Project1
常见的数据存储格式
- CSV (Comma Separated Values):CSV是一种简单的文本文件格式, 用于存储表格数据, 每行表示一条记录, 字段之间用逗号分隔

JSON (JavaScript Object Notation): JSON是一种轻量级的数据交换格式, 它使用文本表示结构化数据, 易于阅读和理解, 广泛用于Web应用程序和API

XML (Extensible Markup Language):XML也是一种文本格式,用于存储和传输结构化数据,具有强大的数据描述和验证功能

YAML (YAML Ain’t Markup Language):YAML是一种人类可读的数据序列化格式,类似于JSON,但使用缩进表示层次结构,更易于阅读和编写
Excel (.xlsx):Excel是一种电子表格文件格式,用于存储和分析表格数据,具有强大的数据处理和计算功能。
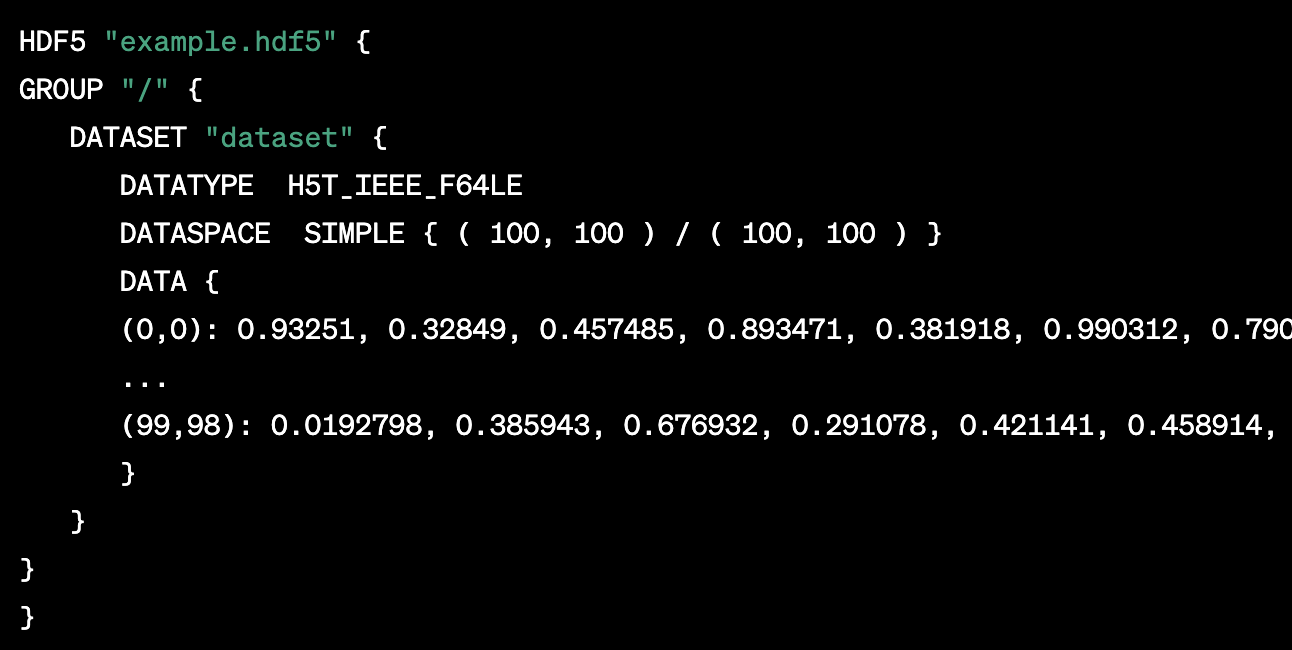
HDF5 (Hierarchical Data Format 5):HDF5格式文件是一种二进制文件格式, 其结构可以被看作是一个树形结构, 包含组(Group)和数据集(Dataset)等元素
