Project 1 : BUFFER POOL 在本实验中,需要在存储管理器中实现缓冲池。缓冲池负责将物理页面从磁盘中读入内存、或从内存中写回磁盘,使得DBMS可以支持大于内存大小的存储容量。并且,缓冲池应当是用户透明且线程安全的。
Task1 : LRU REPLACEMENT POLICY 本部分中需要实现缓冲池中的LRUReplacer,该组件的功能是跟踪缓冲池内的页面使用情况,并在缓冲池容量不足时驱除缓冲池中最近最少使用的页面。其应当具备如下接口:
Victim(frame_id_t*):驱逐缓冲池中最近最少使用的页面,并将其内容存储在输入参数中。当LRUReplacer为空时返回False,否则返回True;Pin(frame_id_t):当缓冲池中的页面被用户访问时,该方法被调用使得该页面从LRUReplacer中驱逐,以使得该页面固定在缓存池中;Unpin(frame_id_t):当缓冲池的页面被所有用户使用完毕时,该方法被调用使得该页面被添加在LRUReplacer,使得该页面可以被缓冲池驱逐;Size():返回LRUReplacer中页面的数目;
class LRUReplacer : public Replacer { public : explicit LRUReplacer (size_t num_pages) ~LRUReplacer () override ; bool Victim (frame_id_t *frame_id) override void Pin (frame_id_t frame_id) override void Unpin (frame_id_t frame_id) override size_t Size () override void DeleteNode (LinkListNode *curr) private : std::unordered_map<frame_id_t , std::list<frame_id_t >::iterator> data_idx_; std::list<frame_id_t > data_; std::mutex data_latch_; };
在这里,LRU策略可以由哈希表加双向链表 的方式实现,其中链表充当队列的功能以记录页面被访问的先后顺序,哈希表则记录<页面ID - 链表节点>键值对,以在O(1)复杂度下删除链表元素。实际实现中使用STL中的哈希表unordered_map和双向链表list,并在unordered_map中存储指向链表节点的list::iterator
bool LRUReplacer::Victim (frame_id_t *frame_id) data_latch_.lock (); if (data_idx_.empty ()) { data_latch_.unlock (); return false ; } *frame_id = data_.front (); data_.pop_front (); data_idx_.erase (*frame_id); data_latch_.unlock (); return true ; }
对于Victim,首先判断链表是否为空,如不为空则返回链表首节点的页面ID,并在哈希表中解除指向首节点的映射。为了保证线程安全,整个函数应当由mutex互斥锁保护,下文中对互斥锁操作不再赘述。
void LRUReplacer::Pin (frame_id_t frame_id) data_latch_.lock (); auto it = data_idx_.find (frame_id); if (it != data_idx_.end ()) { data_.erase (it->second); data_idx_.erase (it); } data_latch_.unlock (); }
对于Pin,其检查LRUReplace中是否存在对应页面ID的节点,如不存在则直接返回,如存在对应节点则通过哈希表中存储的迭代器删除链表节点,并解除哈希表对应页面ID的映射
void LRUReplacer::Unpin (frame_id_t frame_id) data_latch_.lock (); auto it = data_idx_.find (frame_id); if (it == data_idx_.end ()) { data_.push_back (frame_id); data_idx_[frame_id] = prev (data_.end ()); } data_latch_.unlock (); }
对于Unpin,其检查LRUReplacer中是否存在对应页面ID的节点,如存在则直接返回,如不存在则在链表尾部插入页面ID的节点,并在哈希表中插入<页面ID - 链表尾节点>映射
size_t LRUReplacer::Size () data_latch_.lock (); size_t ret = data_idx_.size (); data_latch_.unlock (); return ret; }
对于Size,返回哈希表大小即可
Task2 : BUFFER POOL MANAGER INSTANCE 缓冲池 槽, 磁盘 页, buffer pool中free_list_装的是槽号
在部分中,需要实现缓冲池管理模块,其从DiskManager中获取数据库页面,并在缓冲池强制要求时或从缓冲池驱逐页面时将数据库脏页面写回DiskManager
class BufferPoolManagerInstance : public BufferPoolManager {... Page *pages_; DiskManager *disk_manager_ __attribute__((__unused__)); LogManager *log_manager_ __attribute__((__unused__)); std::unordered_map<page_id_t , frame_id_t > page_table_; Replacer *replacer_; std::list<frame_id_t > free_list_; std::mutex latch_; };
缓冲池的成员如上所示,其中pages_为缓冲池中的实际容器页面槽位数组,用于存放从磁盘中读入的页面,并供DBMS访问;disk_manager_为磁盘管理器,提供从磁盘读入页面及写入页面的接口;log_manager_为日志管理器,本实验中不用考虑该组件;page_table_用于保存磁盘页面IDpage_id和槽位IDframe_id_t的映射;raplacer_用于选取所需驱逐的页面;free_list_保存缓冲池中的空闲槽位ID。在这里,区分page_id和frame_id_t是完成本实验的关键。
class Page { friend class BufferPoolManagerInstance ; public : Page () { ResetMemory (); } ~Page () = default ; inline auto GetData () -> char * return data_; } inline auto GetPageId () -> page_id_t return page_id_; } inline auto GetPinCount () -> int return pin_count_; } inline auto IsDirty () -> bool return is_dirty_; } ... private : inline void ResetMemory () memset (data_, OFFSET_PAGE_START, PAGE_SIZE); } char data_[PAGE_SIZE]{}; page_id_t page_id_ = INVALID_PAGE_ID; int pin_count_ = 0 ; bool is_dirty_ = false ; ReaderWriterLatch rwlatch_; };
Page是缓冲池中的页面容器,data_保存对应磁盘页面的实际数据;page_id_保存该页面在磁盘管理器中的页面ID;pin_count_保存DBMS中正使用该页面的用户数目;is_dirty_保存该页面自磁盘读入或写回后是否被修改。下面,将介绍缓冲池中的接口实现:
bool BufferPoolManagerInstance::FlushPgImp (page_id_t page_id) frame_id_t frame_id; latch_.lock (); if (page_table_.count (page_id) == 0U ) { latch_.unlock (); return false ; } frame_id = page_table_[page_id]; pages_[frame_id].is_dirty_ = false ; disk_manager_->WritePage (page_id, pages_[frame_id].GetData ()); latch_.unlock (); return true ; }
