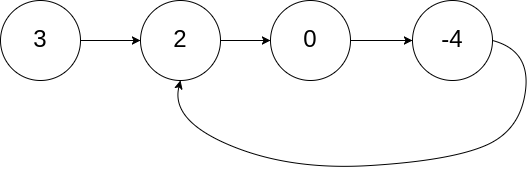
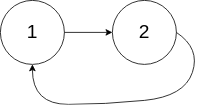
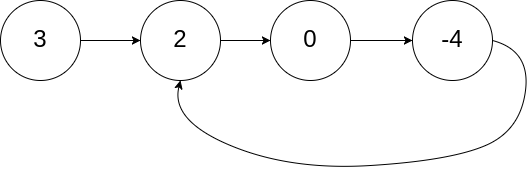
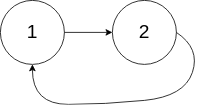
classSolution { public: boolhasCycle(ListNode *head){ if(!head) returnfalse; ListNode* fast = head; ListNode* slow = head; // 不能只判断 slow -> next && fast -> next -> next 因为 如果 fast -> next 就为null的话,根本就没有 fast -> next -> next 这个东西 while(slow -> next && fast -> next && fast -> next -> next){ slow = slow -> next; fast = fast -> next -> next; if(slow == fast) returntrue; } returnfalse; } };
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。 — 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
C++
// 先统一位置,再同时往后遍历 classSolution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB){ ListNode* p = headA; int lenA = 0; ListNode* q = headB; int lenB = 0; while(p){ lenA ++; p = p -> next; } while(q){ lenB ++; q = q -> next; }
classSolution { public: ListNode* removeNthFromEnd(ListNode* head, int n){ ListNode* dummy = newListNode(0, head); ListNode* pre = dummy; ListNode* cur = dummy; while(n -- > 0){ cur = cur -> next; } while(cur -> next){ cur = cur -> next; pre = pre -> next; } pre -> next = pre -> next -> next; return dummy -> next; } };
递归
classSolution { public: int cur = 0; ListNode* removeNthFromEnd(ListNode* head, int n){ if(!head) returnnullptr; head -> next = removeNthFromEnd(head -> next, n); cur ++; // 不能传参数 n-- 递归,因为是倒数统计,从最后一个节点向前return if(n == cur) return head -> next; return head; } };
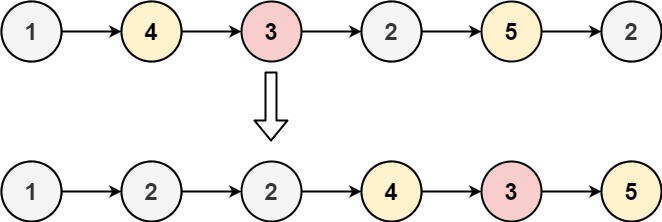
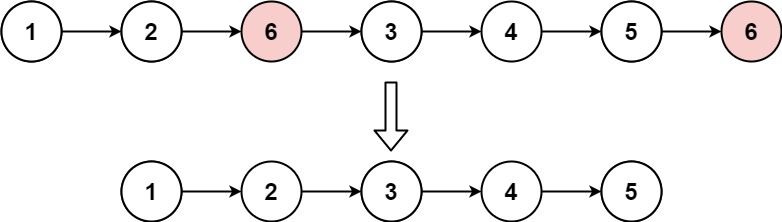
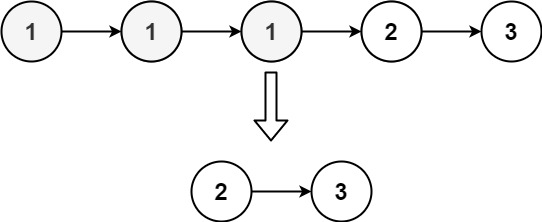
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
输入:head = [1,1,2] 输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3] 输出:[1,2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
C++
非递归版