HDF5是一种二进制文件格式,它的文件结构是由一系列二进制数据块组成的。虽然它的内容是以二进制形式存储的,但是我们可以使用特定的工具,如h5dump和h5ls,来查看HDF5文件的内容。这是因为这些工具能够读取和解释HDF5文件的二进制结构,并将其转换为人类可读的格式。
SQL (Structured Query Language):SQL是一种用于关系型数据库管理系统(RDBMS)的语言,可以用于创建、查询和修改数据。
C++处理CSV文件的库
有很多C++处理CSV文件的库可供选择,以下是其中几个:
CSVParser: 这是一个轻量级的、易于使用的开源库,可用于读写CSV文件。它提供了一个简单的接口,可用于解析CSV文件、读取和写入CSV数据。该库支持自定义分隔符、行结束符和引号字符。
RapidCSV: 这是一个高性能的、易于使用的开源库,可用于读写CSV文件。它支持多种分隔符和文本编码,并提供了一个简单的API,可用于读取和写入CSV数据。
Boost C++库: Boost是一个广泛使用的C++库,其中包含了许多有用的组件,包括用于处理CSV文件的库。 Boost提供了一个CSV库,该库支持自定义分隔符、行结束符和引号字符,并提供了一个简单的API,可用于读取和写入CSV数据。
Qt CSV:这是一个基于Qt框架的库,用于读写CSV文件。它提供了一个简单的接口,可用于解析CSV文件、读取和写入CSV数据。它还支持自定义分隔符、行结束符和引号字符。