FlushPgImp用于显式地将缓冲池页面写回磁盘。首先,应当检查缓冲池中是否存在对应页面ID的页面,如不存在则返回False;如存在对应页面,则将缓冲池内的该页面的is_dirty_置为false,并使用WritePage将该页面的实际数据data_写回磁盘
void BufferPoolManagerInstance::FlushAllPgsImp () latch_.lock (); for (auto [page_id, frame_id] : page_table_) { pages_[frame_id].is_dirty_ = false ; disk_manager_->WritePage (page_id, pages_[frame_id].GetData ()); } latch_.unlock (); }
FlushAllPgsImp将缓冲池内的所有页面写回磁盘。在这里,遍历page_table_以获得缓冲池内的<页面ID - 槽位ID>对,通过槽位ID获取实际页面,并通过页面ID作为写回磁盘的参数
Page *BufferPoolManagerInstance::NewPgImp (page_id_t *page_id) { frame_id_t new_frame_id; latch_.lock (); if (!free_list_.empty ()) { new_frame_id = free_list_.front (); free_list_.pop_front (); } else if (!replacer_->Victim (&new_frame_id)) { latch_.unlock (); return nullptr ; } *page_id = AllocatePage (); if (pages_[new_frame_id].IsDirty ()) { page_id_t flush_page_id = pages_[new_frame_id].page_id_; pages_[new_frame_id].is_dirty_ = false ; disk_manager_->WritePage (flush_page_id, pages_[new_frame_id].GetData ()); } page_table_.erase (pages_[new_frame_id].page_id_); page_table_[*page_id] = new_frame_id; pages_[new_frame_id].page_id_ = *page_id; pages_[new_frame_id].ResetMemory (); pages_[new_frame_id].pin_count_ = 1 ; replacer_->Pin (new_frame_id); latch_.unlock (); return &pages_[new_frame_id]; }
NewPgImp在磁盘中分配新的物理页面,将其添加至缓冲池,并返回指向缓冲池页面Page的指针。在这里,该函数由以下步骤组成:
检查当前缓冲池中是否存在空闲槽位或存放页面可被驱逐的槽位(下文称其为目标槽位),在这里总是先通过检查free_list_以查询空闲槽位,如无空闲槽位则尝试从replacer_中驱逐页面并返回被驱逐页面的槽位。如目标槽位,则返回空指针;如存在目标槽位,则调用AllocatePage()为新的物理页面分配page_id页面ID。
值得注意的是,在这里需要检查目标槽位中的页面是否为脏页面,如是则需将其写回磁盘,并将其脏位设为false;
从page_table_中删除目标槽位中的原页面ID的映射,并将新的<页面ID - 槽位ID>映射插入,然后更新槽位中页面的元数据。需要注意的是,在这里由于我们返回了指向该页面的指针,我们需要将该页面的用户数pin_count_置为1,并调用replacer_的Pin
Page *BufferPoolManagerInstance::FetchPgImp (page_id_t page_id) { frame_id_t frame_id; latch_.lock (); if (page_table_.count (page_id) != 0U ) { frame_id = page_table_[page_id]; pages_[frame_id].pin_count_++; replacer_->Pin (frame_id); latch_.unlock (); return &pages_[frame_id]; } if (!free_list_.empty ()) { frame_id = free_list_.front (); free_list_.pop_front (); page_table_[page_id] = frame_id; disk_manager_->ReadPage (page_id, pages_[frame_id].data_); pages_[frame_id].pin_count_ = 1 ; pages_[frame_id].page_id_ = page_id; replacer_->Pin (frame_id); latch_.unlock (); return &pages_[frame_id]; } if (!replacer_->Victim (&frame_id)) { latch_.unlock (); return nullptr ; } if (pages_[frame_id].IsDirty ()) { page_id_t flush_page_id = pages_[frame_id].page_id_; pages_[frame_id].is_dirty_ = false ; disk_manager_->WritePage (flush_page_id, pages_[frame_id].GetData ()); } page_table_.erase (pages_[frame_id].page_id_); page_table_[page_id] = frame_id; pages_[frame_id].page_id_ = page_id; disk_manager_->ReadPage (page_id, pages_[frame_id].data_); pages_[frame_id].pin_count_ = 1 ; replacer_->Pin (frame_id); latch_.unlock (); return &pages_[frame_id]; }
FetchPgImp的功能是获取对应页面ID的页面,并返回指向该页面的指针,其由以下步骤组成:
首先,通过检查page_table_以检查缓冲池中是否已经缓冲该页面,如果已经缓冲该页面,则直接返回该页面,并将该页面的用户数pin_count_递增以及调用replacer_的Pin方法;
如缓冲池中尚未缓冲该页面,则需寻找当前缓冲池中是否存在空闲槽位或存放页面可被驱逐的槽位(下文称其为目标槽位),该流程与NewPgImp中的对应流程相似,唯一不同的则是传入目标槽位的page_id为函数参数而非由AllocatePage()分配得到。
bool BufferPoolManagerInstance::DeletePgImp (page_id_t page_id) DeallocatePage (page_id); latch_.lock (); if (page_table_.count (page_id) == 0U ) { latch_.unlock (); return true ; } frame_id_t frame_id; frame_id = page_table_[page_id]; if (pages_[frame_id].pin_count_ != 0 ) { latch_.unlock (); return false ; } if (pages_[frame_id].IsDirty ()) { page_id_t flush_page_id = pages_[frame_id].page_id_; pages_[frame_id].is_dirty_ = false ; disk_manager_->WritePage (flush_page_id, pages_[frame_id].GetData ()); } page_table_.erase (page_id); pages_[frame_id].page_id_ = INVALID_PAGE_ID; free_list_.push_back (frame_id); latch_.unlock (); return true ; }
