中的五个页面的访问位全都置0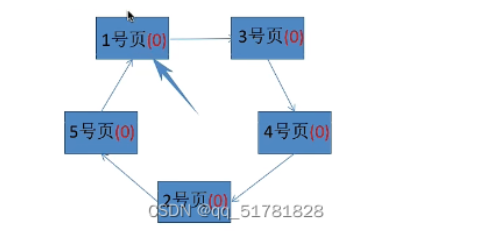
第三步:再进行第二轮扫描,1号页(0)淘汰,6号页进来并且将6号页访问位置为1,扫描页指针指向下一位
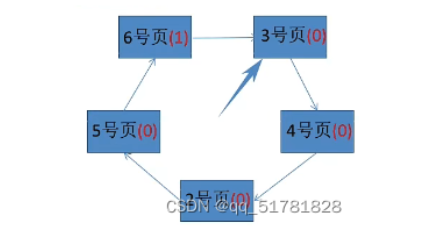
第四步:按照访问顺序,该访问3号页和4号页,所以将3号页和4号页的访问位置为1,扫描页指针不动(因为没有淘汰)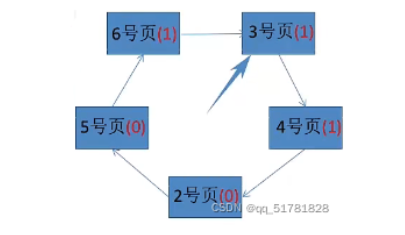
第五步:按照访问顺序,该访问7号页,7号页没有在物理块中,所以需要淘汰一个页面。扫描页指针从3号页开始扫描,3号页和4号页的访问位都是1,所以继续检查且将3号页和4号页的访问位置为0。2号页的访问位是0,淘汰。7号页进入物理块置为1,指针移动到5号页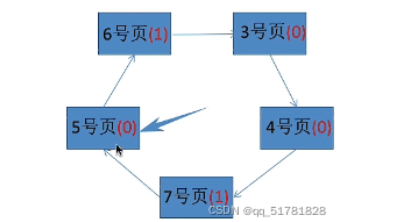
对LRU和CLOCK的改进
如果纯纯的顺序读写,那么LRU和CLOCK都多此一举并且每次还要检查最近未被使用的,耗时大
解决方法:
LRU-K:统计最近K次的LRU替换时间,及时调整替换策略
LOCALIZATION:若两条SQL语句都执行了,第二条执行时发现缓存池里#1他俩都要用,#2#3只有自己用,那么替换时就优先替换掉#1
PRIORITY HINTS:执行器采用一些机器学习/深度学习算法告知Buffer Pool Manager 某个帧的重要程度,让它不要轻易替换
Dirty Pages算法
若该页没脏(没被修改),则按正常替换策略替换。
若用户修改了该frame,则系统要维护一个修改日志,以防断电。等修改了一定次数后,统一写回内存。写回内存后要设置脏位为非脏
8 Other Memory Pools
The DBMS needs memory for things other than just tuples and indexes. These other memory pools may not always backed by disk depending on implementation.
