C++语言基础
简述下C++语言的特点
C++在C语言基础上引入了面对对象(三大特性:封装、继承、多态)的机制,同时也兼容C语言
C++运行效率高,仅比汇编语言慢10%~20%
C++更加安全, 增加了const常量、引用、四类cast转换(static_cast、dynamic_cast、const_cast、reinterpret_cast)、智能指针、try catch
dynamic_cast<type>(a) // 用于类之间的转型,运行期间会做检查,转型失败会返回0并抛出bad_cast.
static_cast<type>(a) // 这个其实和传统的C语言的强制转换是一样的,它不会做任何检查,如果转型失败就会发生未知错误。
const_cast<type>(a) // 把a从const型转为非const型,常用于函数重载
reinterpret_cast<type>(a) // 可进行任意转型,把a中的内存按type的方式来解读,需要程序员保证转换的正确性。C++可复用性高,C++引入了模板的概念,后面在此基础上,实现了方便开发的标准模板库STL(Standard Template Library)
C++是不断在发展的语言。C++后续版本更是发展了不少新特性,如C++11中引入了nullptr、auto变量、Lambda函数、右值引用、智能指针
说说C语言和C++的区别
C++面对对象;C是面对过程
C是C++的子集,但是C++又有很多新特性,如引用、智能指针、auto变量等
C不安全,如指针使用的潜在危险、强制转换的不确定性、内存泄露等。而C++更安全,如const常量、引用、cast转换、智能指针、try catch
C++可复用性高,C++引入了模板的概念,实现了STL。相对于C语言的函数库更灵活、更通用。
说说指针和引用的区别
- 指针用于保存地址类型的数据,而引用可以看成是变量的别名。
- 引用不可以为空,当被创建的时候必须初始化,而指针变量可以是空值,在任何时候初始化
- 指针可以有多级,但引用只能是一级
- 引用使用时无需解引用(*),指针需要解引用
- 指针的值在初始化后可以指向其它的存储单元,而引用在进行初始化后就不会再改变了
- sizeof 引用得到的是所指向的变量(对象)的大小,而 sizeof 指针得到的是指针变量本身的大小
- 指针作为函数参数传递时传递的是指针变量的值,而引用作为函数参数传递时传的是实参本身,不是副本
- 指针和引用进行++运算意义不一样
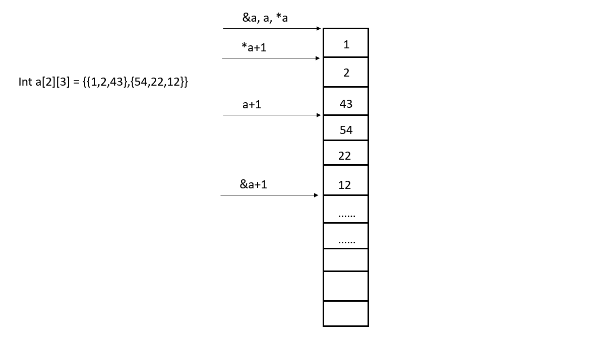
说说使用指针需要注意什么
- 定义指针时,先初始化为NULL
- 用malloc或new申请内存之后,应该立即检查指针值是否不为NULL。防止使用空指针
- 用free或delete释放了内存之后,立即将指针设置为NULL,防止“野指针”
- 不要忘记为数组和动态内存赋初值
- 避免数字或指针的下标越界,特别要当心发生“多1”或者“少1”操作
- 动态内存的申请与释放必须配对,防止内存泄漏
什么是野指针,怎么产生的,如何避免?