DeletePgImp的功能为从缓冲池中删除对应页面ID的页面,并将其插入空闲链表free_list_,其由以下步骤组成:
首先,检查该页面是否存在于缓冲区,如未存在则返回True。然后,检查该页面的用户数pin_count_是否为0,如非0则返回False。在这里,不难看出DeletePgImp的返回值代表的是该页面是否被用户使用,因此在该页面不在缓冲区时也返回True;
检查该页面是否为脏,如是则将其写回并将脏位设置为False。然后,在page_table_中删除该页面的映射,并将该槽位中页面的page_id置为INVALID_PAGE_ID。最后,将槽位ID插入空闲链表即可
bool BufferPoolManagerInstance::UnpinPgImp (page_id_t page_id, bool is_dirty) latch_.lock (); frame_id_t frame_id; if (page_table_.count (page_id) != 0U ) { frame_id = page_table_[page_id]; pages_[frame_id].is_dirty_ |= is_dirty; if (pages_[frame_id].pin_count_ <= 0 ) { latch_.unlock (); return false ; } if (--pages_[frame_id].pin_count_ == 0 ) { replacer_->Unpin (frame_id); } } latch_.unlock (); return true ; }
UnpinPgImp的功能为提供用户向缓冲池通知页面使用完毕的接口,用户需声明使用完毕页面的页面ID以及使用过程中是否对该页面进行修改。其由以下步骤组成:
首先,需检查该页面是否在缓冲池中,如未在缓冲池中则返回True。然后,检查该页面的用户数是否大于0,如不存在用户则返回false;
递减该页面的用户数pin_count_,如在递减后该值等于0,则调用replacer_->Unpin以表示该页面可以被驱逐。
Task 3 :PARALLEL BUFFER POOL MANAGER 不难看出,上述缓冲池实现的问题在于锁的粒度过大,其在进行任何一项操作时都将整个缓冲池锁住,因此几乎不存在并行性。在这里,并行缓冲池的思想是分配多个独立的缓冲池,并将不同的页面ID映射至各自的缓冲池中,从而减少整体缓冲池的锁粒度,以增加并行性。
class ParallelBufferPoolManager : public BufferPoolManager { ... private : std::vector<BufferPoolManager *> instances_; size_t start_idx_{0 }; size_t pool_size_; size_t num_instances_; };
并行缓冲池的成员如上,instances_用于存储多个独立的缓冲池,pool_size_记录各缓冲池的容量,num_instances_为独立缓冲池的个数,start_idx见下文介绍。
ParallelBufferPoolManager::ParallelBufferPoolManager (size_t num_instances, size_t pool_size, DiskManager *disk_manager, LogManager *log_manager) : pool_size_ (pool_size), num_instances_ (num_instances) { for (size_t i = 0 ; i < num_instances; i++) { BufferPoolManager *tmp = new BufferPoolManagerInstance (pool_size, num_instances, i, disk_mana ger, log_manager); instances_.push_back (tmp); } } ParallelBufferPoolManager::~ParallelBufferPoolManager () { for (size_t i = 0 ; i < num_instances_; i++) delete (instances_[i]); }
在这里,各独立缓冲池在堆区中进行分配,构造函数和析构函数需要完成相应的分配和释放工作。
size_t ParallelBufferPoolManager::GetPoolSize () return num_instances_ * pool_size_; } BufferPoolManager *ParallelBufferPoolManager::GetBufferPoolManager (page_id_t page_id) { return instances_[page_id % num_instances_]; }
需要注意的是,GetPoolSize应返回全部缓冲池的容量,即独立缓冲池个数乘以缓冲池容量。
GetBufferPoolManager返回页面ID所对应的独立缓冲池指针,在这里,通过对页面ID取余的方式将页面ID映射至对应的缓冲池。
Page *ParallelBufferPoolManager::FetchPgImp (page_id_t page_id) { BufferPoolManager *instance = GetBufferPoolManager (page_id); return instance->FetchPage (page_id); } bool ParallelBufferPoolManager::UnpinPgImp (page_id_t page_id, bool is_dirty) BufferPoolManager *instance = GetBufferPoolManager (page_id); return instance->UnpinPage (page_id, is_dirty); } bool ParallelBufferPoolManager::FlushPgImp (page_id_t page_id) BufferPoolManager *instance = GetBufferPoolManager (page_id); return instance->FlushPage (page_id); } ... bool ParallelBufferPoolManager::DeletePgImp (page_id_t page_id) BufferPoolManager *instance = GetBufferPoolManager (page_id); return instance->DeletePage (page_id); } void ParallelBufferPoolManager::FlushAllPgsImp () for (size_t i = 0 ; i < num_instances_; i++) { instances_[i]->FlushAllPages (); } }
上述函数仅需调用对应独立缓冲池的方法即可。值得注意的是,由于在缓冲池中存放的为缓冲池实现类的基类指针,因此所调用函数的应为缓冲池实现类的基类对应的虚函数。并且,由于ParallelBufferPoolManager和BufferPoolManagerInstance为兄弟关系,因此ParallelBufferPoolManager不能直接调用BufferPoolManagerInstance对应的Imp函数,因此直接在ParallelBufferPoolManager中存放BufferPoolManagerInstance指针也是不可行的。
Page *ParallelBufferPoolManager::NewPgImp (page_id_t *page_id) { Page *ret; for (size_t i = 0 ; i < num_instances_; i++) { size_t idx = (start_idx_ + i) % num_instances_; if ((ret = instances_[idx]->NewPage (page_id)) != nullptr ) { start_idx_ = (*page_id + 1 ) % num_instances_; return ret; } } start_idx_++; return nullptr ; }