Libcsv:这是一个轻量级的C库,用于读取和写入CSV文件。它提供了一个简单的API,可用于解析CSV文件、读取和写入CSV数据。它支持自定义分隔符、行结束符和引号字符,并支持多种文本编码。
FastCSV:这是一个高性能的C++库,用于读取和写入CSV文件。它支持多种分隔符和文本编码,并提供了一个简单的API,可用于读取和写入CSV数据。
TinyCSV:这是一个非常小巧的C++库,用于读取和写入CSV文件。它只有一个头文件和一个源文件,易于集成到任何项目中。它支持自定义分隔符和行结束符,并提供了一个简单的API,可用于读取和写入CSV数据。
CSVstream:这是一个基于STL流的C++库,用于读取和写入CSV文件。它提供了一个简单的API,可用于解析CSV文件、读取和写入CSV数据。它支持自定义分隔符、行结束符和引号字符,并支持多种文本编码。
一般来说,使用基于流的解析器,例如 RapidCSV 和 Boost C++ 中的解析器,可能会带来一些性能损失,因为需要在运行时进行类型推断和转换操作。相比之下,使用基于模板的解析器,例如 CSVParser 和 ModernCppCSV,可以提供更高的性能和更好的类型安全性。
另外,一些库提供了多线程支持,例如 RapidCSV 和 Boost C++ 中的解析器,可以提高解析大型 CSV 文件的速度。而其他库可能会提供更多的便利性和灵活性,例如 Qt CSV,可以轻松地将 CSV 数据与 Qt 框架的其他部分进行集成。