概念:野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
产生原因:释放内存后指针不及时置空(野指针),依然指向了该内存,那么可能出现非法访问的错误。这些我们都要注意避免
char *p = (char *)malloc(sizeof(char)*100);
strcpy(p, "Douya");
free(p);//p所指向的内存被释放,但是p所指的地址仍然不变
...
if (p != NULL){//没有起到防错作用
strcpy(p, "hello, Douya!");//出错
}避免办法:
(1)初始化置NULL 空
(2)申请内存后判空 不空
(3)指针释放后置NULL 空
(4)使用智能指针
int *p = NULL; //初始化置NULL
p = (int *)malloc(sizeof(int)*n); //申请n个int内存空间
assert(p != NULL); //判空,防错设计
p = (int *) realloc(p, 25);//重新分配内存, p 所指向的内存块会被释放并分配一个新的内存地址
free(p);
p = NULL; //释放后置空
int *p1 = NULL; //初始化置NULL
p1 = (int *)calloc(n, sizeof(int)); //申请n个int内存空间同时初始化为0
assert(p1 != NULL); //判空,防错设计
free(p1);
p1 = NULL; //释放后置空
int *p2 = NULL; //初始化置NULL
p2 = new int[n]; //申请n个int内存空间
assert(p2 != NULL); //判空,防错设计
delete []p2;
p2 = nullptr; //释放后置空
说说运算符i++和++i的区别
效率不同:后置++ 执行速度比前置的慢
i++ 不能作为左值,而++i 可以
int i = 0;
int* p1 = &(++i);//正确
// int* p2 = &(i++);//错误
++i = 1;//正确
// i++ = 1;//错误
final关键字
// C++11中允许将类标记为final,方法时直接在类名称后面使用关键字final,如此,意味着继承该类会导致编译错误 |
// C++中还允许将方法标记为final,这意味着无法再子类中重写该方法。这时final关键字至于方法参数列表后面 |
如何让两个类互相引用
如果两个类相互引用,需要使用前置声明(forward declaration)来解决循环依赖问题。前置声明可以让编译器知道类的存在,而不需要提供完整的类定义
class B; // 前置声明 |
C++内存
简述一下堆和栈的区别
- 堆栈空间分配不同。栈由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等;堆一般由程序员分配释放。
- 堆栈缓存方式不同。栈使用的是一级缓存;堆则是存放在二级缓存中,速度要慢些。
- 堆栈数据结构不同。堆类似数组结构;栈类似栈结构,先进后出。
C++面向对象
简述一下面向对象的三大特征
面向对象的三大特征是封装、继承、多态。
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行 交互。不想给别人看到的,我们使用protected/private把成员封装起来。开放一些共有的成员函数对成员合理的访问。
继承:可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
继承方式 private继承 protected继承 public继承 基类的private成员 不可见 不可见 不可见 基类的protected成员 变为private成员 仍为protected成员 仍为protected成员 基类的public成员 变为private成员 变为protected成员 仍为public成员 多态:用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。
成员访问限定符
| 关键字 | 权限 |
|---|---|
| public | 可以被任意实体访问 |
| protected | 只允许子类及本类的成员函数访问 |
| private | 只允许本类的成员函数访问 |
拷贝构造函数的参数是什么传递方式,为什么
拷贝构造函数的参数必须使用引用传递
如果拷贝构造函数中的参数不是一个引用,即形如CClass(const CClass c_class)或CClass(const CClass* c_class),那么就相当于采用了传值的方式(pass-by-value),而传值的方式会调用该类的拷贝构造函数,从而造成无穷递归地调用拷贝构造函数。因此拷贝构造函数的参数必须是一个引用
拷贝构造和移动构造的不同
拷贝和移动是不同的操作:从A拷贝到B意味着,B分配了新内存,A的整个内容被拷贝到为B分配的新内存上。 而从A移动到B意味着分配给A的内存转移给了B,没有分配新的内存,它仅仅包含简单地拷贝指针
说说 C++ 类对象的初始化顺序,有多重继承的情况呢
父类构造函数 –> 成员类对象构造函数 –> 自身构造函数
其中成员变量的初始化与声明顺序有关,构造函数的调用顺序是类派生列表中的顺序
析构顺序和构造顺序相反
仿函数了解吗?有什么作用
- 仿函数(functor)又称为函数对象(function object)是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载operator()运算符,举个例子:
class Func{ |
- 仿函数既能像普通函数一样传入给定数量的参数,还能存储或者处理更多我们需要的有用信息。我们可以举个例子:假设有一个vector
,你的任务是统计长度小于5的string的个数,如果使用函数的话,你的代码可能长成这样:
bool LengthIsLessThanFive(const string& str) { |
C++STL
说说 map和 unordered_map 的区别
map实现机理
map内部实现了一个红黑树(红黑树是非严格平衡的二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树有自动排序的功能,因此map内部所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找、删除、添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照BST存储的,使用中序遍历可将键值按照从小到大遍历出来
unordered_map实现机理
unordered_map内部实现了一个哈希表(也叫散列表),通过把关键码值映射到Hash表中一个位置来访问记录,查找时间复杂度可达O(1),其中在海量数据处理中有着广泛应用。因此,元素的排列顺序是无序的
说说 vector 和 list 的区别, 分别适用于什么场景?