在这里,为了使得各独立缓冲池的负载均衡,采用轮转方法选取分配物理页面时使用的缓冲池,在这里具体的规则如下:
从start_idx_开始遍历各独立缓冲池,如存在调用NewPage成功的页面,则返回该页面并将start_idx指向该页面的下一个页面;
如全部缓冲池调用NewPage均失败,则返回空指针,并递增start_idx。
实验结果
Project 2 : EXTENDIBLE HASH INDEX 在本实验中,需要实现一个磁盘备份 的可扩展哈希表 ,用于DBMS中的索引检索。磁盘备份指该哈希表可写入至磁盘中,在系统重启时可以将其重新读取至内存中使用。可扩展哈希表是动态哈希表的一种类型,其特点为桶在充满或清空时可以桶为单位进行桶分裂或合并,尽在特定情况下进行哈希表全表的扩展和收缩,以减小扩展和收缩操作对全表的影响。
可扩展哈希表 本文介绍了书中未讲解的低位可拓展哈希表 的原理及其实现,且原理与实现之间设置了跳转以方便阅读
在进行实验之前,我们应当了解可扩展哈希表的具体实现原理。在这里,其最根本的思想在于通过改变哈希表用于映射至对应桶的哈希键位数来控制哈希表的总大小,该哈希键位数被称为全局深度。下面是全局深度的一个例子:
[](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 1.png)
上图为通过哈希函数对字符串产生哈希键的一个示例。可见,当哈希键的位数为32位时,不同的哈希键有2^32个,这代表哈希表将拥有上述数目的目录项以将哈希键映射至相应的哈希桶,该数目显然过于庞大了。因此,我们可以仅关注哈希键的低几位(高几位亦可,但使用低位更易实现)以缩小哈希表目录项的个数。例如,当我们仅关注哈希键的后三位时,不同的哈希键为...000至...111共8个,因此我们仅需为哈希表保存8个目录项即可将各低位不同的哈希键映射至对应的哈希表。
[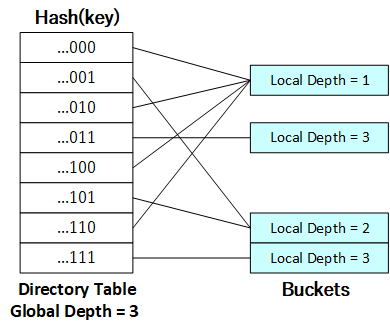](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 2.png)
local depth指的是(假设local depth为n),在当前的bucket之下,每个元素的key的低n位都是相同的。
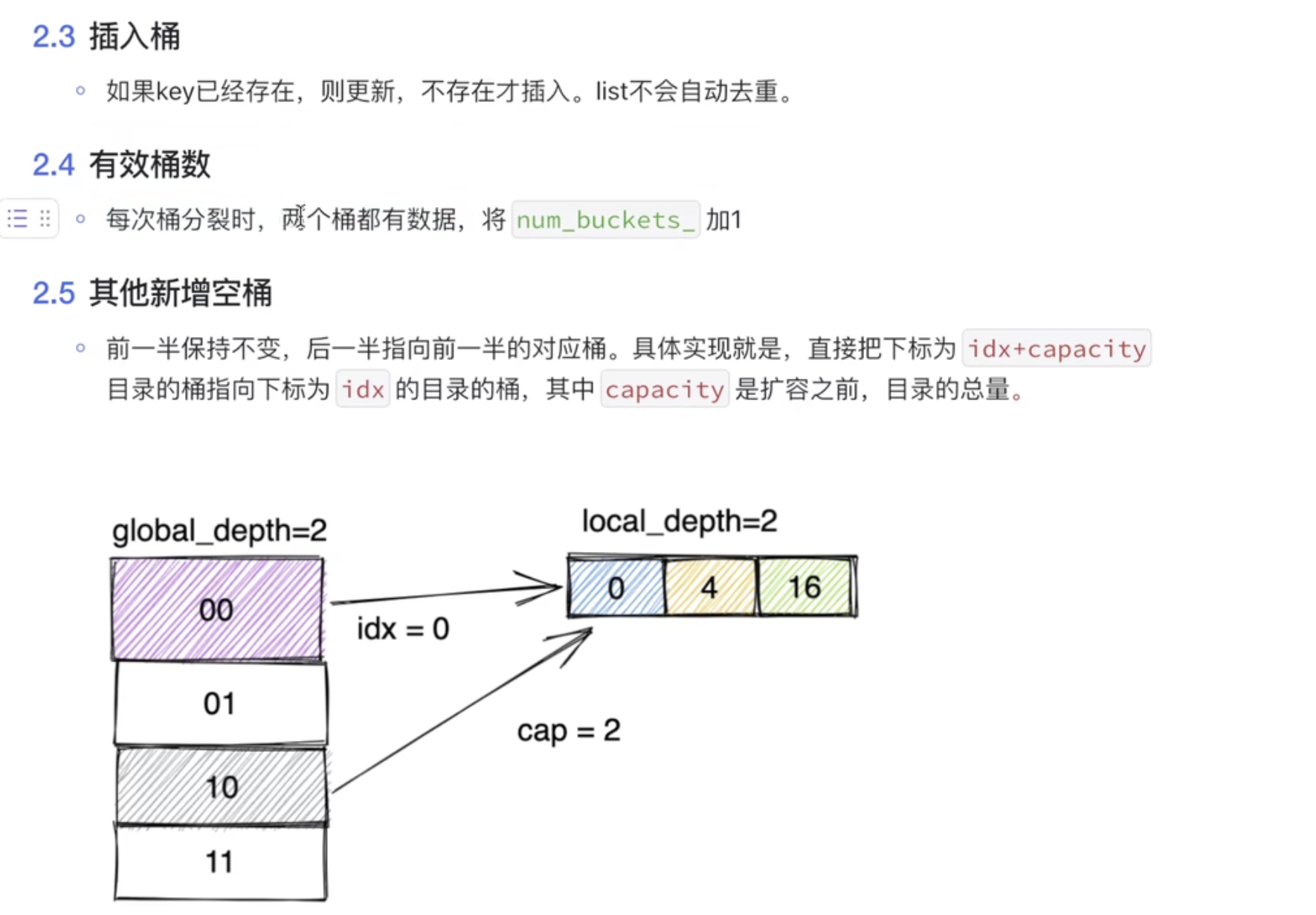
除了用于控制哈希表大小的全局深度 外,每个哈希表目录项均具有一个局部深度 ,其记录该目录项所对应的哈希桶所关注的哈希键位数。因此,局部深度以桶为单位 划分的,某个目录项的局部深度即为该目录项所指的桶的局部深度。当哈希表的全局深度为i,某目录项的局部深度为j时,指向该目录项所对应的哈希桶的目录项个数为2^(i-j)。
桶分裂/合并 表扩展/收缩 下面,我将使用一个例子来展示可扩展哈希表的桶分裂/合并,表扩展/收缩行为。在说明中,将使用i代表表的全局深度,j代表目录项的局部深度:
[](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 3.png)
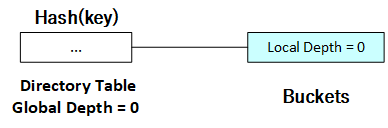
当哈希表刚被创建时,其全局深度为0,即哈希表仅有一个目录项,任何一个哈希键都将被映射到同一个哈希桶。当该哈希桶被充满时,需要进行桶和目录的分裂
当桶对应目录项的局部深度 = 全局深度时,指向该桶的目录项仅有一条,因此需要进行目录拓展。将目录的全局深度 + 1,原桶分裂为两个local depth = global depth 的桶,并将原哈希桶的记录重新插入至新哈希桶或原哈希桶。对于其他目录项,表扩展后低i-1位相同的目录项指向同一桶页面,低第i位相反的两个页面互为分裂映像 (实验中的自命名词汇)。[代码实现见下文](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#splitcode)。
当上图中的哈希桶充满时,哈希表将更新至下图所示形式:
[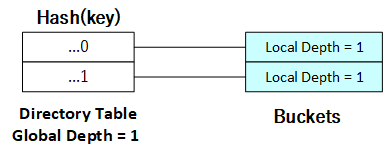](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 4.png)
当...0目录项所对应的桶被充满时,由于全局深度和该目录项的局部深度仍然相同,因此仍需进行表扩展:
[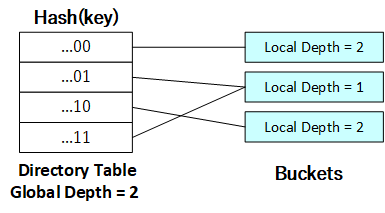](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 5.png)
当...00目录项所对应的桶充满时,由于全局深度和该目录项的局部深度仍然相同,因此仍需进行表扩展:
[](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 6.png)
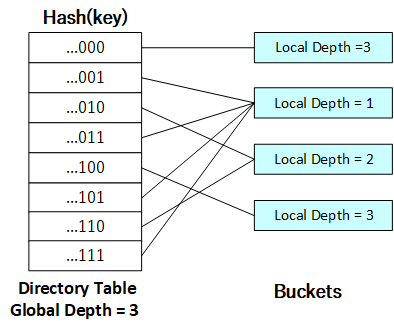
当...001目录项的桶充满时,由于该目录项的局部深度j小于全局深度i不必进行目录的拓展,仅需将桶分裂,j + 1,并将原哈希桶映射的目录项的一半指向原哈希桶,另一半指向新哈希桶 。因此有2^(i-j)个目录项指向所需分裂的哈希桶。划分的规则为低j+1位相同的目录项在分裂后仍指向同一个桶
另一个可能的问题是,如何找到与该目录项指向同一哈希桶的其他目录项。在这里,对于全局深度为i,局部深度为j的目录项,与其共同指向同一哈希桶的目录项(下面称为兄弟目录项)的低j位相同,且通过以下三个特性可以方便的遍历所有兄弟目录项:
兄弟目录项中的最顶端 目录项为低j位不变、其余位为0的目录项;
相邻两个目录项的哈希键相差1<<j;
兄弟目录项的总数为1<<(i - j)。
上述操作代码实现[见下文](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#splitcode),分裂后的哈希表如下所示:
[](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 7.png)
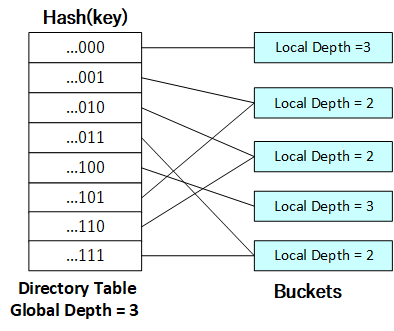
当一个目录项所指的哈希桶为空时,需要判断其是否可以与其目标目录项 所指的哈希桶合并。一个目录项的目标目录项可由其低第j位反转得到,值得注意的是,由于目录项间的局部深度可能不同,因此目标目录项不一定是可逆的。例如,上图中...010目录项的目标目录项为...000,而...000的目标目录项却为...100。目录项及其目标目录项所指的两个哈希桶的合并的条件如下:
(1)两哈希桶均为空桶;
(2)目录项及其目标目录项的局部深度相同且不为0。
此时,若...001和...011目录项所指的两个哈希桶均为空,则可以进行合并(代码实现见[下文](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#mergecode)):
[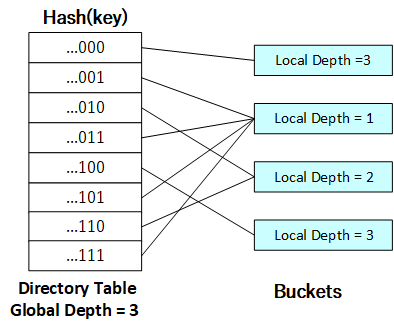](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 8.png)
合并后,需要将指向合并后哈希桶的所有目录项的局部深度减一。此时,若...000和...100所指的哈希桶均为空,则可以进行合并:
[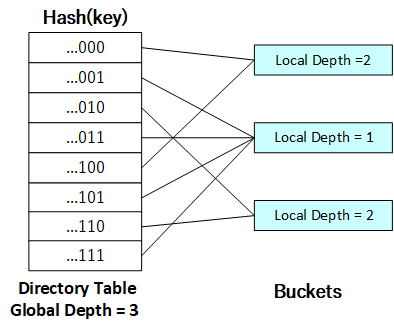](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 9.png)
当哈希桶合并后使得所有目录项的局部深度均小于全局深度时,既可以进行哈希表的收缩。在这里可以体现低位可拓展哈希表,即收缩哈希表仅需将全局深度减一即可,而不需改变其余任何哈希表的元数据。下图展示了哈希表收缩后的形态:
[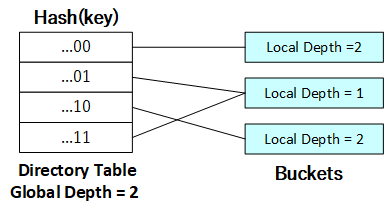](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/project2_figure/figure 10.png)
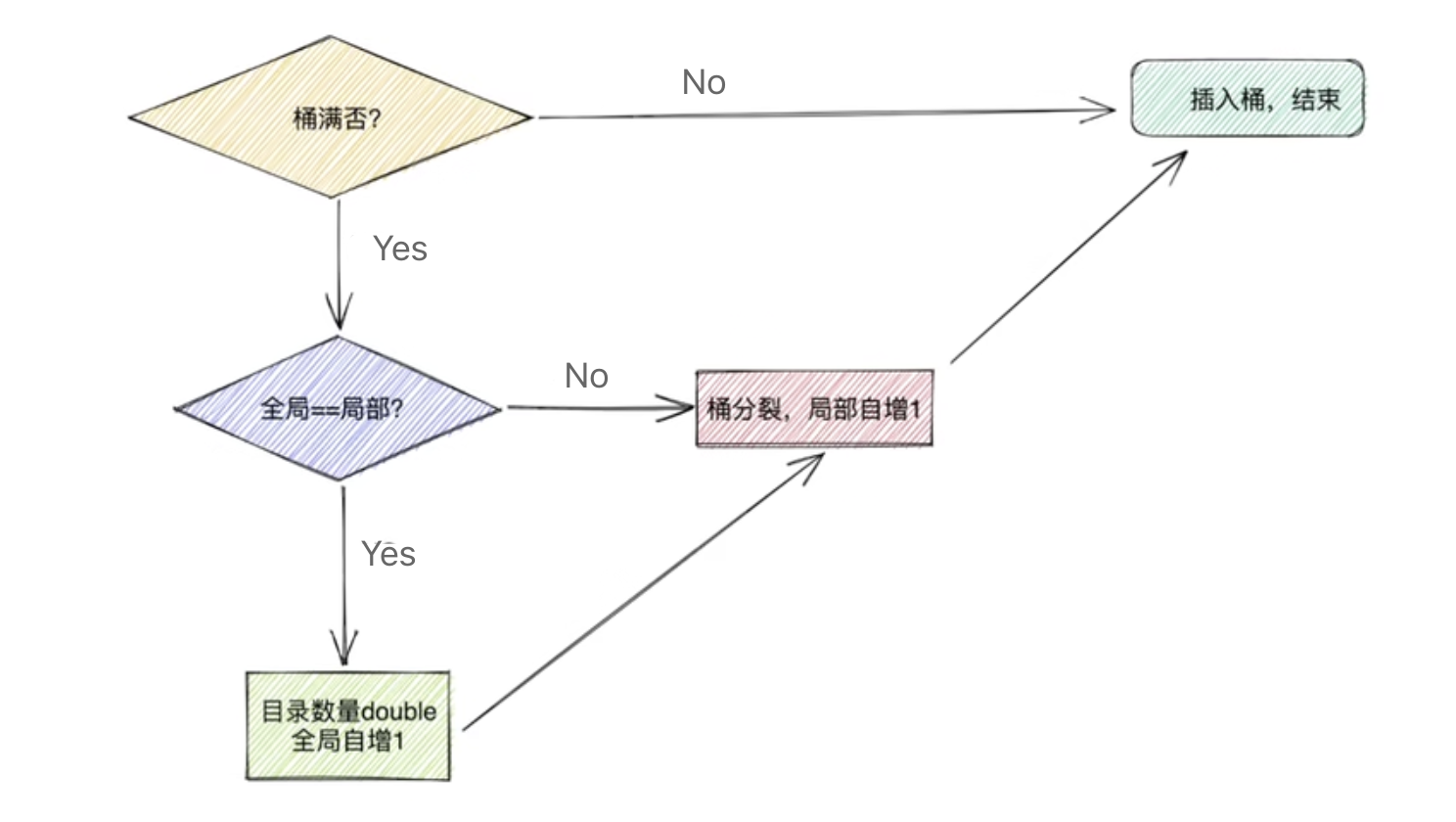
插入流程
Task 1 : PAGE LAYOUTS 为了能在磁盘中写入和读取该哈希表,在这里需要实现两个页面类存储哈希表的数据,其使用上实验中的Page页面作为载体,以在磁盘中被写入和读取,具体的实现原理将在下文中介绍:
HashTableDirectoryPage class HashTableDirectoryPage { public : ... private : page_id_t page_id_; lsn_t lsn_; uint32_t global_depth_{0 }; uint8_t local_depths_[DIRECTORY_ARRAY_SIZE]; page_id_t bucket_page_ids_[DIRECTORY_ARRAY_SIZE]; };