classSolution { public: ListNode* deleteDuplicates(ListNode* head){ if(!head) returnnullptr; ListNode* dummy = newListNode(-101, head); ListNode* pre = dummy; ListNode* cur = head; while(cur){ while(cur && cur -> val == pre -> val){ pre -> next = cur -> next; cur = pre -> next; } if(!cur) break; cur = cur -> next; pre = pre -> next; } return dummy -> next; } };
递归版
classSolution { public: int pre = -101; ListNode* deleteDuplicates(ListNode* head){ if(!head) returnnullptr; if(head -> val == pre) returndeleteDuplicates(head -> next); pre = head -> val; head -> next = deleteDuplicates(head -> next); return head; } };
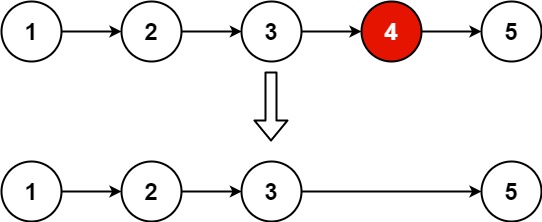
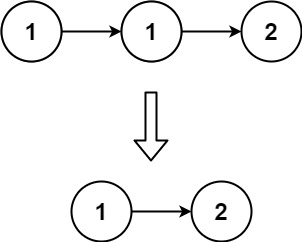
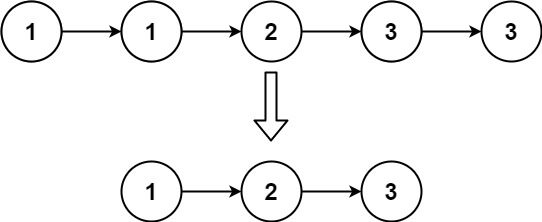
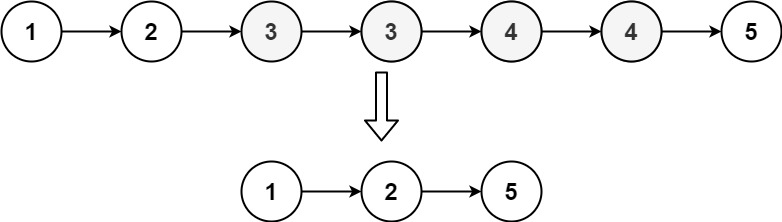
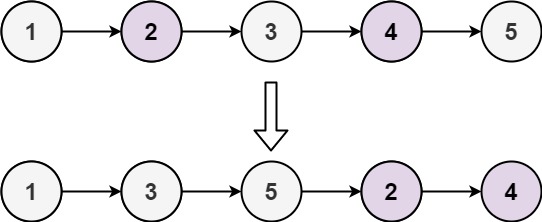
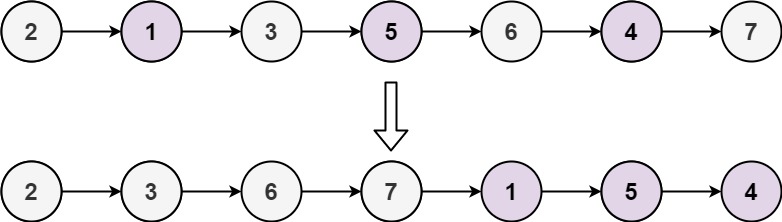
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]
示例 2:
输入:head = [1,1,1,2,3] 输出:[2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
C++
非递归
classSolution { public: ListNode* deleteDuplicates(ListNode* head){ if(!head) returnnullptr; ListNode* dummy = newListNode(-101, head); ListNode* cur = dummy; ListNode* pre = dummy; while(cur && cur -> next){ if(cur -> next ->val == cur -> val){ int val = cur -> val; while(cur && cur -> val == val) cur = cur -> next; pre -> next = cur; } else{ pre = cur; cur = cur -> next; } } return dummy -> next; } };
递归
head 后面有值而且和 head 的值相等,那么就找到第一个不相等的节点为止,然后对它去递归
classSolution { public: ListNode* deleteDuplicates(ListNode* head){ if(!head) return head; if(head -> next && head -> val == head -> next -> val){ while(head -> next && head -> val == head -> next -> val){ head = head -> next; } returndeleteDuplicates(head -> next); } head -> next = deleteDuplicates(head -> next); return head; } };