C++处理HDF5文件的库
HDF5 是一种用于存储和处理大型科学和工程数据集的文件格式。C++ 中有几个流行的库可以用来处理 HDF5 文件。下面是其中一些库的简要介绍:
- HDF5 C++ API:HDF5 提供了一个基于 C++ 的 API,可以使用它来读取和写入 HDF5 文件。它是使用 HDF5 最原始的方式之一,因此在 C++ 中使用它需要一些手动管理资源和指针的工作。但是,它提供了对 HDF5 的完全访问,因此可以使用它来执行复杂的数据操作。
- H5CPP:H5CPP 是一个针对 C++ 的 HDF5 API,它试图通过简化 HDF5 API 调用来改善 HDF5 的可用性。它为 HDF5 提供了一个现代的 C++ 接口,可以使用它来创建、读取和写入 HDF5 文件。它还包括一些有用的特性,如异常处理和 RAII。
- HighFive:HighFive 是一个 C++ 的头文件库,提供了对 HDF5 C API 的封装,使其更易于使用。它提供了类似于 STL 的容器,可以用来读取和写入 HDF5 文件。它还包括支持属性和外部链接的功能,以及一些其他有用的特性。
- h5pp:h5pp 是一个基于 Modern C++ 的 HDF5 API,旨在提供一种简化、现代化的方法来读取和写入 HDF5 文件。它使用 RAII 和异常处理来管理 HDF5 对象,这使得使用 HDF5 变得更加安全和简单。它还支持类型转换、压缩、并行和属性等功能。