该页面类作为哈希表的目录页面,保存哈希表中使用的所有元数据,包括该页面的页面ID。
uint32_t HashTableDirectoryPage::GetGlobalDepthMask () return (1U << global_depth_) - 1 ; } ... bool HashTableDirectoryPage::CanShrink () uint32_t bucket_num = 1 << global_depth_; for (uint32_t i = 0 ; i < bucket_num; i++) { if (local_depths_[i] == global_depth_) { return false ; } } return true ; }
GetGlobalDepthMask通过位运算返回用于计算全局深度低位的掩码;CanShrink()检查当前所有有效目录项的局部深度是否均小于全局深度,以判断是否可以进行表合并
HashTableBucketPage template <typename KeyType, typename ValueType, typename KeyComparator>class HashTableBucketPage { public : ... private : char occupied_[(BUCKET_ARRAY_SIZE - 1 ) / 8 + 1 ]; char readable_[(BUCKET_ARRAY_SIZE - 1 ) / 8 + 1 ]; MappingType array_[0 ]; }
该页面类用于存放哈希桶的键值与存储值对,以及桶的槽位状态数据。occupied_数组用于统计桶中的槽是否被使用过,当一个槽被插入键值对时,其对应的位被置为1;readable_数组用于标记桶中的槽是否被占用,当被占用时该值被置为1,否则置为0;array_是C++中一种弹性数组的写法,在这里只需知道它用于存储实际的键值对即可
下面是使用位运算的状态数组读取和设置函数:
template <typename KeyType, typename ValueType, typename KeyComparator>void HASH_TABLE_BUCKET_TYPE::RemoveAt (uint32_t bucket_idx) readable_[bucket_idx / 8 ] &= ~(1 << (7 - (bucket_idx % 8 ))); } template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::IsOccupied (uint32_t bucket_idx) const return (occupied_[bucket_idx / 8 ] & (1 << (7 - (bucket_idx % 8 )))) != 0 ; } template <typename KeyType, typename ValueType, typename KeyComparator>void HASH_TABLE_BUCKET_TYPE::SetOccupied (uint32_t bucket_idx) occupied_[bucket_idx / 8 ] |= 1 << (7 - (bucket_idx % 8 )); } template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::IsReadable (uint32_t bucket_idx) const return (readable_[bucket_idx / 8 ] & (1 << (7 - (bucket_idx % 8 )))) != 0 ; } template <typename KeyType, typename ValueType, typename KeyComparator>void HASH_TABLE_BUCKET_TYPE::SetReadable (uint32_t bucket_idx) readable_[bucket_idx / 8 ] |= 1 << (7 - (bucket_idx % 8 )); }
对于对应索引的键值读取直接访问array_数组即可:
template <typename KeyType, typename ValueType, typename KeyComparator>KeyType HASH_TABLE_BUCKET_TYPE::KeyAt (uint32_t bucket_idx) const { return array_[bucket_idx].first; } template <typename KeyType, typename ValueType, typename KeyComparator>ValueType HASH_TABLE_BUCKET_TYPE::ValueAt (uint32_t bucket_idx) const { return array_[bucket_idx].second; } template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::GetValue (KeyType key, KeyComparator cmp, std::vector<ValueType> *result) bool ret = false ; for (size_t bucket_idx = 0 ; bucket_idx < BUCKET_ARRAY_SIZE; bucket_idx++) { if (!IsOccupied (bucket_idx)) { break ; } if (IsReadable (bucket_idx) && cmp (key, KeyAt (bucket_idx)) == 0 ) { result->push_back (array_[bucket_idx].second); ret = true ; } } return ret; }
该函数遍历当前桶页中的所有键值对,并在满足以下条件时将对应的值加入到 result 向量中:
键值对在桶中已被占用(IsOccupied(bucket_idx) == true);
键值对的可读性为可读(IsReadable(bucket_idx) == true);
给定的 key 与当前键值对的键相等(cmp(key, KeyAt(bucket_idx)) == 0)。
在满足以上三个条件的情况下,将当前键值对的值加入到 result 向量中,并将 ret 标记为 true,表示找到了至少一个匹配的键值对。
最后,函数返回 ret 标记,指示是否找到了匹配的键值对
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::Insert (KeyType key, ValueType value, KeyComparator cmp) size_t slot_idx = 0 ; bool slot_found = false ; for (size_t bucket_idx = 0 ; bucket_idx < BUCKET_ARRAY_SIZE; bucket_idx++) { if (!slot_found && (!IsReadable (bucket_idx) || !IsOccupied (bucket_idx))) { slot_found = true ; slot_idx = bucket_idx; } if (!IsOccupied (bucket_idx)) break ; if (IsReadable (bucket_idx) && cmp (key, KeyAt (bucket_idx)) == 0 && value == ValueAt (bucket_idx)) { return false ; } } if (slot_found) { SetReadable (slot_idx); SetOccupied (slot_idx); array_[slot_idx] = MappingType (key, value); return true ; } return false ; }