- Sorting + Join Buffers
- Query Caches
- Maintenance Buffers
- Log Buffers
- Dictionary Caches
06 - Hash Tables

1 Data Structures
DBMS对系统内部的许多不同部分使用不同的数据结构。包括:
内部元数据: 这是跟踪关于数据库和系统的信息的数据状态。例如:页表,页目录
核心数据存储: 数据结构被用作数据库元组的基础存储。比如Redis是KV类型的数据库,核心类型就是哈希表
临时数据结构:DBMS可以在处理数据时动态地构建数据结构查询以加速执行(例如,连接的哈希表)。
表索引: 辅助数据结构可以用来更容易地查找特定的元组。(使用哈希表/B+树)
在为DBMS实现数据结构时,有两个主要的设计决策需要考虑:
数据组织: 我们需要弄清楚如何布局内存以及在里面存储什么信息数据结构以支持高效的访问
并发性: 我们还需要考虑如何使多个线程能够访问数据结构不会造成任何问题
2 Hash Table

A hash table implementation is comprised of two parts: 哈希函数、哈希冲突
哈希冲突
(1)闭散列(开放地址法):【线性探测法、二次探测法】
当我们遇到哈希冲突的时候,从当前位置的下一个开始找空位,碰到空位存进去。这种方法好存放但是难查找更加难删除

(2)开散列:【拉链法】
当我们遇到哈希冲突的时候,将当前位置的元素变成一个链表或者树
哈希冲突较严重时
(1)拓容:将原来的数组拓容为更大的数组,再将元素重新取模放入新的数组中
(2)当链表长度到达6的时候,将链表变成树
07 - Tree Indexes
1 B-Tree famliy

2 B-Tree
这里的 B 是 Balance(平衡)的缩写。它是一种多路的平衡搜索树。
它跟普通的平衡二叉树的不同是,B树的每个节点可以存储多个数据,而且每个节点不止有两个子节点,最多可以有上千个子节点。
B树中每个节点都存放着索引和数据,数据遍布整个树结构,搜索可能在非叶子节点结束,最好的情况是O(1)。
一般一棵 B 树的高度在 3 层左右,3 层就可满足百万级别的数据量
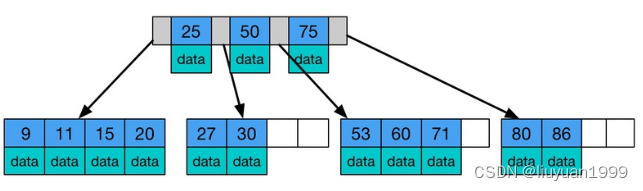
- B树 每个节点都存储了一定的范围区间,区间更多的情况下,搜索也就更快。比如普通的二叉树对于 1~ 100 的索引值,首先分为 1~ 50 和51~ 100 两部分。而 B树可以分为四个区间 1~ 25, 26~ 50, 51~ 75, 76~ 100 。甚至可以划分为更多区间,这样一次就能排除四分之三的数据
3 B+Tree
B+树是B树的一种变种,它与 B树 的 区别 是:
叶子节点保存了完整的索引和数据,而非叶子节点只保存索引值,因此它的查询时间固定为 log(n).
叶子节点中有指向下一个叶子节点的指针,叶子节点类似于一个单链表
正因为叶子节点保存了完整的数据以及有指针作为连接,B+树可以增加了区间访问性,提高了范围查询,而B树的范围查询相对较差
B+树更适合外部存储。因为它的非叶子节点不存储数据,只保存索引。
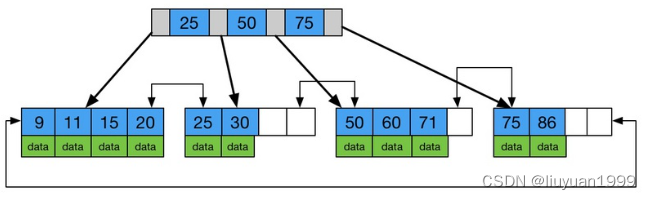
B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n; 而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)