一般来说,使用 HDF5 C++ API 可以获得最快的性能,因为它直接与 HDF5 库进行交互。但是,这个库需要进行更多的手动管理和错误检查,可能会使代码更加冗长和复杂。
另一方面,H5CPP、HighFive 和 h5pp 等库为 HDF5 提供了现代 C++ 的封装,使其更加易于使用,但可能会带来一些性能损失。这些库通常提供了许多功能和特性,可以方便地进行数据集的读取和写入,同时还包括异常处理和资源管理等功能,这使得代码更加安全和简洁。
编码规范
注释
打开settings.json文件方法:
法1: enable koroFileHeader插件后输入cmd + p
法2: 设置里输入 code run
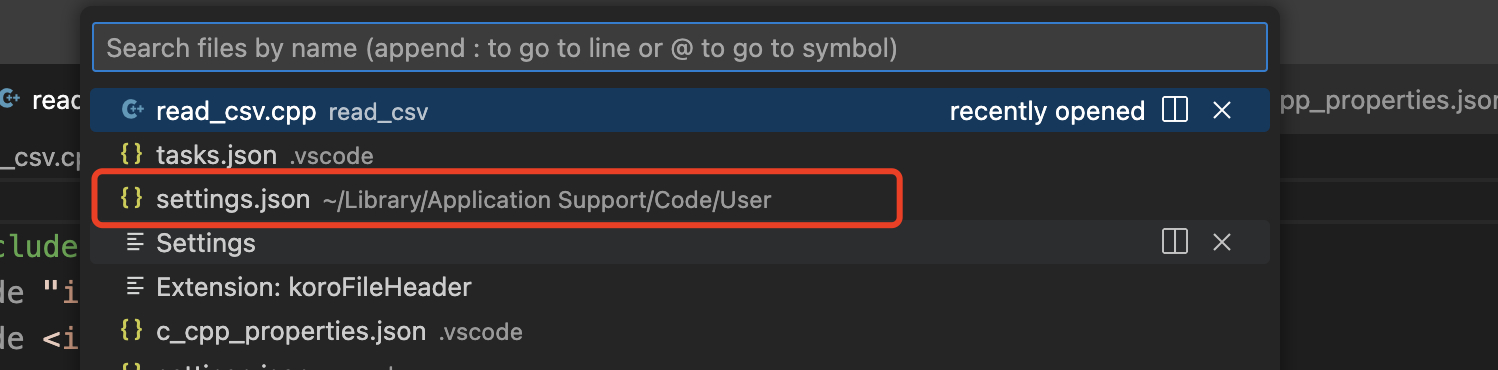
在vscode的setting.json【这个settings.json是全局设置文件,还有一个同名的settings.json .vscode 是工作区设置,仅应用于当前打开的工作区,其中可以包含特定于该工作区的设置,例如文件路径或项目配置。】中修改
相对路径
- 是rapidcsv的bug(正常不需要➕ ../)
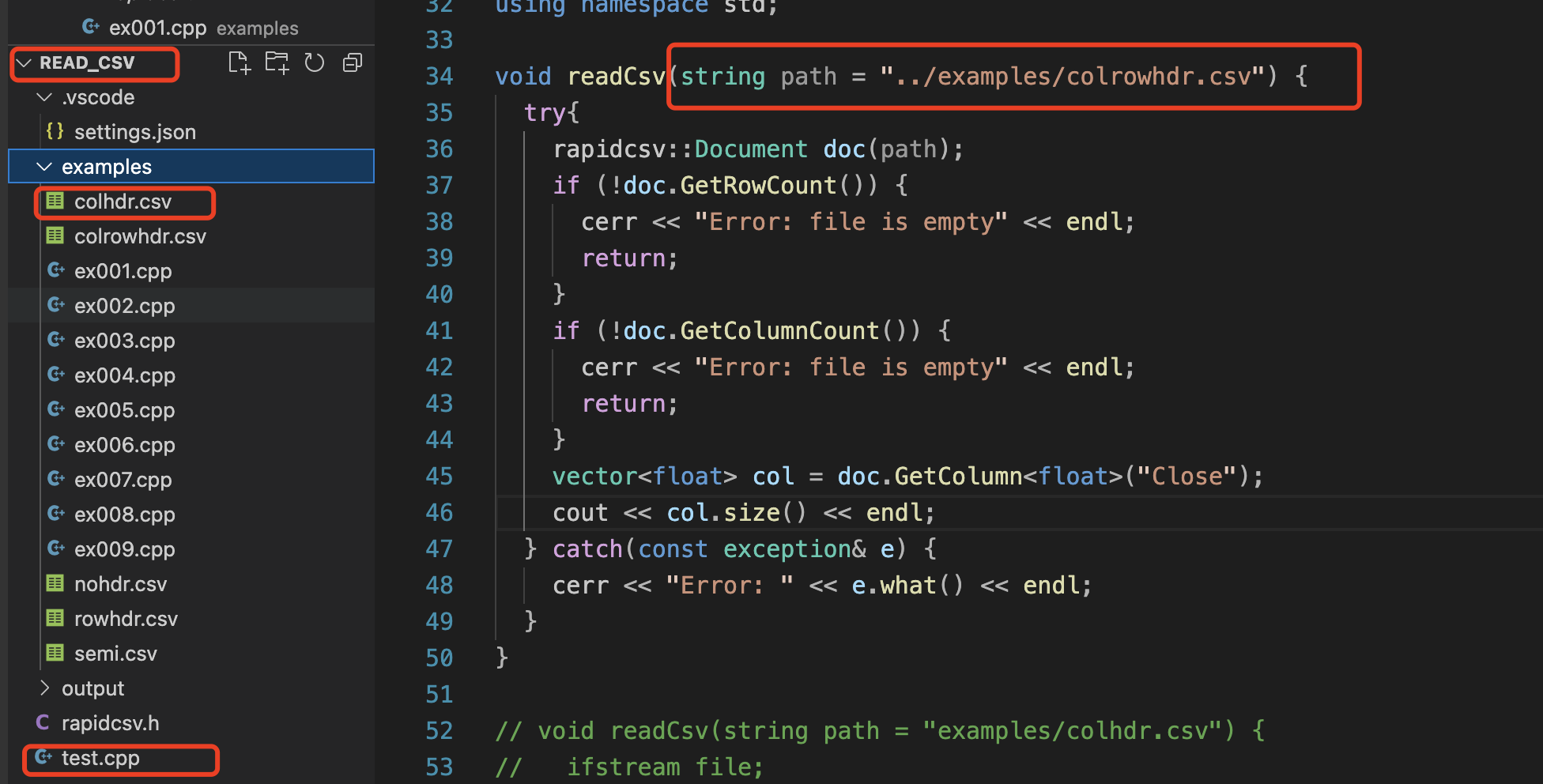