Insert向桶插入键值对,其先检测该键值对是否已经被插入到桶中,如是则返回假;如未找到该键值对,则从小到大遍历所有occupied_为1的位,如出现readable_为1的位,则在array_中对应的数组中插入键值对。由于此种插入特性,因此occupied_为1的位是连续的,因此occupied_的功能与一个size参数是等价的。在这里仍然采用occupied_数组的原因可能是提供静态哈希表的实现兼容性(静态哈希表采用线性探测法解决散列冲突,因此必须使用occupied_数组)。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::Remove (KeyType key, ValueType value, KeyComparator cmp) for (size_t bucket_idx = 0 ; bucket_idx < BUCKET_ARRAY_SIZE; bucket_idx++) { if (!IsOccupied (bucket_idx)) { break ; } if (IsReadable (bucket_idx) && cmp (key, KeyAt (bucket_idx)) == 0 && value == ValueAt (bucket_idx)) { RemoveAt (bucket_idx); return true ; } } return false ; }
Remove从桶中删除对应的键值对,遍历桶所有位即可。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::IsFull () return NumReadable () == BUCKET_ARRAY_SIZE; } template <typename KeyType, typename ValueType, typename KeyComparator>uint32_t HASH_TABLE_BUCKET_TYPE::NumReadable () uint32_t ret = 0 ; for (size_t bucket_idx = 0 ; bucket_idx < BUCKET_ARRAY_SIZE; bucket_idx++) { if (!IsOccupied (bucket_idx)) { break ; } if (IsReadable (bucket_idx)) { ret++; } } return ret; } template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_BUCKET_TYPE::IsEmpty () return NumReadable () == 0 ; }
NumReadable()返回桶中的键值对个数,遍历即可。IsFull()和IsEmpty()直接复用NumReadable()实现。
Page与上述两个页面类的转换 在本部分中,有难点且比较巧妙的地方在于理解上述两个页面类是如何与Page类型转换的。在这里,上述两个页面类并非未Page类的子类,在实际应用中通过reinterpret_cast将Page与两个页面类进行转换。在这里我们回顾一下Page的数据成员:
private : inline void ResetMemory () memset (data_, OFFSET_PAGE_START, PAGE_SIZE); } char data_[PAGE_SIZE]{}; page_id_t page_id_ = INVALID_PAGE_ID; int pin_count_ = 0 ; bool is_dirty_ = false ; ReaderWriterLatch rwlatch_; };
可以看出,Page中用于存放实际数据的data_数组位于数据成员的第一位,其在栈区固定分配一个页面的大小。因此,在Page与两个页面类强制转换时,通过两个页面类的指针的操作仅能影响到data_中的实际数据,而影响不到其它元数据。并且在内存管理器中始终是进行所占空间更大的通用页面Page的分配(实验中的NewPage),因此页面的容量总是足够的。
Task 2,3 : HASH TABLE IMPLEMENTATION + CONCURRENCY CONTROL 在这两个部分中,我们需要实现一个线程安全的可扩展哈希表。在对可扩展哈希表的原理清楚后,将其实现并不困难,难点在于如何在降低锁粒度、提高并发性的情况下保证线程安全。下面是哈希表的具体实现:
template <typename KeyType, typename ValueType, typename KeyComparator>HASH_TABLE_TYPE::ExtendibleHashTable (const std::string &name, BufferPoolManager *buffer_pool_manager, const KeyComparator &comparator, HashFunction<KeyType> hash_fn) : buffer_pool_manager_ (buffer_pool_manager), comparator_ (comparator), hash_fn_ (std::move (hash_fn)) { HashTableDirectoryPage *dir_page = reinterpret_cast <HashTableDirectoryPage *>(buffer_pool_manager_->NewPage (&directory_page_id_)); dir_page->SetPageId (directory_page_id_); page_id_t new_bucket_id; buffer_pool_manager_->NewPage (&new_bucket_id); dir_page->SetBucketPageId (0 , new_bucket_id); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (new_bucket_id, true , nullptr )); }
在构造函数中,为哈希表分配一个目录页面和桶页面,并设置目录页面的page_id成员、将哈希表的首个目录项指向该桶。最后,不要忘记调用UnpinPage向缓冲池告知页面的使用完毕。
template <typename KeyType, typename ValueType, typename KeyComparator>uint32_t HASH_TABLE_TYPE::KeyToDirectoryIndex (KeyType key, HashTableDirectoryPage *dir_page) uint32_t hashed_key = Hash (key); uint32_t mask = dir_page->GetGlobalDepthMask (); return mask & hashed_key; } template <typename KeyType, typename ValueType, typename KeyComparator>page_id_t HASH_TABLE_TYPE::KeyToPageId (KeyType key, HashTableDirectoryPage *dir_page) uint32_t idx = KeyToDirectoryIndex (key, dir_page); return dir_page->GetBucketPageId (idx); } template <typename KeyType, typename ValueType, typename KeyComparator>HashTableDirectoryPage *HASH_TABLE_TYPE::FetchDirectoryPage () { return reinterpret_cast <HashTableDirectoryPage *>(buffer_pool_manager_->FetchPage (directory_page_id_)); } template <typename KeyType, typename ValueType, typename KeyComparator>HASH_TABLE_BUCKET_TYPE *HASH_TABLE_TYPE::FetchBucketPage (page_id_t bucket_page_id) { return reinterpret_cast <HASH_TABLE_BUCKET_TYPE *>(buffer_pool_manager_->FetchPage (bucket_page_id)); }