vector:一维数组
特点:在堆中分配内存,动态数组,元素连续存放,有保留内存,如果减少大小后内存也不会释放
扩容方式:
- 申请空间 2. 拷贝数据 3. 释放旧空间 因为 vector 扩容需要申请新的空间,所以扩容以后它的内存地址会发生改变
(1)当数组大小不够容纳新增元素时,开辟更大的内存空间,把旧空间上的数据复制过来,然后在新空间中继续增加
(2)新的更大的内存空间,一般是当前空间的1.5倍或者2倍,这个1.5或者2被称为扩容因子,不同系统实现扩容因子也不同
优点:和数组类似开辟一段连续的空间,并且支持随机访问,所以它的查找效率高其时间复杂度O(1)
缺点:由于开辟一段连续的空间, 所以插入删除会需要对数据进行移动比较麻烦, 时间复杂度O(n), 另外当空间不足时还需要进行扩容
list:双向链表
特点:元素在堆中存放,每个元素都是存放在一块内存中,它的内存空间可以是不连续的,通过指针来进行数据的访问
优点:底层实现是循环双链表,当对大量数据进行插入删除时,其时间复杂度O(1)
缺点:底层没有连续的空间,只能通过指针来访问,所以查找数据需要遍历其时间复杂度O(n), 没有提供[]操作符的重载
简述 STL 中的 map 的实现原理
map是关联式容器,它们的底层容器都是红黑树。map 的所有元素都是 pair,同时拥有实值(value)和键值(key)。pair 的第一元素被视为键值,第二元素被视为实值。所有元素都会根据元素的键值自动被排序。不允许键值重复。
map的特性如下
(1)map以RBTree作为底层容器;
(2)所有元素都是键+值存在;
(3)不允许键重复;
(4)所有元素是通过键进行自动排序的;
(5)map的键是不能修改的,但是其键对应的值是可以修改的。
说下 map 和 set 有什么区别, 分别是怎么实现的?
同:
- 都是一种关联式容器
- 以RBTree作为底层容器
- 不允许出现键值重复
- 所有的元素都会被自动排序
不同:
set的元素的只有key没有value,value就是key
不能通过迭代器来改变set的值,因为set的值就是键,set的迭代器是const的
map中所有元素都是键+值存在
map的键是不能修改的,但是其键对应的值是可以修改的
说说 push_back 和 emplace_back 的区别
如果要将一个临时变量push到容器的末尾,push_back()需要先构造临时对象,再将这个对象拷贝到容器的末尾,而emplace_back()则直接在容器的末尾构造对象,这样就省去了拷贝的过程。
操作系统
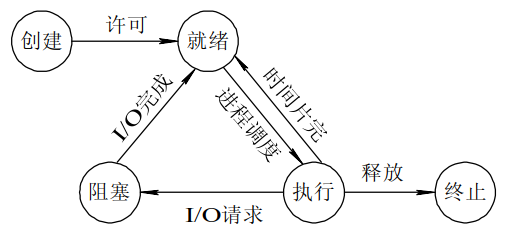
进程五状态模型