4 红黑树
对于二叉搜索树,如果插入的数据是随机的,那么它就是接近平衡的二叉树,平衡的二叉树,它的操作效率(查询,插入,删除)效率较高,时间复杂度是O(logN)。但是可能会出现一种极端的情况,那就是插入的数据是有序的(递增或者递减),那么所有的节点都会在根节点的右侧或左侧,此时,二叉搜索树就变为了一个链表,它的操作效率就降低了,时间复杂度为O(N),所以可以认为二叉搜索树的时间复杂度介于O(logN)和O(N)之间,视情况而定。
那么为了应对这种极端情况,红黑树就出现了,它是具备了某些特性的二叉搜索树,能解决非平衡树问题,红黑树是一种接近平衡的二叉树(说它是接近平衡因为它并没有像AVL树的平衡因子的概念,它只是靠着满足红黑节点的5条性质来维持一种接近平衡的结构,进而提升整体的性能,并没有严格的卡定某个平衡因子来维持绝对平衡)
红黑树性质
首先,红黑树是一个二叉搜索树,它在每个节点增加了一个存储位记录节点的颜色,可以是RED,也可以是BLACK;通过任意一条从根到叶子简单路径上颜色的约束,红黑树保证最长路径不超过最短路径的二倍,因而近似平衡(最短路径就是全黑节点,最长路径就是一个红节点一个黑节点,当从根节点到叶子节点的路径上黑色节点相同时,最长路径刚好是最短路径的两倍)。它同时满足以下特性:
- 节点是红色或黑色
- 根是黑色
- ⭐️叶节点(null节点) 都是黑色,null节点的父节点在红黑树里不将其看作叶子节点
- 红色节点的子节点和父节点都是黑色,且从根节点到叶子节点的所有路径上不能有 2 个连续的红色节点
- 从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
判断题:
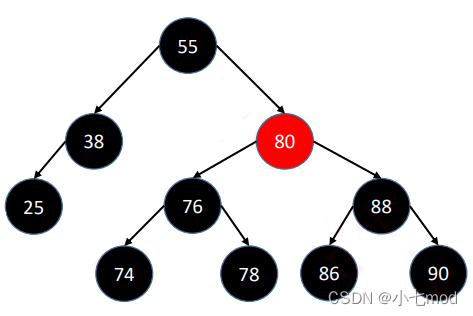
上面这棵树首先很容易就能知道是满足性质1-4条的,关键在于第5条性质,可能乍一看好像也是符合第5条的,但实际就会陷入一个误区,直接将图上的最后一层的节点看作叶子节点,这样看的话每一条从根节点到叶子结点的路径确实都经过了3个黑节点。
但实际上,在红黑树中真正被定义为叶子结点的,是那些空节点,如下:
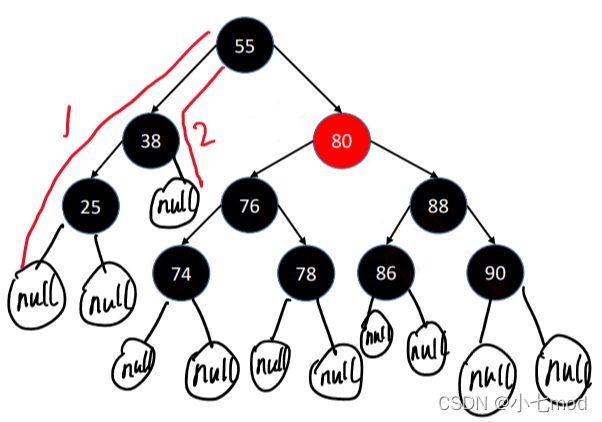
这样一来,路径1有4个黑色节点(算上空节点),路径2只有3个黑色节点,这样性质5就不满足了,所以不是红黑树
红黑树效率
红黑树的查找,插入和删除操作,时间复杂度都是O(logN)
查找操作时,它和普通的相对平衡的二叉搜索树的效率相同,都是通过相同的方式来查找的,没有用到红黑树特有的特性。
**但若插入的是有序数据,那么红黑树的查询效率就比二叉搜索树要高了,因为此时二叉搜索树不是平衡树,它的时间复杂度O(N)**。
插入和删除操作时,由于红黑树的每次操作平均要旋转一次和变换颜色,所以它比普通的二叉搜索树效率要低一点,不过时间复杂度仍然是O(logN)。总之,红黑树的优点就是对有序数据的查询操作不会慢到O(logN)的时间复杂度。
红黑树与AVL树相比较
- AVL树的时间复杂度虽然优于红黑树,但是对于现在的计算机,cpu太快,可以忽略性能差异
- 红黑树的插入删除比AVL树更便于控制操作
- 红黑树整体性能略优于AVL树(红黑树旋转情况少于AVL树)
08 - Index Concurrency Control
对索引的并发控制问题【表项索引: 使用辅助数据结构(哈希表/B+树)可以用来更容易地查找特定的元组】