上面是一些用于提取目录页面、桶页面以及目录页面中的目录项的功能函数。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_TYPE::GetValue (Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) HashTableDirectoryPage *dir_page = FetchDirectoryPage (); table_latch_.RLock (); page_id_t bucket_page_id = KeyToPageId (key, dir_page); HASH_TABLE_BUCKET_TYPE *bucket = FetchBucketPage (bucket_page_id); Page *p = reinterpret_cast <Page *>(bucket); p->RLatch (); bool ret = bucket->GetValue (key, comparator_, result); p->RUnlatch (); table_latch_.RUnlock (); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, false , nullptr )); assert (buffer_pool_manager_->UnpinPage (bucket_page_id, false , nullptr )); return ret; }
GetValue从哈希表中读取与键匹配的所有值结果,其通过哈希表的读锁保护目录页面,并使用桶的读锁保护桶页面。具体的操作步骤为先读取目录页面,再通过目录页面和哈希键或许对应的桶页面,最后调用桶页面的GetValue获取值结果。在函数返回时注意要UnpinPage所获取的页面。加锁时应当保证锁的获取、释放全局顺序以避免死锁。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_TYPE::Insert (Transaction *transaction, const KeyType &key, const ValueType &value ) HashTableDirectoryPage *dir_page = FetchDirectoryPage (); table_latch_.RLock (); page_id_t bucket_page_id = KeyToPageId (key, dir_page); HASH_TABLE_BUCKET_TYPE *bucket = FetchBucketPage (bucket_page_id); Page *p = reinterpret_cast <Page *>(bucket); p->WLatch (); if (bucket->IsFull ()) { p->WUnlatch (); table_latch_.RUnlock (); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr )); return SplitInsert (transaction, key, value); } bool ret = bucket->Insert (key, value, comparator_); p->WUnlatch (); table_latch_.RUnlock (); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr )); return ret; }
Insert向哈希表插入键值对,这可能会导致桶的分裂和表的扩张,因此需要保证目录页面的读线程安全,一种比较简单的保证线程安全的方法为:在操作目录页面前对目录页面加读锁。但这种加锁方式使得Insert函数阻塞了整个哈希表,这严重影响了哈希表的并发性。可以注意到,表的扩张的发生频率并不高,对目录页面的操作属于读多写少的情况,因此可以使用乐观锁的方法优化并发性能,其在Insert被调用时仅保持读锁,只在需要桶分裂时重新获得读锁。
Insert函数的具体流程为:
获取目录页面和桶页面,在加全局读锁和桶写锁后检查桶是否已满,如已满则释放锁,并调用UnpinPage释放页面,然后调用SplitInsert实现桶分裂和插入;
如当前桶未满,则直接向该桶页面插入键值对,并释放锁和页面即可。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_TYPE::SplitInsert (Transaction *transaction, const KeyType &key, const ValueType &value) HashTableDirectoryPage *dir_page = FetchDirectoryPage (); table_latch_.WLock (); while (true ) { page_id_t bucket_page_id = KeyToPageId (key, dir_page); uint32_t bucket_idx = KeyToDirectoryIndex (key, dir_page); HASH_TABLE_BUCKET_TYPE *bucket = FetchBucketPage (bucket_page_id); if (bucket->IsFull ()) { uint32_t global_depth = dir_page->GetGlobalDepth (); uint32_t local_depth = dir_page->GetLocalDepth (bucket_idx); page_id_t new_bucket_id = 0 ; HASH_TABLE_BUCKET_TYPE *new_bucket = reinterpret_cast <HASH_TABLE_BUCKET_TYPE *>(buffer_pool_manager_->NewPage (&new_bucket_id)); assert (new_bucket != nullptr );
由于SplitInsert比较复杂,这里进行分段讲解:
首先,获取目录页面并加全局写锁,在添加全局写锁后,其他所有线程均被阻塞了,因此可以放心的操作数据成员。不难注意到,在Insert中释放读锁和SplitInsert中释放写锁间存在空隙,其他线程可能在该空隙中被调度,从而改变桶页面或目录页面数据。因此,在这里需要重新在目录页面中获取哈希键所对应的桶页面(可能与Insert中判断已满的页面不是同一页面),并检查对应的桶页面是否已满。如桶页面仍然是满的,则分配新桶和提取原桶页面的元数据。在由于桶分裂后仍所需插入的桶仍可能是满的,因此在这这里进行循环以解决该问题。
if (global_depth == local_depth) { uint32_t bucket_num = 1 << global_depth; for (uint32_t i = 0 ; i < bucket_num; i++) { dir_page->SetBucketPageId (i + bucket_num, dir_page->GetBucketPageId (i)); dir_page->SetLocalDepth (i + bucket_num, dir_page->GetLocalDepth (i)); } dir_page->IncrGlobalDepth (); dir_page->SetBucketPageId (bucket_idx + bucket_num, new_bucket_id); dir_page->IncrLocalDepth (bucket_idx); dir_page->IncrLocalDepth (bucket_idx + bucket_num); global_depth++; } else { uint32_t mask = (1 << local_depth) - 1 ; uint32_t base_idx = mask & bucket_idx; uint32_t records_num = 1 << (global_depth - local_depth - 1 ); uint32_t step = (1 << local_depth); uint32_t idx = base_idx; for (uint32_t i = 0 ; i < records_num; i++) { dir_page->IncrLocalDepth (idx); idx += step * 2 ; } idx = base_idx + step; for (uint32_t i = 0 ; i < records_num; i++) { dir_page->SetBucketPageId (idx, new_bucket_id); dir_page->IncrLocalDepth (idx); idx += step * 2 ; } }