生成随机数据
import csv |
g++编译参数
g++ -g test.cpp -o test产生带调试信息的可执行文件,否则gdb无法执行g++ -O2 -o test.cpp test编译器优化-l 指定库文件, -L 指定库文件路径
// -l参数(小写)就是用来指定程序要链接的库,-l参数紧接着就是库名 |
- -I 指定头文件的搜索目录
// -I |
使用 c++11 标准编译
g++ test.cpp -std=c++11 test.cpp-Dname 定义宏name,默认定义内容为字符串“1’
|
Example
- |
如果想要将 swap.cpp 生成库文件并链接到main.cpp中
- 静态库
// 进入src目录下: |
- 动态库
// 进入src目录下 |
引入自己的头文件
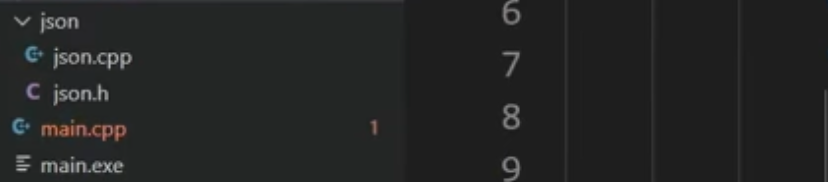
比如此时需要在main.cpp中运行包含同一目录下 json/json.cpp, 则需要
将setting.json的”code-runner.executorMap”处的”cpp”改为
"cd $dir && g++ -Ijson json/.*cpp $fileName -o $fileNameWithoutExt -std=c++17 && $dir$fileNameWithoutExt",在tasks.json 的 “args” 加上
