HDF5
HDF5文件组织和数据模型
HDF5文件以分层结构组织,其中包含两个主要结构:组和数据集。
- group:分组结构包含零个或多个组或数据集的实例,以及支持元数据(metadata)。
- dataset:数据元素的多维数组,以及支持元数据。
HDF5 Groups
一个 HDF5 group 包含0个或者多个 HDF5 对象. 一个 group 有两部分:
- 一个组头,包含组名和组属性列表
- 一个组符号表,它是属于组的HDF5对象的列表。
HDF5 Datasets
一个数据集存储在文件中,分为两部分:
数据集头 : 数据集头有解释数据集的数组部分所需的信息,以及描述或注释数据集的元数据(或指向元数据的指针)还包括对象的名称,维度,数字类型,有关数据本身存储在磁盘上的信息,以及用于加速访问数据集或维护文件完整性的库的其他信息。
一个数据集头中有四个基本信息类别:
name: 数据集名称
datatype : 原子数据类型和复合数据类型。原子数据类型可以是系统特定的或者原生的。所有的数据类型都可以命名
原生数据类型是指HDF5库中定义的一组基本数据类型,可以直接在HDF5数据集中使用。这些数据类型与常见的编程语言数据类型相对应,可以在不同平台和编程语言之间保持一致性, 如:
H5T_NATIVE_DOUBLE:平台本机双精度浮点数类型系统特定的数据类型是指HDF5库中定义的一组数据类型,这些数据类型是平台特定的,即它们的实现依赖于特定的操作系统和编译器。这些数据类型是HDF5库提供的附加数据类型,它们扩展了HDF5原生数据类型的功能,允许用户在不同平台上共享HDF5文件。如:
H5T_UNIX_D32BE:32位大端UNIX日期和时间类型。dataspace:描述数据集的维数,是可以动态变化的。它还可以描述数据集的部分,使得可以对选择进行部分I / O操作。 给定一个n维数据集,目前有四种方法进行部分选择:
- 选择一个逻辑上连续的n维hyperslab
- 选择由间距相等的元素或元素块(hyperlab)组成的非连续hyperlab。
- 选择多个hyperslab的并集
- Select a list of independent points (选择独立点列表)
hyperslab是指一个多维数据集的子集,由一个起始点和一个结束点定义的。可以被看作是数据集的一个切片或子矩阵
例如,对于一个二维数据集,一个hyperslab可以通过起始点(x1, y1)和结束点(x2, y2)来定义。
在HDF5中,可以使用Hyperslab Selection API来创建、读取和写入hyperslab。使用Hyperslab Selection API,可以通过指定起始点和结束点来选择数据集的子集,并对它们进行操作,而不需要读取整个数据集。这种方法可以大大提高HDF5数据集的读取和写入效率。
storage layout:两种存储布局移式:compact (紧凑型) 和 chunk(分块型)
紧凑存储用于数据量较小且可以直接存储在对象头中的情况
分块存储涉及将数据集划分为大小相等的“块”,这些“块”分别存储:
改善性能:分块允许高效地访问数据集的子集,即使子集不在数据集的正常存储顺序中。
支持压缩:可以对大型数据集进行压缩,并在访问数据集的子集时仍能实现良好的性能。
支持扩展:可以高效地沿任何方向扩展数据集的维度。
数据数组
HDF5 Attributes
此外,任何 group 或 dataset 都可能有一个相关的 attribute list (属性列表)。HDF5 attribute(属性) 是用户定义的HDF5结构,它提供关于HDF5对象的额外信息
压缩算法
HDF5自带ZLib和Szip开源压缩库
ZLib使用DEFLATE算法进行数据压缩和解压缩。它具有较高的压缩比和快速的解压速度,因此在许多应用中都被广泛使用,例如在HTTP协议中使用的Gzip压缩(底层也是DEFLATE)。ZLib库的API简单易用,且在许多编程语言中都有可用的绑定。
Szip是一种专为科学数据压缩而设计的库,它使用了基于多项式的算法来实现高效的压缩和解压缩。与ZLib相比,Szip可以在某些情况下提供更高的压缩比,但需要更多的计算资源来完成压缩和解压缩操作。Szip库通常用于处理大型科学数据集,如气象、卫星和天文数据。
HDF5支持自定义压缩算法,如Aec/Bzip/Lzf/LZ4等算法
Aec:全称为”Adaptive Entropy Coding”,是一种基于自适应算法的数据压缩算法。Aec算法的核心是根据输入数据的特征自适应调整压缩算法,从而实现高效的数据压缩和解压缩。Aec算法广泛用于计算机图像、音频和视频等多媒体数据的压缩。
Bzip:是一种广泛使用的数据压缩算法和程序,它使用Burrows-Wheeler转换和霍夫曼编码来实现高效的数据压缩。Bzip算法通常比Gzip算法提供更高的压缩比,但需要更多的计算资源和时间来完成压缩和解压缩操作。Bzip程序可以通过命令行或图形用户界面来使用,常用于Unix/Linux操作系统和Internet上的文件传输。
Lzf:Lzf全称为”Lempel-Ziv-Featherstone”,是一种高速的无损数据压缩算法。Lzf算法的核心是基于LZ77算法和滑动窗口技术,可以在快速压缩和解压缩数据的同时保持较高的压缩比。Lzf算法通常用于内存限制较严格的应用程序中,例如嵌入式系统和游戏开发。
LZ4:是一种高速的无损数据压缩算法,它可以在快速压缩和解压缩数据的同时保持较高的压缩比。LZ4算法的设计目标是在不损失压缩比的情况下提高压缩和解压缩的速度
*Gzip、Bzip和DEFLATE
DEFLATE算法是一种通用的无损数据压缩算法,而Gzip和Bzip是基于DEFLATE算法的扩展,它们各自适用于不同的场景和压缩需求。Gzip通常用于快速压缩和解压缩单个文件,而Bzip通常用于需要更高压缩比的场景,例如压缩大型数据集和备份文件
读写原理
HDF5文件的底层原理是基于B树和B+树的数据结构。HDF5文件包含一个根组(Root Group)和多个子组(Sub Group)。每个组都包含一个或多个数据集(Dataset),每个数据集又包含一个或多个数据元素(Data Element)。数据元素可以是各种数据类型,例如整数、浮点数、字符串、复数等等。
当我们打开一个HDF5文件时,文件被映射到内存中,并分配一个文件句柄(File Handle)。文件句柄用于跟踪文件的打开和关闭,以及在文件中定位数据元素的位置。在内存中,文件的组织结构被表示为一个树形结构,其中根组是树的根节点。当我们访问HDF5文件中的数据时,程序通过递归遍历树来查找需要的数据元素。
为了提高文件的读取和写入速度,HDF5使用了一种称为“分块(Chunking)”的技术。在分块技术中,每个数据集被分成多个块,每个块可以独立地读取或写入。这使得HDF5文件能够高效地处理大型数据集,因为只有需要的数据块才会被读取或写入,而不需要将整个数据集加载到内存中。
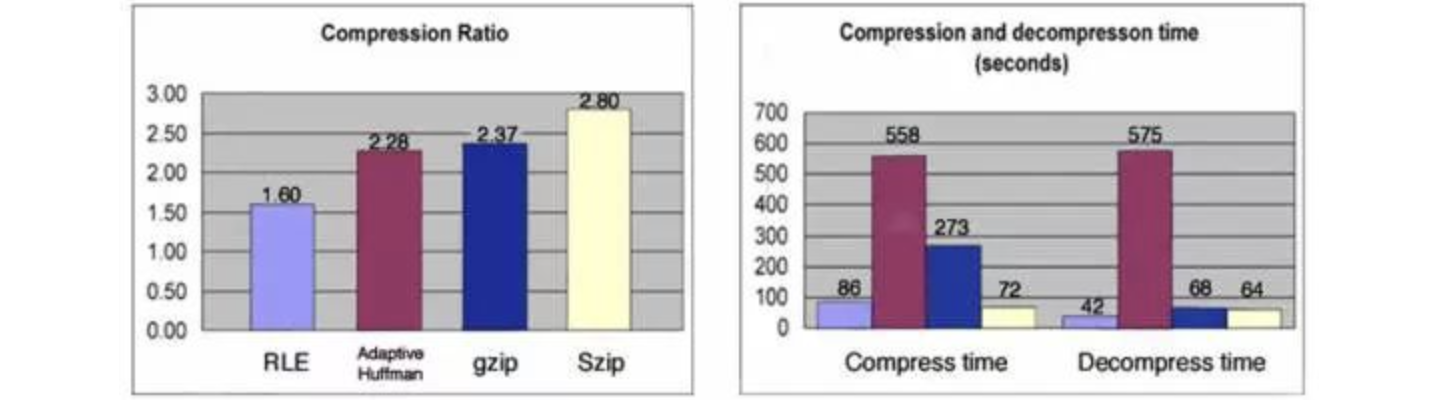
测试性能
测试服务器为双核超线程Intel(R) Xeon(R) E5-2640 CPU 32GB内存。
CSV文本文件中存储盘口快照的数据,每天约4800行,占用空间1.8MB。
HDF5文件以Gzip算法(Level4)存储数据,每天的数据约占用空间0.25MB。
用Python读取HDF5文件,对每天的数据生成numpy.array数据结构,约耗时5.5ms
用Python读取HDF5文件,对每天的数据生成pandas.DataFrame数据结构,约耗时9.0ms
用Python读取CSV文件,对每天的数据生成pandas.DataFrame数据结构,约耗时35~40ms
从数据对比可以看出,HDF5文件的存储效率和读取速度均远优于常规的文本文件。
XZ
简介
XZ Utils是免费的通用数据压缩软件,具有高压缩比。XZ Utils是为类似posix的系统编写的,但也适用于一些不那么posix的系统。XZ Utils是LZMA Utils的继承者。压缩代码的核心是基于LZMA SDK的,但是为了适合XZ Utils,它已经被修改了很多。目前主要的压缩算法是LZMA2,它在.xz容器格式中使用。对于典型的文件,XZ Utils创建的输出比gzip小30%,比bzip2小15%。
XZ Utils由几个组件组成:
liblzma:是一个压缩库,其API类似于zlib
xz:是一个命令行工具,语法类似于gzip
xzdec:是一个仅用于解压缩的工具,比功能齐全的xz工具小
一组shell脚本(xzgrep、xzdiff等):从gzip改编而来,以便于查看、编辑和比较压缩文件
LZMA Utils命令行工具:简化了从LZMA Utils到XZ Utils的转换。
虽然liblzma有一个类似zlib的API,但liblzma不包括任何文件I/O函数。将计划有一个单独的I/O库,它将通过易于使用的API抽象处理.gz、.bz2和.xz文件。
.xz文件
.xz 文件格式是压缩流的容器格式。 没有归档功能,也就是说,.xz 格式只能保存单个文件,就像 gzip 和 bzip2 分别使用的 .gz 和 .bz2 文件格式一样。
与其他流压缩格式相比,.xz 格式提供了一些高级功能。 同时, 保持足够简单,可以在许多嵌入式系统中使用。 以下是功能摘要:
可流式传输:总是可以在管道中创建和解压缩.xz文件;不需要寻址.xz文件格式的设计使得可以在没有定位文件特定位置的情况下,顺序地压缩和解压缩数据流。
.xz文件格式使用了LZMA2压缩算法。该算法使用连续的数据块进行压缩,每个块都是连续的,可以流式地处理。在使用LZMA2算法压缩时,整个文件被分成多个数据块,每个数据块都是完整的数据,而不是分散的碎片。因此,无论是在创建还是解压缩.xz文件时,都不需要随机访问文件中的特定位置,可以直接从输入流中读取数据并将输出写入输出流中。
这种特性使得.xz文件在处理大型数据集或进行网络传输时非常有用,因为可以减少磁盘I/O和网络I/O的需求,提高效率和性能。在管道中使用.xz文件进行数据传输和处理时,不需要将数据写入磁盘,而是可以直接流式传输,这可以进一步提高效率和性能。
随机存取读取:数据可以被拆分成独立的压缩块。 每个 .xz 文件都包含块的索引,当块大小足够小时,支持随机访问读取
多个过滤器(算法):可以添加对新过滤器的支持,因此每次开发新算法时都不需要新的文件格式。 开发人员可以将开发人员特定的过滤器 ID 空间用于实验性过滤器。
在 .xz 文件中,有多个不同的压缩算法,每个算法都有一个独特的 ID。这些算法被称为“过滤器”,因为它们过滤并改变原始数据,以达到压缩的目的。
如果有开发人员想要添加一个新的压缩算法到 .xz 文件中,他们不需要创建一个全新的文件格式。相反,他们可以使用已经存在的文件格式,然后添加自己的过滤器 ID 来支持他们的算法。这就像是在一个现有的家里添加一间新房间,而不是建造一个全新的房子。这样做的好处是,文件格式的基础结构保持不变,但是仍然可以添加新的算法,以适应不断发展的技术和需求。
过滤器链接:最多可以链接四个过滤器,这与 UNIX 命令行上的管道非常相似。 链接可以提高某些文件类型的压缩率。 不同的过滤器链可以用于每个独立压缩的块。
在 .xz 文件中,最多可以将四个过滤器连接在一起,这就像在 UN*X 命令行中进行管道操作一样。将多个过滤器连接在一起可以改善某些文件类型的压缩比。在 .xz 文件中,每个独立压缩块都可以使用不同的过滤器链。这个特性可以提供更灵活的压缩选项,可以根据文件类型和需要来选择不同的过滤器链。这也意味着开发人员可以根据需要定制自己的过滤器链,以便在压缩不同类型的文件时获得最佳的压缩效果
完整性检查:所有标头的完整性始终受 CRC32 保护。 可以使用CRC32、CRC64、SHA-256 验证实际数据的完整性,也可以完全省略校验。 将来可能会添加新的完整性检查,但不可能像过滤器 ID 那样使用特定于开发人员的检查 ID。
连接:就像 .gz 和 .bz2 文件一样,可以按原样连接 .xz 文件。 解压器可以解压一个连接的文件,就好像它是一个普通的单流 .xz 文件一样。
填充:二进制零可以附加到 .xz 文件以填充它们以填充例如 备份磁带上的一个块。 填充需要是四个字节的倍数,因为每个有效的 .xz 文件的大小都是四个字节的倍数。
压缩算法-LZMA2
LZMA2是一种压缩算法,是LZMA压缩算法的改进版本。它使用一种数据压缩技术,可以通过去除数据中的冗余信息来减小数据的大小,从而降低存储和传输数据的成本。LZMA2在处理大型文件时具有较高的压缩比,但在处理小型文件时可能不如其他算法效率高。它通常用于归档和备份数据,并且被广泛应用于许多数据压缩工具中。
*liblzma和LZMA
LZMA是一种压缩算法,而liblzma是用于实现LZMA算法的开源库, 其中还实现了其他压缩算法
LZMA是一种压缩算法,它使用了LZ77算法和霍夫曼编码,被广泛用于压缩归档文件,如.tar、.gz和.xz等。
而liblzma则是一个开源的、实现LZMA算法的库。它提供了压缩和解压缩LZMA数据的函数,以及对不同格式的压缩文件进行读写的函数。liblzma还提供了对其他压缩算法的支持,如PPMd和BCJ。
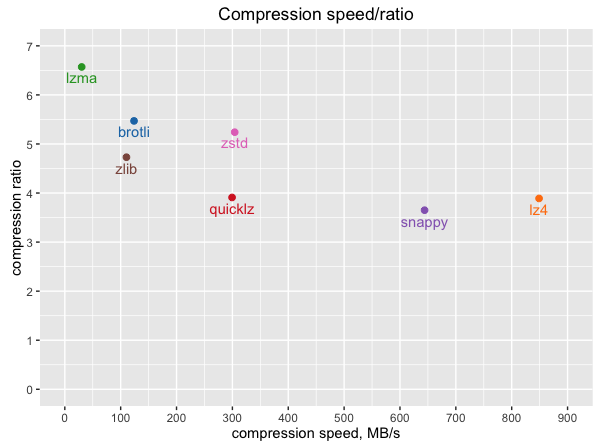
多种压缩算法对比
Szip
Szip是一种专门用于科学数据压缩的算法,它基于运行长度编码和哈夫曼编码,能够对科学数据进行高效的压缩。相对于其他压缩算法,Szip具有以下优点:
- 压缩速度快:Szip在压缩速度方面比Gzip更快,适用于大规模数据集的压缩。
- 压缩比高:Szip在压缩比方面优于Gzip,特别是对于科学数据等有大量重复模式的数据集。
Szip适用于科学数据等有大量重复模式的数据集
Bzip2
Bzip2是一种高压缩比的算法,它采用了Burrows-Wheeler变换、Move-to-Front编码和哈夫曼编码等技术来实现高压缩比。相对于其他压缩算法,Bzip2具有以下优点:
- 压缩比高:Bzip2在压缩比方面优于Gzip和Szip。
- 压缩率可调:Bzip2允许用户选择不同的压缩级别来实现不同的压缩比和速度。
Bzip2适用于需要高压缩比的场景
Gzip
Gzip是一种基于DEFLATE算法的数据压缩算法,通常用于快速压缩和解压缩数据。相对于其他压缩算法,Gzip具有以下优点:
- 压缩速度快:Gzip在压缩速度方面比Bzip2更快,适用于对速度要求较高的场景。
- 压缩比适中:Gzip在压缩比方面适中,通常可以在快速压缩和解压缩数据的同时实现较好的压缩比。
Gzip适用于快速压缩和解压缩数据的场景
ZSTD
ZSTD是一种现代的高压缩比压缩算法,由Facebook开发。它使用可调整的压缩级别,可以在快速压缩和较低压缩比之间进行权衡。ZSTD还支持多线程压缩和解压缩,以提高性能。
LZMA
LZMA是一种基于LZ77算法和算术编码的压缩算法,它的压缩率很高,但压缩速度较慢。LZMA适用于需要高度压缩的数据,例如操作系统安装程序和归档文件等。
LZMA2
LZMA2是LZMA算法的改进版本,由Igor Pavlov进行了修改和优化。它比LZMA更快,需要更少的内存,并提供了更好的压缩比。LZMA2是许多压缩工具,如7-Zip和WinZip的默认压缩算法。
如果需要高度压缩的数据,可以选择LZMA。当然,最好的选择还需要考虑具体的使用场景和需求。
zlib
zlib是一种流压缩算法,常用于HTTP、PNG和ZIP等协议和文件格式中。zlib的压缩速度快,但压缩率较低,适用于需要快速传输或存储大量数据的场景。
如果需要快速传输或存储大量数据,可以选择zlib;
brotli
brotli是由Google开发的一种压缩算法,旨在提供比zlib更好的压缩率和更快的压缩速度。brotli算法在压缩静态文本、HTML、CSS和JavaScript等文本文件方面表现较好,但在压缩二进制文件等非文本文件方面表现较差。
如果需要压缩文本文件,可以选择brotli;
lz4
lz4是一种快速压缩算法,其压缩速度比LZMA2快得多,但压缩率相对较低。lz4适用于需要快速压缩和解压的场景,例如实时通信和实时数据备份等。
多种算法原理
Huffman编码:
DEFLATE GZIP ZLIB ZIP LZMARLE(Run length encoding) 算法原理:
AAAAAABBCDDEEEEEF -> A6B2C1D2E5F1
RLE经常用于压缩图像文件等等,但是其缺点也很明显,比如说如果你是ABCDABCD,那么此算法就会把他压缩成A1B1C1D1A1B1C1D1,这样一来没有减小反而还增大了LZ77算法核心思想:
如果文件中有两块内容相同,那么只要知道前一块的位置和大小,我们就可以确定后一块的内容,我们可以用(两者之间的距离,相同内容的长度)这样的信息来替换后一块内容。由于(两者之间的距离,相同内容的长度)这一对信息的大小小于被替换内容的大小,所以文件得到了压缩。例如有一个文件的内容如下:
http://www.baidu.com http://www.qq.com其中有些部分的内容,前面已经出现过了,下面用()括起来的部分就是相同的部分:
http://www.baidu.com (http://www.)qq(.com)我们使用 (两者之间的距离,相同内容的长度) 这样一对信息,来替换后一块内容:
http://www.baidu.com (21,11).qq(18,4)
区间编码:
LZMA
将消息(message)中的所有字符编码成一个数字
假设我们编码这样的一串信息“AABA<EOM>”,'<EOM>'是结束符(end-of-message)
在这个例子中,假设解码器已经知道编码器使用的是五位的十进制数字(range=[0,100000))和字符的概率分布{A:60, B:20,
A: [0,60000)
B: [60000, 80000)
<EOM>: [80000,100000)
第一个字符是’A’,因此区间可以缩小为[0,60000)。在编码’A’之后,可以继续将区间分解为三个子区间。
AA: [0,36000)
AB: [36000, 48000)
A<EOM>: [48000,60000)
编码完前两个字符后,区间变为[0,36000)。第三个字符依然有三个选择。
AAA: [0,21600) // 7200 * 3
AAB: [21600, 28800) // 7200
AA<EOM>: [28800,36000) // 7200
第三个字符’B’被编码完成后,区间变为[21600,28800)。继续进行第四个字符的编码选择。
AABA: [21600,25920)
AABB: [21590, 27360)
AAB<EOM>: [27360,28800)
编码第五个字符
AABAA: [21600,24192)
AABAB: [24192, 25056)
AABA<EOM>: [25056,25920)
'<EOM>'是我们的最后一个字符,所以最终的区间为[25056,25920),因为所有的以'251'开头的十进制五位数都在这个区间内,所以我们可以使用'251'来表示原始信息**'AAB<EOM>'**