在这里,需要根据全局深度和桶页面的局部深度判断扩展表和分裂桶的策略。当global_depth == local_depth时,需要进行表扩展和桶分裂,global_depth == local_depth仅需进行桶分裂即可。原理介绍见上文所示:[表扩展及分裂桶](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#splitmethod1)、[仅分裂桶](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#splitmethod2),在这里不再赘述。
for (uint32_t i = 0 ; i < BUCKET_ARRAY_SIZE; i++) { KeyType j_key = bucket->KeyAt (i); ValueType j_value = bucket->ValueAt (i); bucket->RemoveAt (i); if (KeyToPageId (j_key, dir_page) == bucket_page_id) { bucket->Insert (j_key, j_value, comparator_); } else { new_bucket->Insert (j_key, j_value, comparator_); } } assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr ));assert (buffer_pool_manager_->UnpinPage (new_bucket_id, true , nullptr ));
在完成桶分裂后,应当将原桶页面中的记录重新插入哈希表,由于记录的低i-1位仅与原桶页面和新桶页面对应,因此记录插入的桶页面仅可能为原桶页面和新桶页面两个选择。在重新插入完记录后,释放新桶页面和原桶页面。
} else { bool ret = bucket->Insert (key, value, comparator_); table_latch_.WUnlock (); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr )); return ret; } } return false ;}
若当前键值对所插入的桶页面非空(被其他线程修改或桶分裂后结果),则直接插入键值对,并释放锁和页面,并将插入结果返回Insert。
template <typename KeyType, typename ValueType, typename KeyComparator>bool HASH_TABLE_TYPE::Remove (Transaction *transaction, const KeyType &key, const ValueType &value) HashTableDirectoryPage *dir_page = FetchDirectoryPage (); table_latch_.RLock (); page_id_t bucket_page_id = KeyToPageId (key, dir_page); uint32_t bucket_idx = KeyToDirectoryIndex (key, dir_page); HASH_TABLE_BUCKET_TYPE *bucket = FetchBucketPage (bucket_page_id); Page *p = reinterpret_cast <Page *>(bucket); p->WLatch (); bool ret = bucket->Remove (key, value, comparator_); p->WUnlatch (); if (bucket->IsEmpty () && dir_page->GetLocalDepth (bucket_idx) != 0 ) { table_latch_.RUnlock (); this ->Merge (transaction, key, value); } else { table_latch_.RUnlock (); } assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); return ret; }
Remove从哈希表中删除对应的键值对,其优化思想与Insert相同,由于桶的合并并不频繁,因此在删除键值对时仅获取全局读锁,只在需要合并桶时获取全局写锁。当删除后桶为空且目录项的局部深度不为零时,释放读锁并调用Merge尝试合并页面,随后释放锁和页面并返回。
template <typename KeyType, typename ValueType, typename KeyComparator>void HASH_TABLE_TYPE::Merge (Transaction *transaction, const KeyType &key, const ValueType &value) HashTableDirectoryPage *dir_page = FetchDirectoryPage (); table_latch_.WLock (); uint32_t bucket_idx = KeyToDirectoryIndex (key, dir_page); page_id_t bucket_page_id = dir_page->GetBucketPageId (bucket_idx); HASH_TABLE_BUCKET_TYPE *bucket = FetchBucketPage (bucket_page_id); if (bucket->IsEmpty () && dir_page->GetLocalDepth (bucket_idx) != 0 ) { uint32_t local_depth = dir_page->GetLocalDepth (bucket_idx); uint32_t global_depth = dir_page->GetGlobalDepth (); uint32_t merged_bucket_idx = bucket_idx ^ (1 << (local_depth - 1 )); page_id_t merged_page_id = dir_page->GetBucketPageId (merged_bucket_idx); HASH_TABLE_BUCKET_TYPE *merged_bucket = FetchBucketPage (merged_page_id); if (dir_page->GetLocalDepth (merged_bucket_idx) == local_depth && merged_bucket->IsEmpty ()) { local_depth--; uint32_t mask = (1 << local_depth) - 1 ; uint32_t idx = mask & bucket_idx; uint32_t records_num = 1 << (global_depth - local_depth); uint32_t step = (1 << local_depth); for (uint32_t i = 0 ; i < records_num; i++) { dir_page->SetBucketPageId (idx, bucket_page_id); dir_page->DecrLocalDepth (idx); idx += step; } buffer_pool_manager_->DeletePage (merged_page_id); } if (dir_page->CanShrink ()) { dir_page->DecrGlobalDepth (); } assert (buffer_pool_manager_->UnpinPage (merged_page_id, true , nullptr )); } table_latch_.WUnlock (); assert (buffer_pool_manager_->UnpinPage (directory_page_id_, true , nullptr )); assert (buffer_pool_manager_->UnpinPage (bucket_page_id, true , nullptr )); }
在Merge函数获取写锁后,需要重新判断是否满足合并条件,以防止在释放锁的空隙时页面被更改,在合并被执行时,需要判断当前目录页面是否可以收缩,如可以搜索在这里仅需递减全局深度即可完成收缩,最后释放页面和写锁。具体的合并细节和策略见[上文](https://github.com/jlu-xiurui/CMU15445-2021-FALL/blob/ghess/p2-refinement/notes/Project 2 EXTENDIBLE HASH INDEX.md#mergemethod)。
实验结果