"-Ijson", "json/*.cpp"
CMake
CMake语法
语法特性介绍
- 基本语法格式: 指令(参数 1 参数 2…)
- 参数使用括弧括起
- 参数之间使用空格或分号分开
- 指令是大小写无关的,参数和变量是大小写相关的
set(HELLO he11o.cpp) |
- 变量使用${}方式取值,但是在if 控制语句中是直接使用变量名
if(HELLO)
重要命令
cmake_minimum_required(VERSION 2.8.3) # 指定CMake的最小版本要求 |
# 定义工程名称,并可指定工程支持的语言 |
# 显式地定义变量 |
# 向工程添加多个特定的头文件搜索路径 相当于指定g++编译器的-i参数o |
# 向工程添加多个特定的库文件搜索路径 相当于指定g++编译器的-L参数 |
# 生成库文件 |
# 添加编译参数 |
# 生成可执行文件 |
# 为target添加需要链接的共享库 相同于指定g++编译器-l |
# 向当前工程添加存放源文件的子目录,并可以指定中间二进制和目标二进制存放的位置 |
# 发现一个目录下所有的源代码文件并将列表存储在一个变量中,这个指令临时被用来自动构建源文件列表 |
常用变量
略
CMake编译工程
CMake目录结构:项目主目录存在一个CMakeLists.txt文件
两种方式设置编译规则:
- 包含源文件的子文件夹包含CMakeLists.txt文件,主目录的CMakeLists.txt通过add_subdirectory添加子目录即可;
- 包含源文件的子文件夹未包含CMakeLists.txt文件,子目录编译规则体现在主目录的CMakeLists.txt中;
编译流程
在 linux 平台下使用 CMake 构建C/C++工程的流程如下:
- 手动编写 CmakeLists.txt。
- 执行命令
cmake PATH生成 Makefile(PATH是顶层CMakeLists.txt 所在的目录)。 - 执行命令
make进行编译
# important tips |
外部构建
将输出文件与源文件放到不同目录中
# 1.在当前目录下,创建build文件夹 |
Example

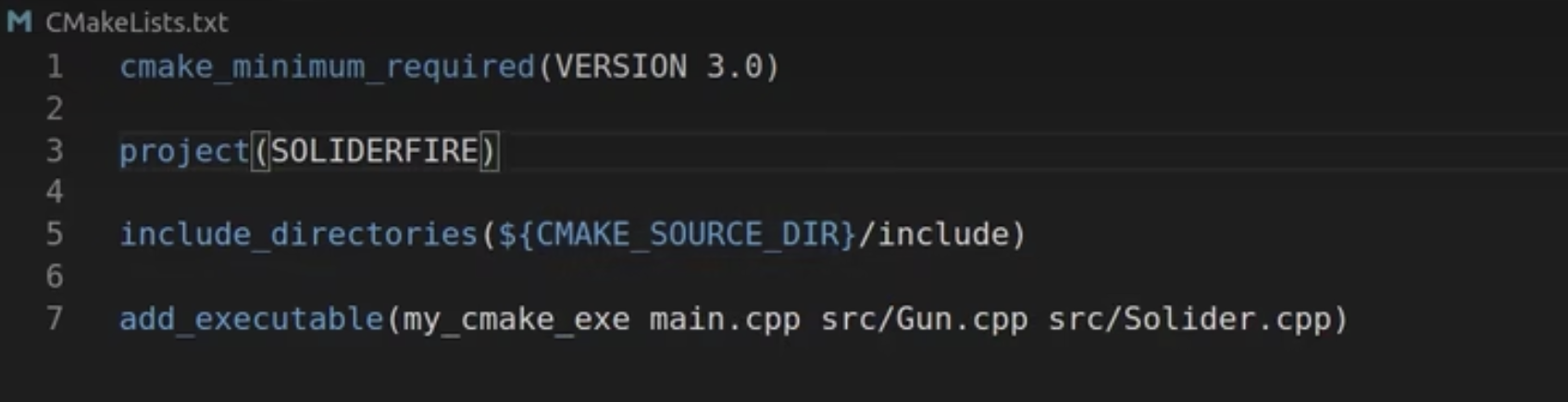
优化:
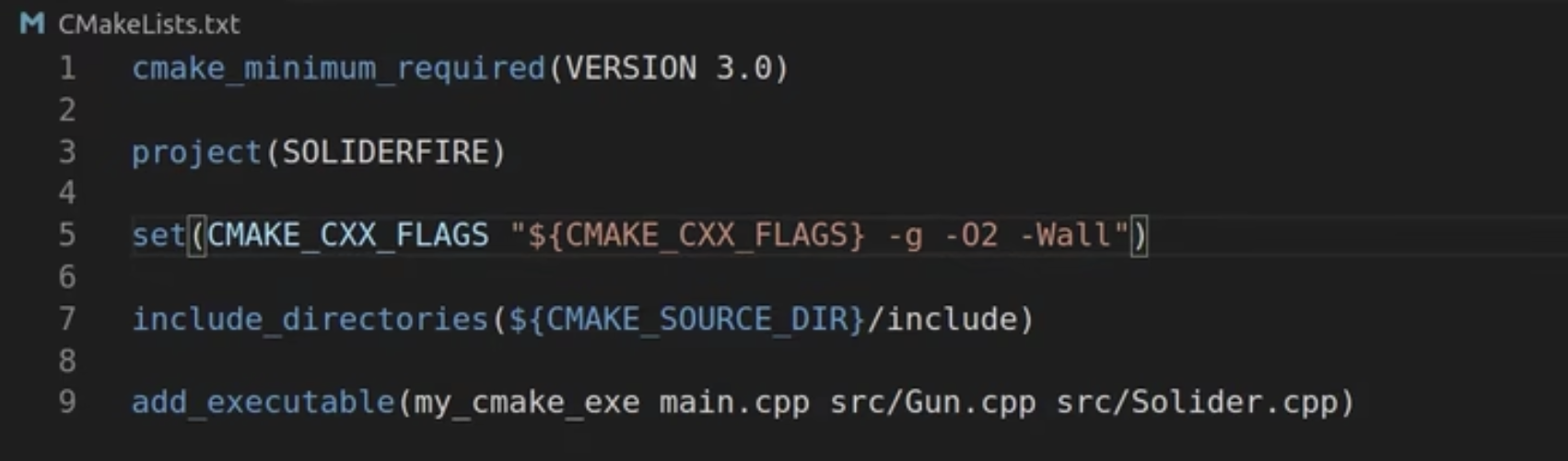
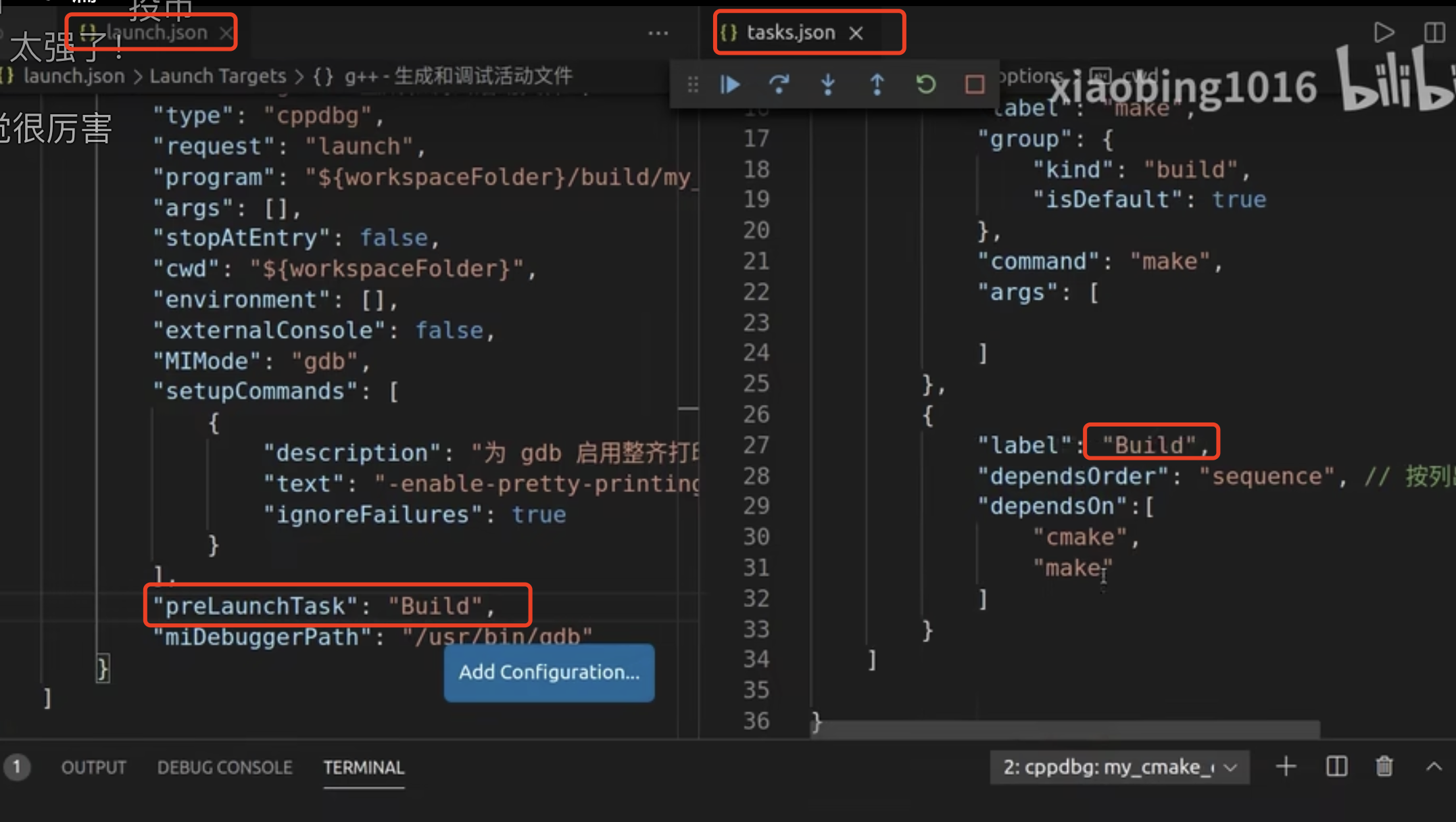
调试
- 需要在CMake.txt中删除
-O2参数,并加入一行set(CMAKE_BUILD_TYPE Debug) - 在launch.json里修改
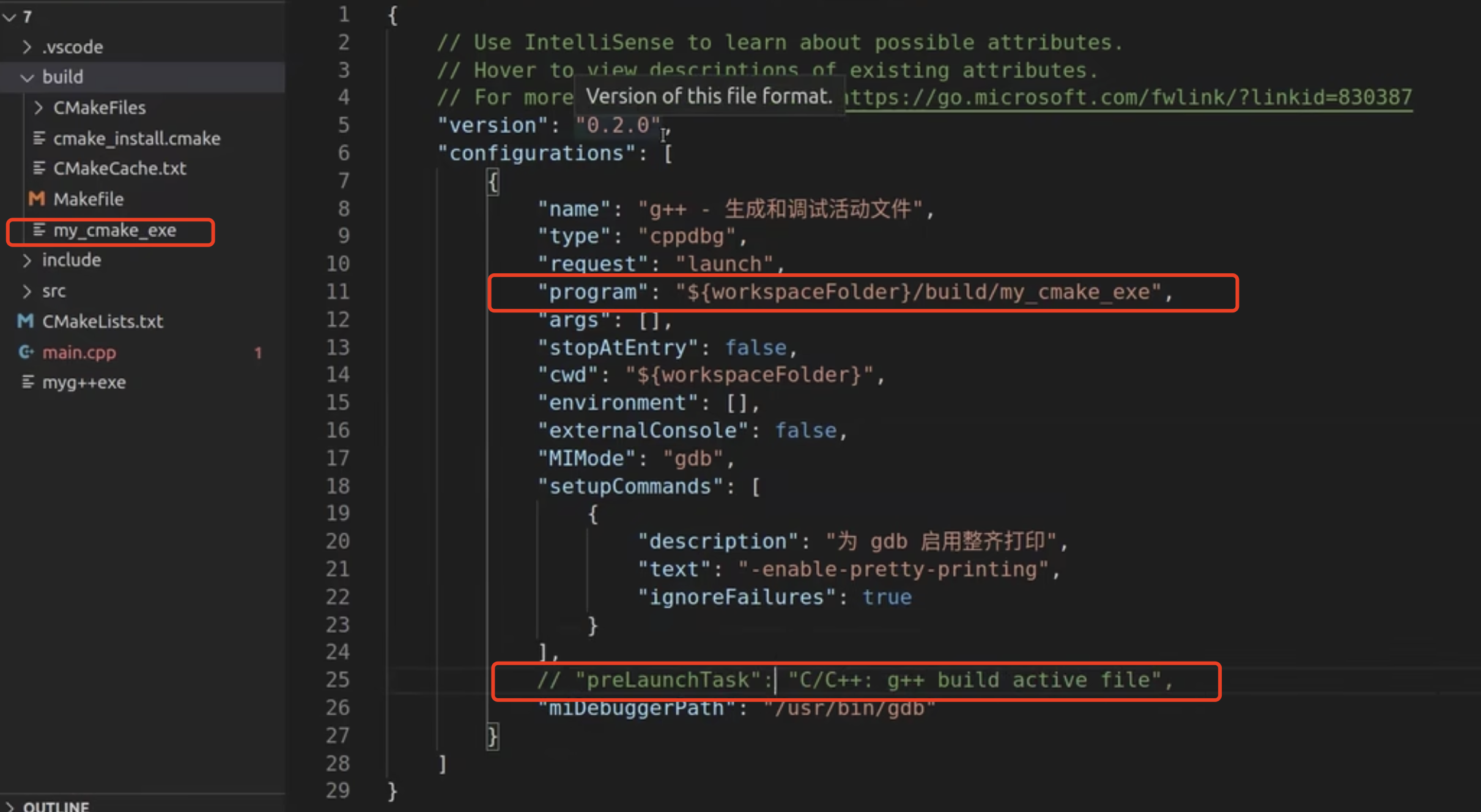
高级调试: