概览
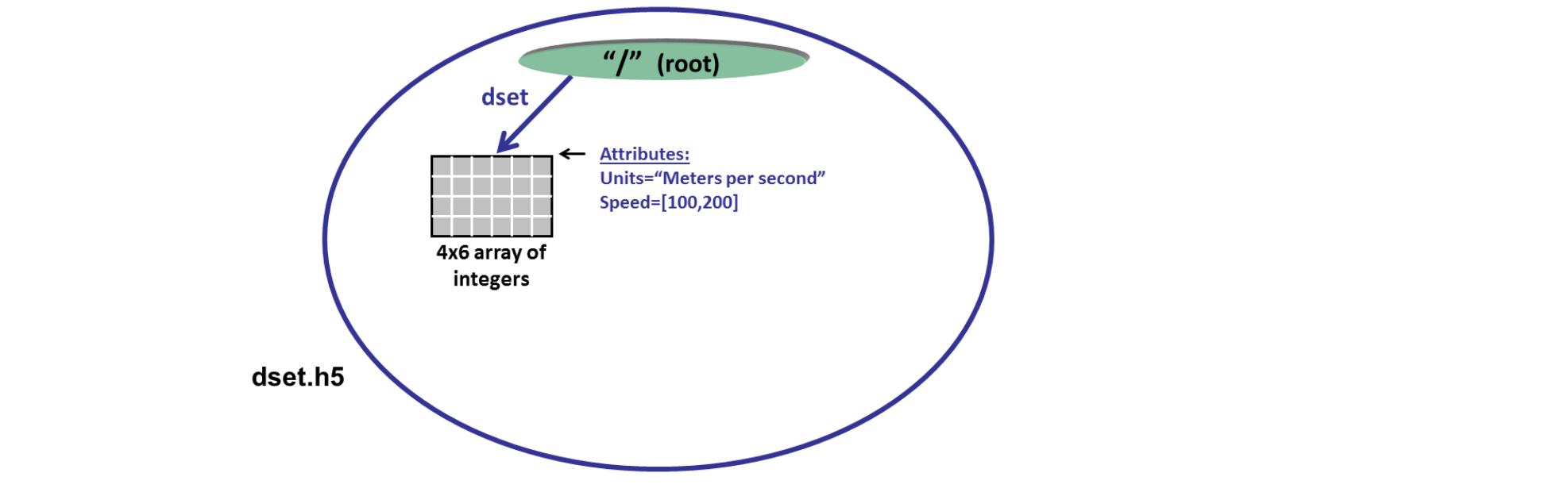
总体文件组织结构
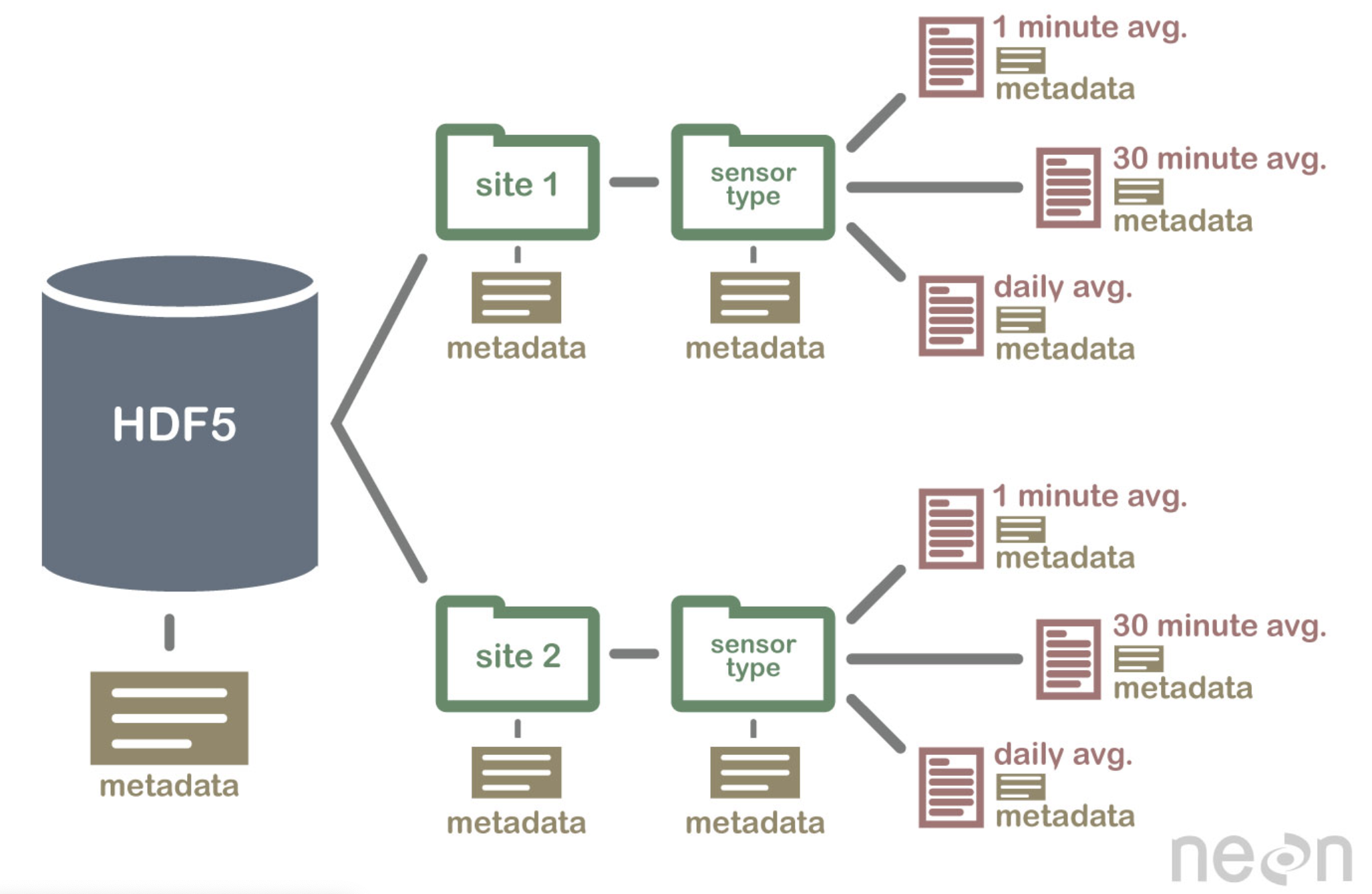
允许数据切片
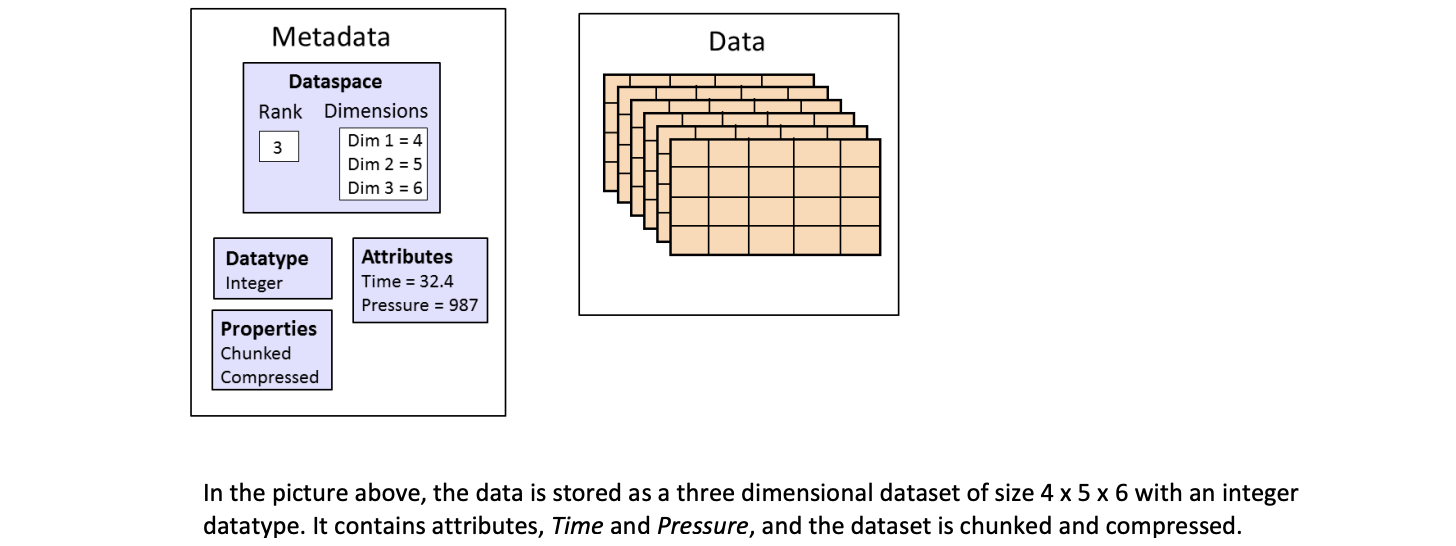
HDF5格式是一种压缩格式。HDF5中包含的所有数据的大小进行了优化,使整体文件大小更小。然而,即使经过压缩,HDF5文件通常也包含大数据,因此仍然相当大。HDF5的一个强大属性是数据切片,通过它可以提取数据集的特定子集进行处理。这意味着不需要将整个数据集读入内存(RAM); 允许更有效地处理非常大的(千兆字节或更多)数据集
HDF4和HDF5
The HDF Group 开发的两种不同的文件格式和库,用于存储和处理科学数据集。以下是它们之间的主要区别:
- 数据模型:HDF4采用传统的“数据集-属性”模型,而HDF5采用了更灵活的“组-数据集-属性”模型。这意味着在HDF5中,可以将数据集组织成任意的树形结构,而不仅仅是一个平面的网格状结构。
- 性能:HDF5在数据存取和压缩方面比HDF4更快。HDF5还具有更好的并行I/O性能,可处理更大的数据集,并且支持更多的文件大小和元素数量限制。
- API和库:HDF5提供了一套全新的API和库,与HDF4不兼容。这些API和库提供了更多的功能和灵活性,例如:更好的错误处理、更好的元数据管理、更好的过滤器支持、更好的分块和压缩等等。
- 跨平台支持:HDF5支持多种操作系统和处理器体系结构,包括Windows、Linux、Mac OS X、Solaris、IBM AIX等。HDF4则没有与现代操作系统的广泛兼容性。
HDF5是一个更现代、更强大和更可扩展的文件格式和库,比HDF4更适合处理大型科学数据集。
1⃣️Disk File Format
Introduction
HDF5文件对用户显示为有向图。该图的节点是HDF5 api公开的高级HDF5对象:
- 组Group
- 数据集 Datasets
- 命名数据类型 Named Datatypes
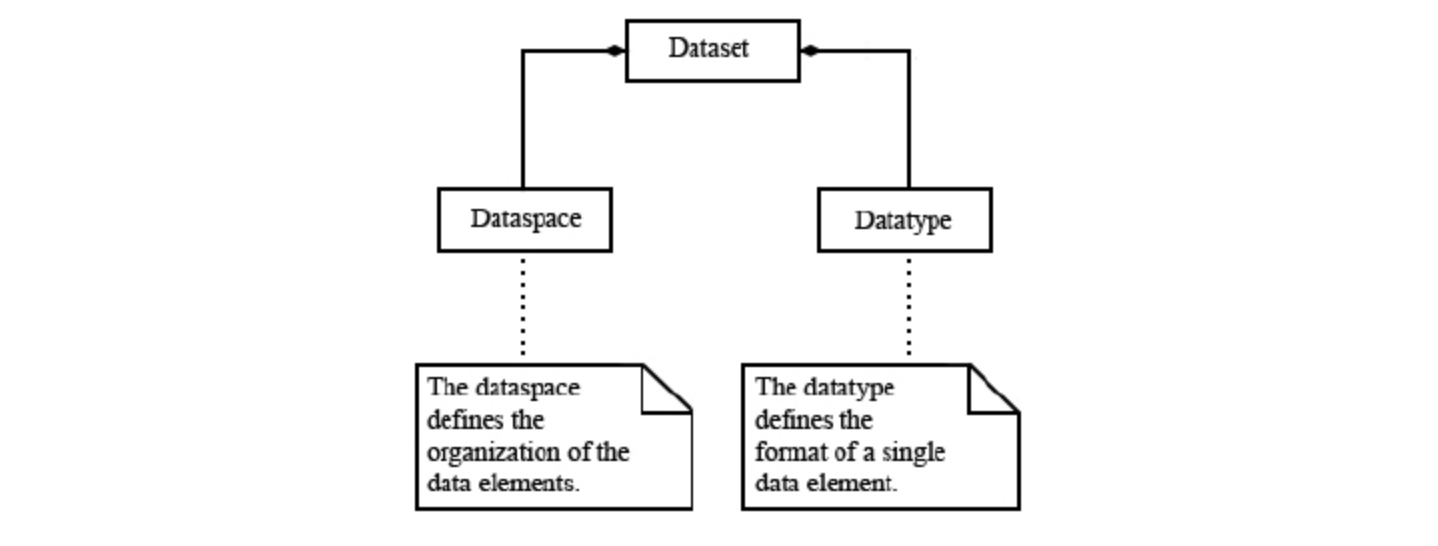
HDF5文件是一种用于存储和组织大型和复杂数据集的二进制文件格式。在最低级别上,HDF5文件由以下对象组成:
- A super block 超级块:是HDF5文件中的第一个对象,包含有关文件的元数据,如文件格式版本、各种数据结构的大小和根对象的位置等。
- B-tree nodes B树节点:用于组织和索引存储在文件中的数据。它们可以包含符号节点或原始数据块。符号节点存储有关HDF5对象的信息,例如名称、类型和位置,而原始数据块存储实际的数据值。
- Object headers 对象头:包含有关HDF5对象的元数据,例如大小、类型和创建时间。文件中的每个对象都有一个相关联的对象头。
- A global heap 全局堆:全局堆是用于管理大型可变大小数据的内存分配的数据结构。它用于存储与HDF5对象相关的小型元数据,例如其属性和创建属性。
- Local heaps 本地堆:本地堆类似于全局堆,但用于存储与特定HDF5对象相关的元数据。每个对象都可以有自己的本地堆。
- Free space 空闲空间:当在HDF5文件中添加、修改或删除数据时,可以创建空闲空间。这些空闲空间由空闲空间管理器管理,它跟踪文件中的可用空间,并允许在这些空闲区域中存储新数据。
级别0包含用于标识和定义文件信息的基本信息。
第1级信息包含文件中许多对象(如b树和堆)共享的文件片段的信息。
第2层是文件的其余部分,包含所有数据对象,每个对象被划分为头信息(也称为元数据)和数据。
以下布局表中各个字段的大小是通过查看字段在表中跨越的列数来确定的。有三种例外情况:(1)可以通过在括号中指定大小来覆盖大小,(2)地址的大小由超级块中的偏移量大小字段决定,并在本文档中用上标’O’表示,(3)长度字段的大小由超级块中的长度大小字段决定,并在本文档中用上标’L’表示。
以下所有字段的值都应被视为无符号整数,除非在字段的描述中另有说明。此外,所有元数据字段都以小端字节顺序存储。
Level 0 - 文件元数据
超级块
超级块由文件签名、超级块和组版本号、用于描述文件内项目的偏移量大小和长度值的信息、每个组页面的大小以及文件中根对象的组条目组成。
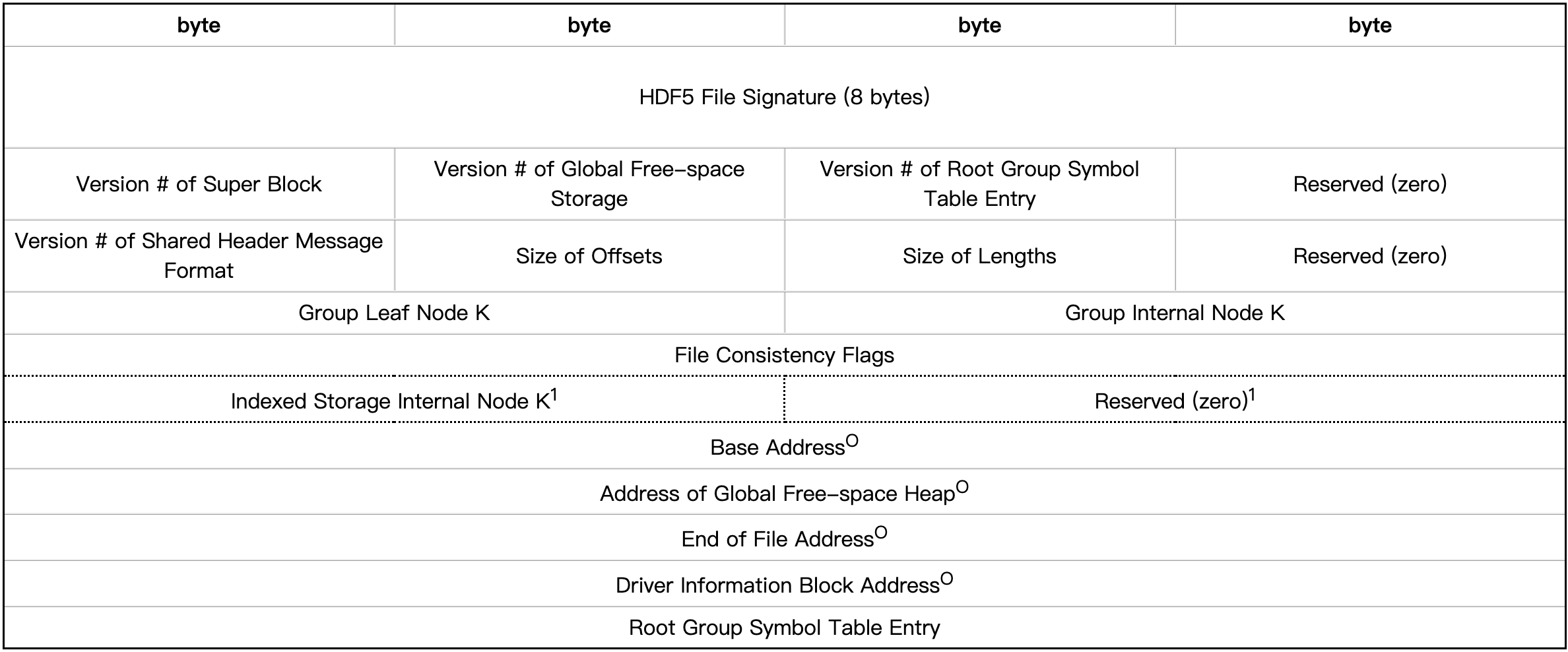
(上表中带“O”号的项目为在“Size of Offsets”中指定的大小) (上表中带“1”的项目为超级块第1版新增功能)
| Field Name | Description |
|---|---|
| HDF5 File Signature | 文件签名是一种数据完整性检查的方法,用于确保文件在传输或存储过程中没有被损坏或篡改。在HDF5文件中,文件签名存储在超级块中,固定8字节数组,表示文件的唯一标识符。每当文件被打开时,HDF5库都会检查文件签名是否正确,以确保文件的完整性。文件签名还可以用于帮助区分不同的HDF5文件。如有多个HDF5文件,并且它们都包含相同的元数据信息,但是您不确定它们是否是同一个文件,那么可以使用文件签名进行比较。 |
| Version # of Super Block | 该值用于确定超级块中信息的格式。当超级块中的信息格式发生变化时,版本号将增加到下一个整数,并可用于确定超级块中的信息如何格式化。 |
| Version # of Free-space Storage | 当前该字段中唯一有效的值是’0’,这表示空闲空间索引的格式如后文所述 |
| Version # of Root Group Symbol Table Entry | 用于确定根组符号表项中信息的格式。当该字段中信息的格式发生更改时,版本号将增加到下一个整数,并可用于确定如何格式化该字段中的信息。当前该字段中唯一有效的值是’0’,它表示根组符号表项的格式如后文所述。 |
| Version #of Shared Header Message Format | 此值用于确定共享对象头消息中信息的格式。由于共享报头消息的格式不同于其他私有报头消息,因此使用版本号来标识格式的更改。当前该字段中唯一有效的值是’0’,这表明共享头消息的格式后文所述。 |
| Size of Offsets | 内容是字节数,该字节数是此HDF5文件中数据块能被允许的的最大偏置字节数 |
| Size of Lengths | 用于存储对象大小的字节数 |
| Group Leaf Node K | 每个组B树的叶子节点将至少有这么多条目,但不超过两倍。 |
| Group Internal Node K | b组树的每个内部节点至少有这么多条目,但不超过这个数的两倍。 |
| File Consistency Flags | 文件一致性标志: 位0设置表示打开文件进行写访问。位1表示该文件已经过一致性校验,并保证与本文档定义的格式一致。位2-31被保留以备将来使用。 |
| Indexed Storage Internal Node K | 索引存储b树的每个内部节点至少有这么多条目,但不超过两倍。 |
| Base Address | 这是文件中HDF5数据的第一个字节的绝对文件地址。除非另有说明,所有其他文件地址都是相对于这个基址的。 |
| Address of Global Free-space Index | 还未定义 |
| End of File Address | 这是所有HDF5数据结束后的第一个字节的绝对文件地址。它用于确定文件是否被意外截断,并作为一个地址,如果未使用空闲列表中的空间,则可以在此进行文件数据分配。 |
| Driver Information Block Address | 这是文件驱动程序信息块的相对文件地址,其中包含重新打开文件所需的特定于驱动程序的信息。如果没有驱动程序信息阻塞,那么这个条目应该是[未定义的地址] |
| Root Group Symbol Table Entry | This is the symbol table entry of the root group, which serves as the entry point into the group graph for the file. |
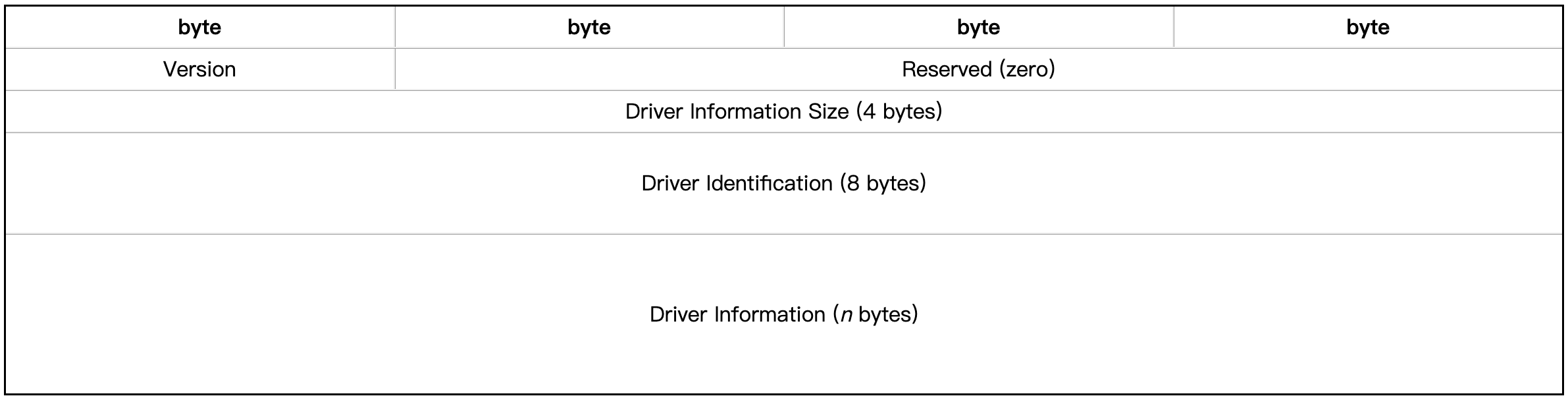
文件驱动信息
在HDF5文件中,驱动程序负责管理文件的读取和写入,处理文件的元数据和数据块的存储和检索。每个驱动程序都有其自己的特定需求和功能,因此需要在文件中记录驱动程序的信息。DIB中的信息允许HDF5库使用正确的驱动程序打开文件,以确保文件能够正确地读取和写入。
Level 1 - 文件基础结构
B-link Tree Node
B-link树允许灵活存储对象,这些对象往往以不连续的方式增长。
由文件格式实现的B-link树所包含的键数比子键数多一个。换句话说,b树节点的每个子指针都有一个左键和一个右键。内部节点的指针指向子树,而叶节点的指针指向符号节点和原始数据块。除了这个区别之外,内部节点和叶节点是相同的。
我的理解:
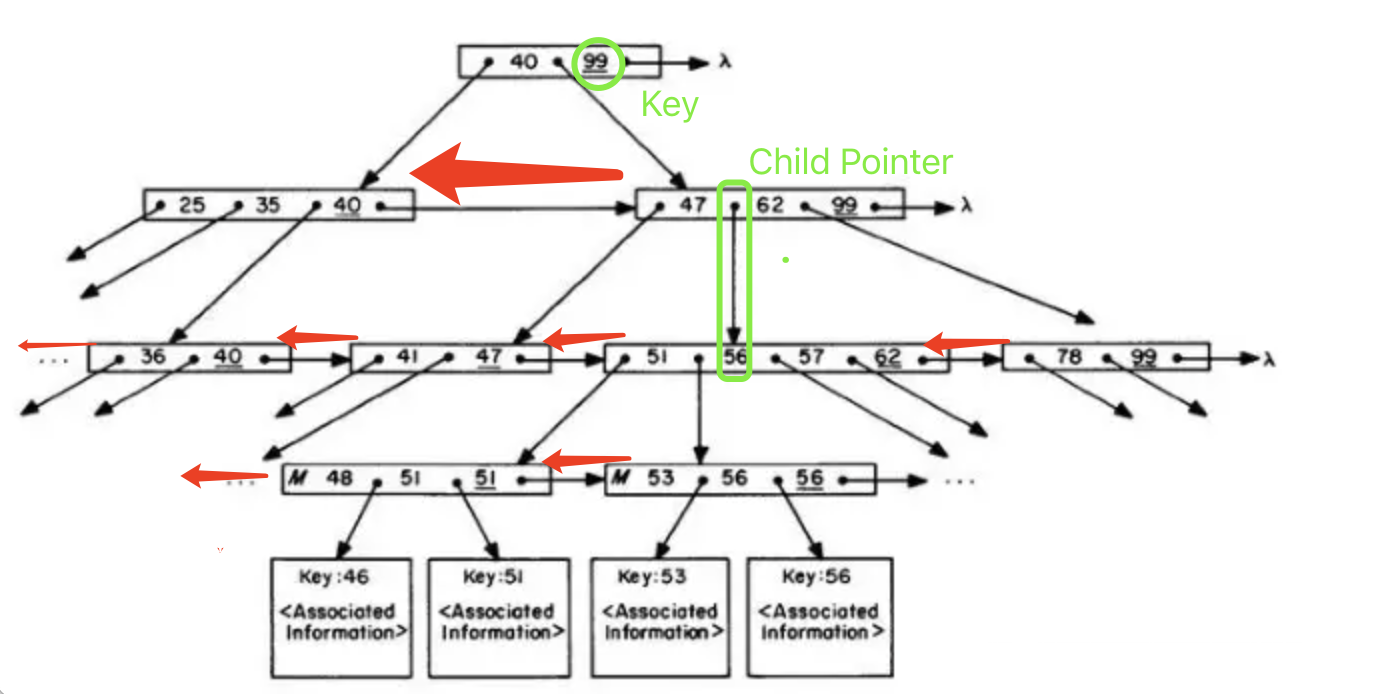
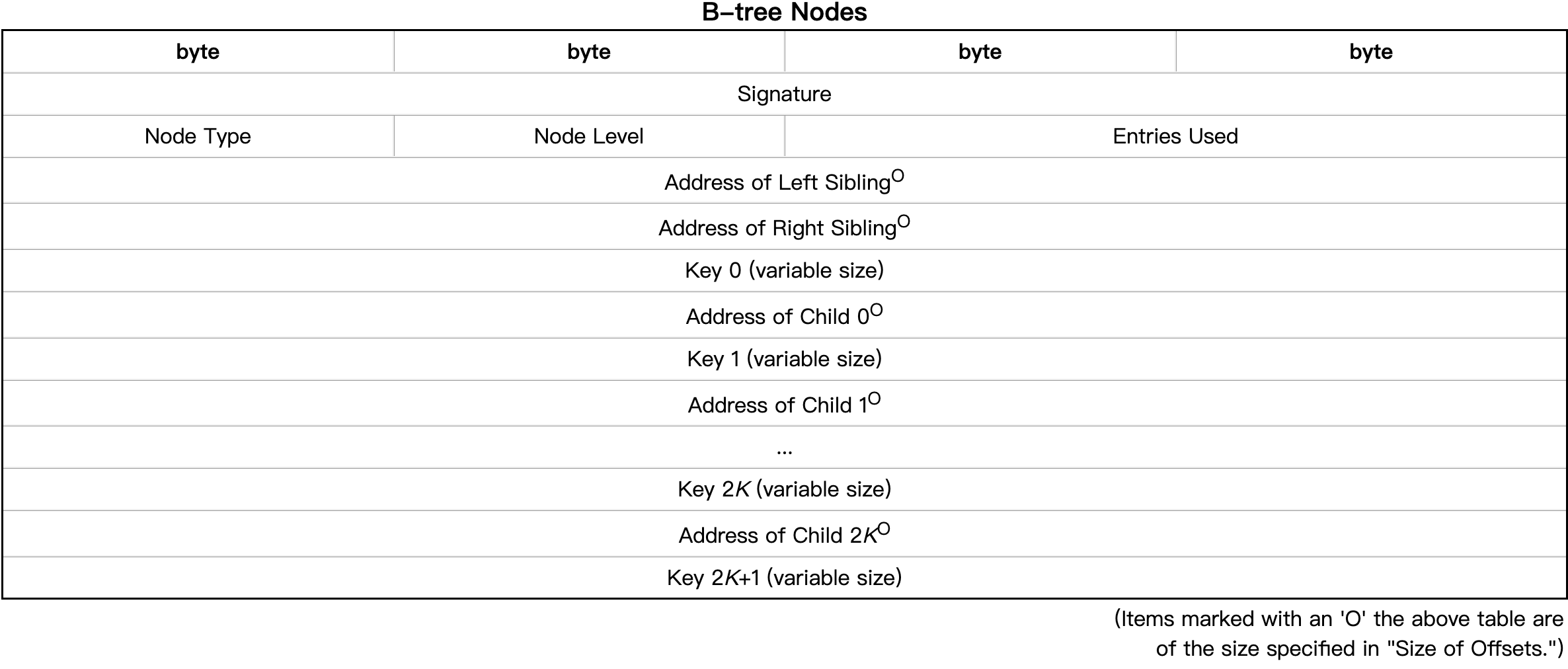
| Field Name | Description |
|---|---|
| Signature | The ASCII character string “TREE“ is used to indicate the beginning of a B-link tree node. This gives file consistency checking utilities a better chance of reconstructing a damaged file. |
| Node Type | 0 该树指向组节点 1 该树指向原始数据块节点 |
| Node Level | 节点级别表示该节点在树中出现的级别(叶节点在级别0)。该级别不仅指示子指针是指向子树还是指向数据,而且还可用于帮助文件一致性检查实用程序重建损坏的树。 |
| Entries Used | 该节点所指向的子节点的数量 |
| Address of Left Sibling | 这是当前节点的左同级的相对文件地址。如果当前节点是该级别最左边的节点,则该字段为未定义地址 |
| Address of Right Sibling | 这是当前节点的右同级的相对文件地址。如果当前节点是该级别最右边的节点,则该字段为未定义地址。 |
| Keys and Child Pointers | 每个树有2K个键,键之间有2K个子指针。实际包含有效值的键和子指针的数量由节点的Entries Used字段决定。如果该字段为N,则B-link树包含N个Child Pointer和N+1个Key。 |
Group Node
组所指向的对象的某些元数据除了对象的头数据外,还可以缓存在组的符号表中
组是由B-link树指向的组节点的集合。每个组节点包含一个或多个符号的条目。如果尝试向包含2K项的已满的组节点添加一个符号,则该节点将被分割,一个节点包含K个符号,另一个包含K+1个符号

| Field Name | Description |
|---|---|
| Signature | “SNOD”表示组节点的开始。这使文件一致性检查实用程序有更好的机会重建损坏的文件。 |
| Version Number | 组节点的版本号 |
| Number of Symbols | 该字段表示有多少条目包含有效数据 |
| Group Entries | Each symbol has an entry in the group node. The format of the entry is described below. There are 2K entries in each group node, where K is the “Group Leaf Node K” value from the super block |
Group Entry

| Field Name | Description |
|---|---|
| Name Offset | 对象名称在组的 本地堆 中的字节偏移量 |
| Object Header Address | 每个对象都有一个对象头,作为对象元数据的永久位置。除了出现在对象header中, some metadata can be cached in the scratch-pad space. |
| Cache Type | The cache type is determined from the object header. It also determines the format for the scratch-pad space: Type:Description:0 组表项不缓存任何数据. 1 对象标头元数据缓存在组条目中 2 该条目是一个符号链接 . |
| Reserved | 对齐值 |
| Scratch-pad Space | 是一个用于存储元数据的缓存空间。它可以存储与该组相关的一些元数据,例如链接计数、最大创建索引等信息,以提高I/O性能并减少元数据访问的开销。在写入或更新文件时,HDF5库将Scratch-pad Space中的元数据写入到文件的磁盘位置,以确保元数据的持久性。此外,Scratch-pad Space还可以存储数据集对象的元数据,以避免在访问数据集对象时需要频繁读取文件。 |
Format of the Scratch-pad Space
略
Local Heaps
Local Heap是一种用于存储小块可变长度数据的堆结构,通常与数据集或属性相关联。在HDF5文件中,每个Group可以包含一个或多个数据集或属性,这些数据集或属性都可能需要使用Local Heap来存储它们的元数据【类型,维度,名称,块大小,其他元数据】

(Items marked with an ‘L’ are specified in “Size of Lengths.”) (Items marked with an ‘O’ are specified in “Size of Offsets.”)
| Field Name | Description |
|---|---|
| Signature | ASCII字符串“HEAP”用于表示堆的开始。这使文件一致性检查实用程序有更好的机会重建损坏的文件 |
| Version | 每个本地堆都有自己的版本号,以便可以将新堆添加到旧文件中 |
| Data Segment Size | 为堆数据分配的磁盘内存总量。这可能大于存储在堆中的对象所需的空间量。堆中额外的未使用空间包含一个空闲块的链表 |
| Offset to Head of Free-list | |
| Address of Data Segment | 数据段最初在堆头之后立即开始,但如果由于添加更多对象而必须增长数据段,则数据段可能会整体重新定位到文件的另一部分 |
Global Heap

| Field Name | Description |
|---|---|
| Signature | ASCII字符串“’ GCOL ‘”用于表示集合的开始。这使文件一致性检查实用程序有更好的机会重建损坏的文件。 |
| Version | 每个集合都有自己的版本号,以便可以将新集合添加到旧文件中 |
| Collection Size | This is the size in bytes of the entire collection including this field. The default (and minimum) collection size is 4096 bytes which is a typical file system block size. |
| Global Heap Object 1 ~ N | 对象以任意顺序存储,中间没有未使用的空间。 |
| Global Heap Object 0 | 当存在全局堆对象0(零)时,表示集合中的空闲空间 |
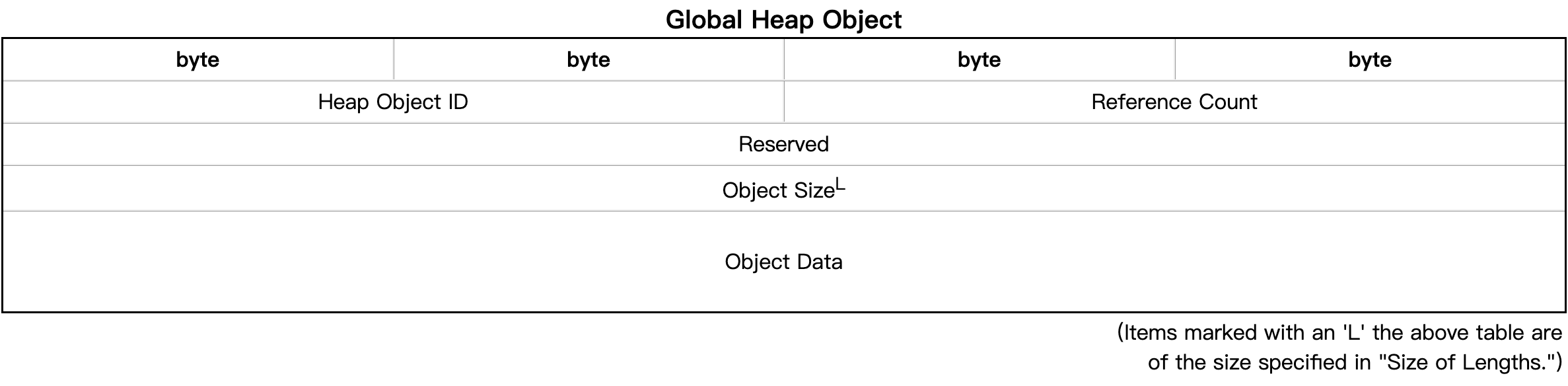
| Field Name | Description |
|---|---|
| Heap Object ID | |
| Reference Count | 所有堆对象都有一个引用计数字段。从文件的其他部分引用的对象将具有正引用计数 |
| Reserved | |
| Object Size | This is the size of the object data stored for the object. |
| Object Data | a one-dimensional array of bytes to be interpreted by the caller. |
Free-space Index
自由空间索引是分散在整个文件中的数据块的集合,这些数据块目前没有被任何文件对象使用。超级块包含一个指向自由空间的指针;
该格式还未定义
Level 2 - 数据对象
数据对象包含文件中的真实信息,这些对象组成了科学数据和其他通常被认为是”数据”的信息,文件中所有其他的的信息被提供作为这些数据对象的框架
数据对象由标头信息和数据信息组成。头信息包含解释数据对象的数据信息所需的信息,以及用于描述或注释每个数据对象的附加“元数据”或指向附加“元教据”的指针。
Data Object Headers
每个Object Header都由一个Header Message列表组成
Header Message通常包含有关对象的信息,例如对象类型、对象大小、数据类型、数据存储位置、创建时间、创建者、修改时间等等。它们也可以包含其他类型的元数据,例如属性列表、共享消息等。
Object Header的Header Message列表通常存储在Object Header的本地堆(Local Heap)中。当Object Header太大无法容纳在对象的头部时,Local Heap会被使用来存储额外的Header Message。在这种情况下,Object Header仍然包含必要的元数据(例如对象类型和大小),而附加的Header Message则存储在Local Heap中,并通过Heap ID来引用
将一个全是浮点数的CSV文件转换为HDF5文件时,该HDF5文件的结构中可能包含以下Header Message:
- Dataset Header Message:描述了CSV文件中的浮点数数据集,包括数据类型、维度大小等信息。
- Data Storage Header Message:描述了HDF5数据存储的位置和方式,包括压缩格式、压缩级别等信息。
- Filter Pipeline Header Message:描述了数据集上应用的压缩、过滤、加密等操作的管道信息。
- Attribute Header Message:描述了HDF5数据集的属性,例如创建时间、修改时间、作者等信息。
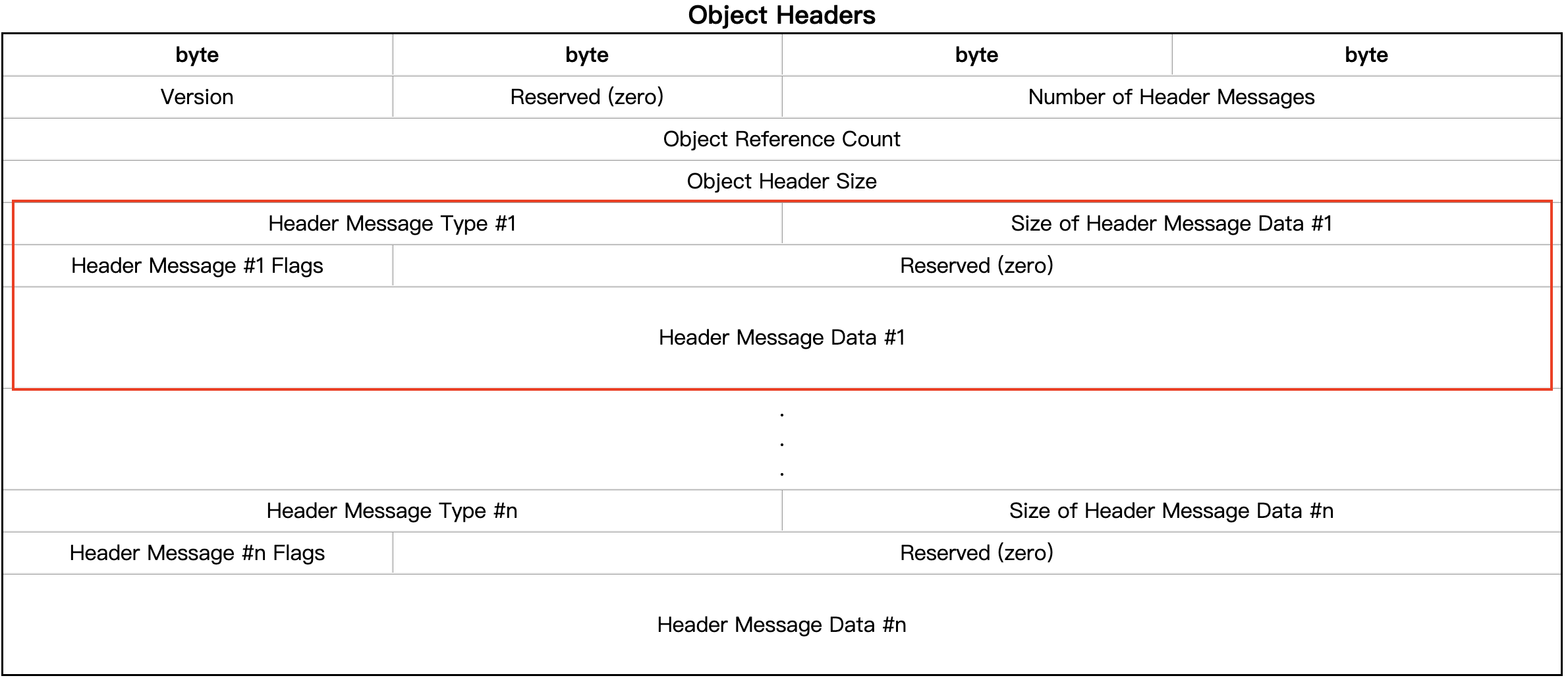
| Field Name | Description |
|---|---|
| Header Message Type | 指定包含在以下报头消息数据中的信息类型 |
| Size of Header Message Data | 此值指定当前消息的头消息类型和长度信息之后的头消息数据的字节数 |
| Header Message Flags | 如果为’ 0 ‘,则消息数据为常量。这用于像数据集的数据类型消息这样的消息。 如果为’ 1 ‘,则消息存储在全局堆中。The Header Message Data field contains a Shared Object message and the Size of Header Message Data field contains the size of that Shared Object message |
| Header Message Data | 有些报头消息类型不需要任何数据,可以通过将消息长度设置为零来消除这些信息 |
Data Object Data Storage
对象的数据与文件中的头信息分开存储,如果头表明数据存储在外部,则可能实际上不在HDF5文件本身中。
2⃣️Data Mode
HDF5文件(本身就是一个对象)可以被认为是一个容器(或组),它保存了各种异构数据对象 (或数据集)。数据集几平可以是任何东西:图像、表格、图形,甚至是文档,如PDF或Excel
HDF5数据模型中的两个主要object是组和数据集:
Group:包含零个或多个组或数据集实例以及支持元数据的分组结构。
数据集:数据元素的多维数组,以及支持的元数据。
HDF5数据模型中还有各种各样的其他对象支持组和数据集,包括datatypes, dataspaces, properties and attributes.
Groups
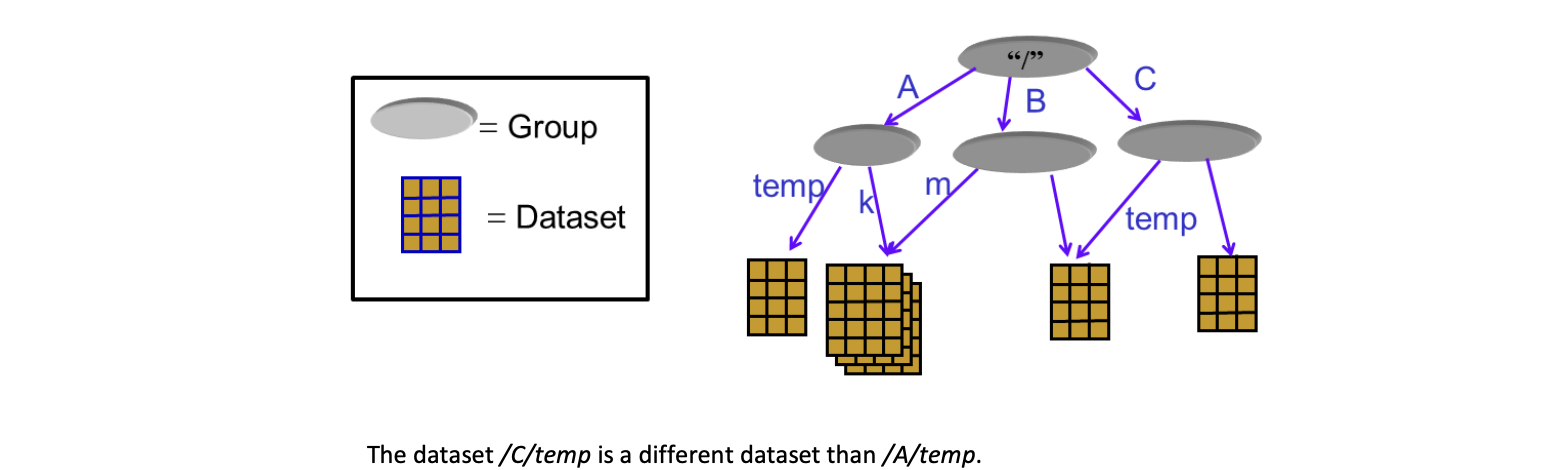
objects can be shared, so there can be multiple paths to the same objects. In the picture above /A/k and /B/m point to the same object.
Datasets
HDF5数据集组织并包含raw数据值。数据集除了数据本身之外, 还有用来描述数据的元数据组成。
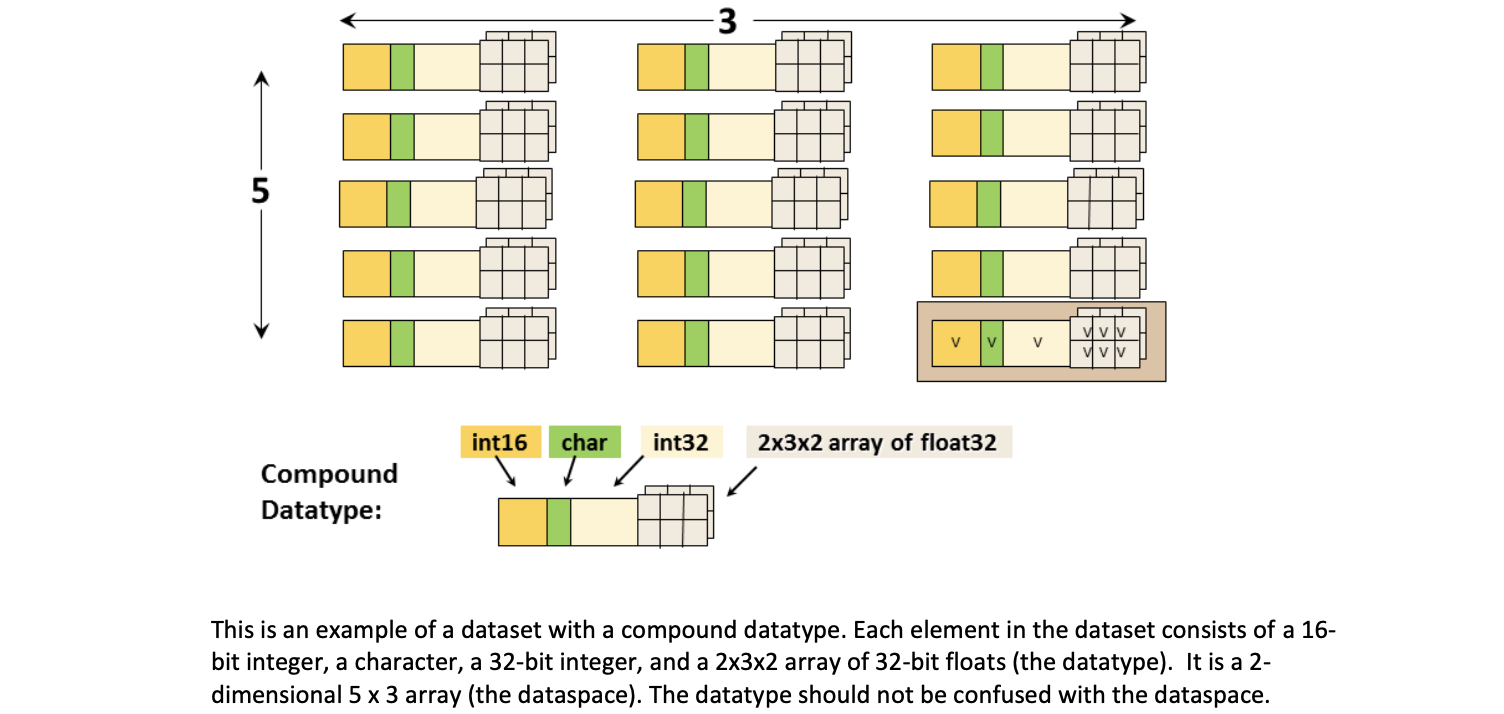
Datatypes
The datatype describes the individual data elements in a dataset. It provides complete information for data conversion to or from that datatype.
Datatypes有两大类:
- Pre-Defined Datatypes: These are datatypes that are created by HDF5. They are actually opened (and closed) by HDF5 and can have different values from one HDF5 session to the next.
- Standard datatypes: are the same on all platforms and are what you see in an HDF5 file.
- Native datatypes:are used to simplify memory operations (reading, writing) and are NOT the same on different platforms.
- Derived Datatypes: These are datatypes that are created or derived from the predefined datatypes. 嵌套复合数据类型也是派生类型Nested compound datatypes are also derived types.
Pre-Defined Datatypes
当从内存中读写时,HDF5库必须知道描述特定架构布局的适当数据类型。
Pre-defined datatypes have standard symbolic names of the form H5T_ARCH_BASE where ARCH is an architecture name and BASE is a programming type name:
如:
H5T_IEEE_F32BE
IEEE indicates standard floating point types.
F32BE 表示32位大端浮点数
H5T_STD_I8LE
STD 表示半标准数据类型
I8LE 表示8位小端整数
H5T_C_S1
C 专门为C语言设计的格式
S1 只有一个字符的字符串
HDF5支持多种数据类型:
- Integer
- Float
- Character
- Reference :a reference to another object or dataset region within the HDF5 file
- Enumeration
- Opaque :uninterpreted (by HDF5)
- Compound: similar to C structs
- User-defined :eg, 13-bit integer or fixed/variable length strings
Dataspaces
describes the layout of a dataset’s data elements
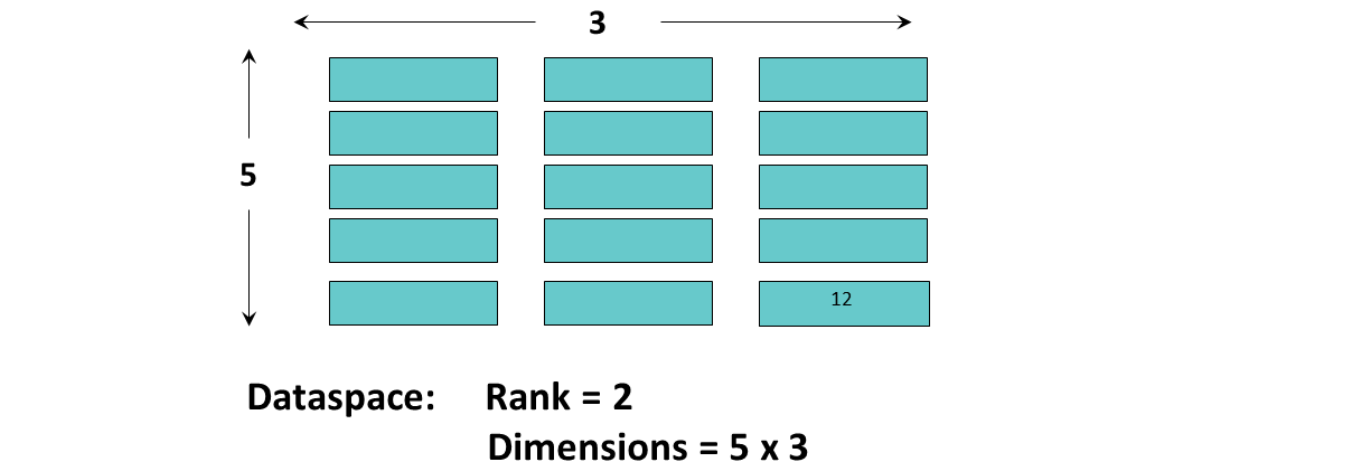
数据空间的维度可以是固定的(不变的),也可以是无限的,可以扩大规模(即它们是可扩展的)。
数据空间的两种作用
- dataset的元数据
- 参与I/O时可以用来选择dataset的一部分或子集
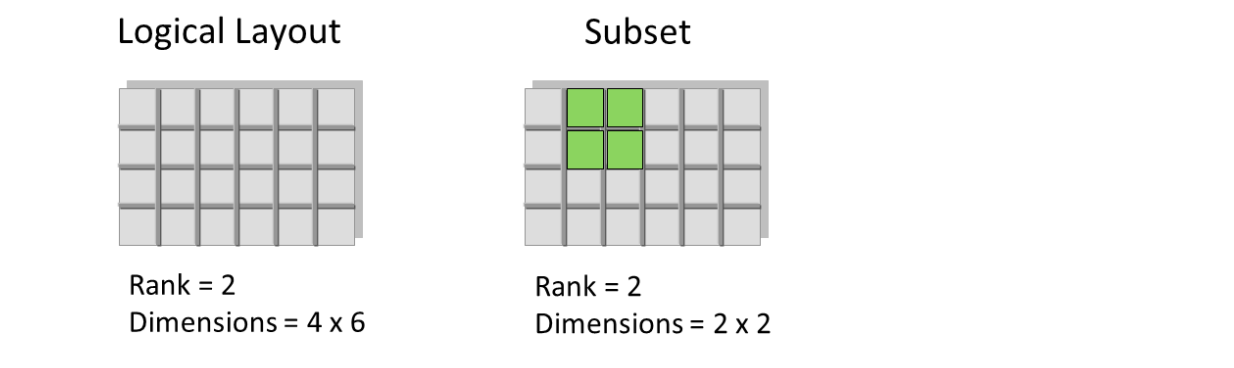
Properties
A property is a characteristic or feature of an HDF5 object.
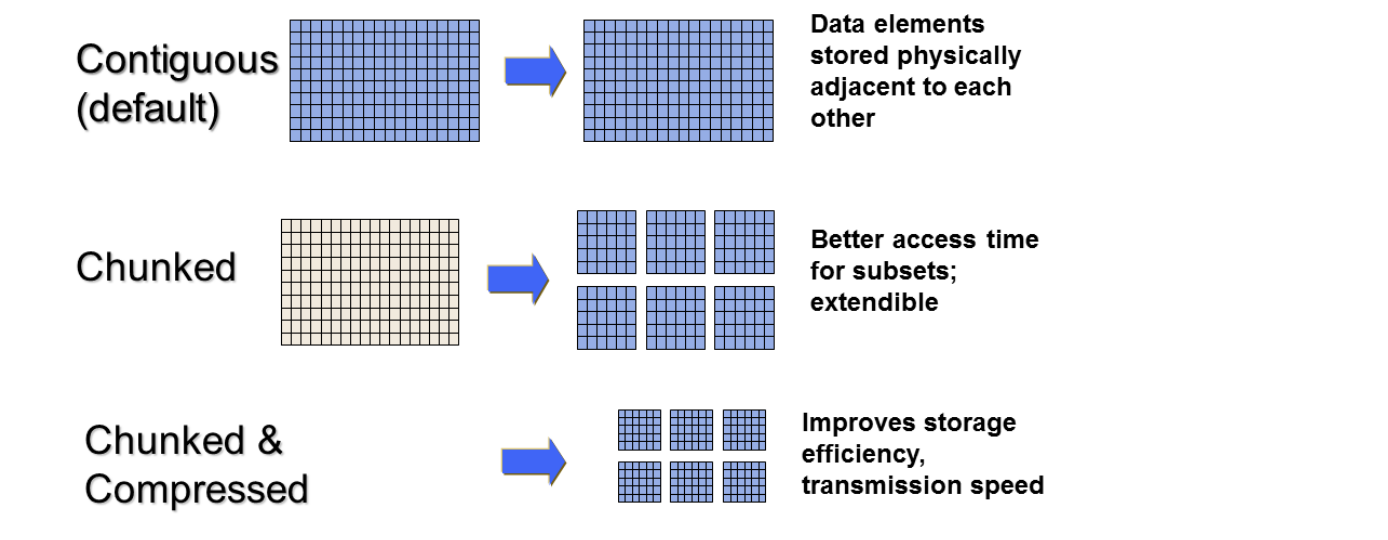
默认情况下,数据集的数据存储布局属性是连续的。为了获得更好的性能,可以将布局修改为分块或分块压缩:
Attributes
描述了HDF5数据集的属性,例如创建时间、修改时间、作者等信息。这部分do not support partial I/O ,operations,cannot be compressed or extended.
3⃣️ HDF5 APIs and Libraries
H5A Attribute Interface |
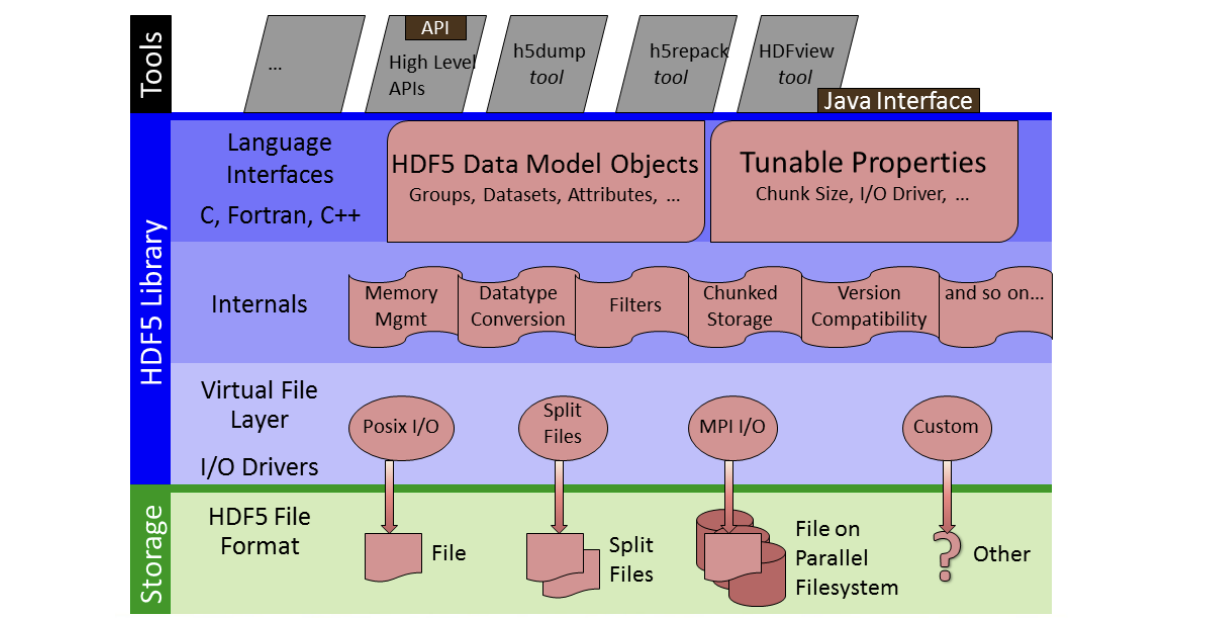
在其最高级别HDF5提供了用C、FORTRAN、C++和Java编译应用程序的工具和API。
在其最低层次HDF5由虚拟文件层组成,其中包括I/O驱动程序,用于与不同的文件类型进行接口。在这些层之间是HDF 5的内部。
The most commonly used (and default) I/O driver interfaces with a single file.
The MPI I/O driver allows different processors to interface with a given file in a parallel filesystem.
The Split File I/O driver enables HDF5 metadata to be stored in one file and the data in another.
用户也可以使用HDF5创建自己的自定义I/O驱动程序
h5dump: 转储或显示HDF5文件的内容
h5cc, h5c, h5fc: 编译应用程序的Unix脚本
HDFView: 查看HDF (HDF4和HDF5)文件的java浏览器
4⃣️HDF5 Programming Model and APIs
HDF5应用程序编程接口是广泛的(包含数百个函数)。然而,有几个函数可以完成大部分工作。
File Interface: H5Fopen (C)
Dataset Interface: H5Dopen (C)
Dataspace interface: H5Sclose (C)
为了可移植性,HDF5库有自己定义的类型。
hid_t is used for object handles
hsize_t is used for dimensions
herr_t is used for many return values
创建文件

/* |
创建数据集
Define the dataset characteristics:
a) Datatype
b) Dataspace
c) Properties (or use default)
Decide which group to attach the dataset to.
Create the dataset.
Close the dataset handle.
Example:

/* Create the dataspace for the dataset. */ |
从数据集中读写
传入H5S_ALL用于内存和文件数据空间参数,以指示整个指定数据集的数据空间。这两个参数可以修改为允许
数据集的子集。本机预定义数据类型H5T_NATIVE_INT用于读取和写入,以便HDF5将做任何必要的整数转换:
status = H5Dwrite(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT, dset_data); |
创建组
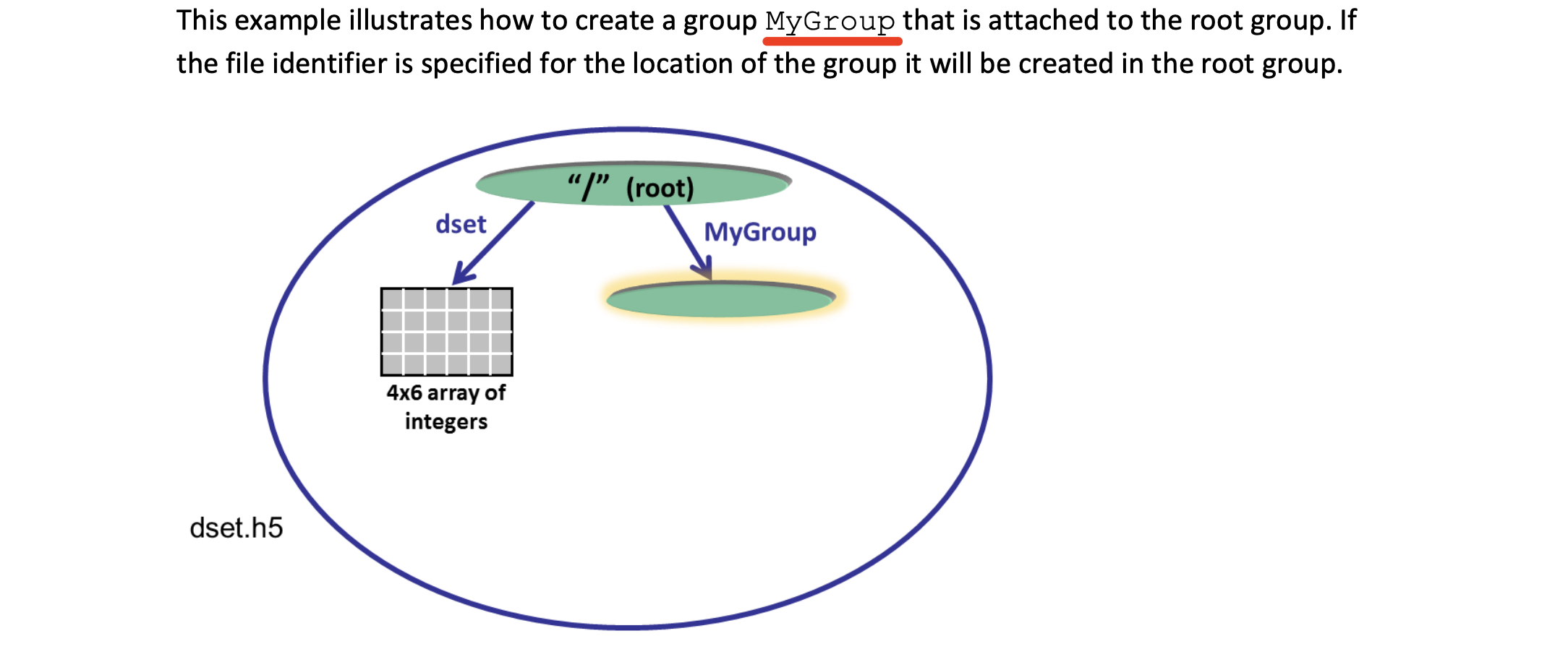
group_id = H5Gcreate (file_id, "MyGroup", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT); |
创建并写入Attribute
/* Create the data space for the attribute. */ |
分块细节
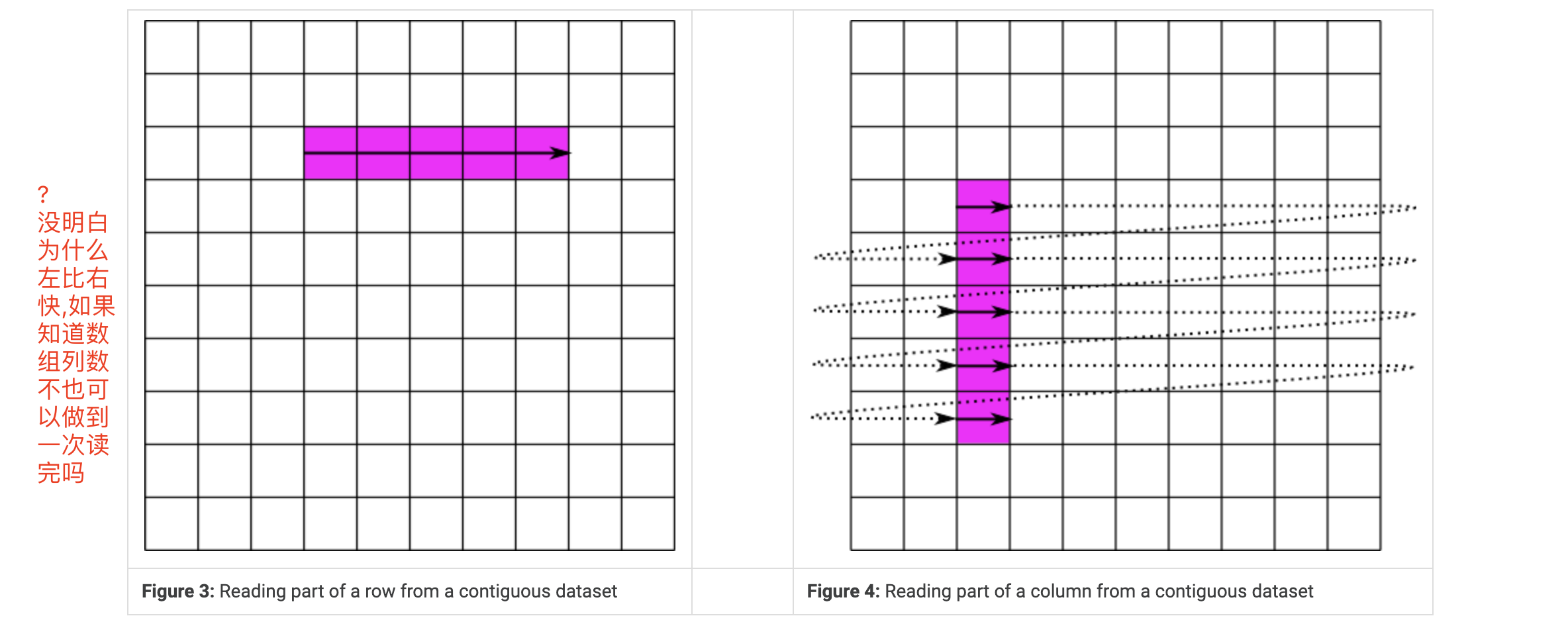
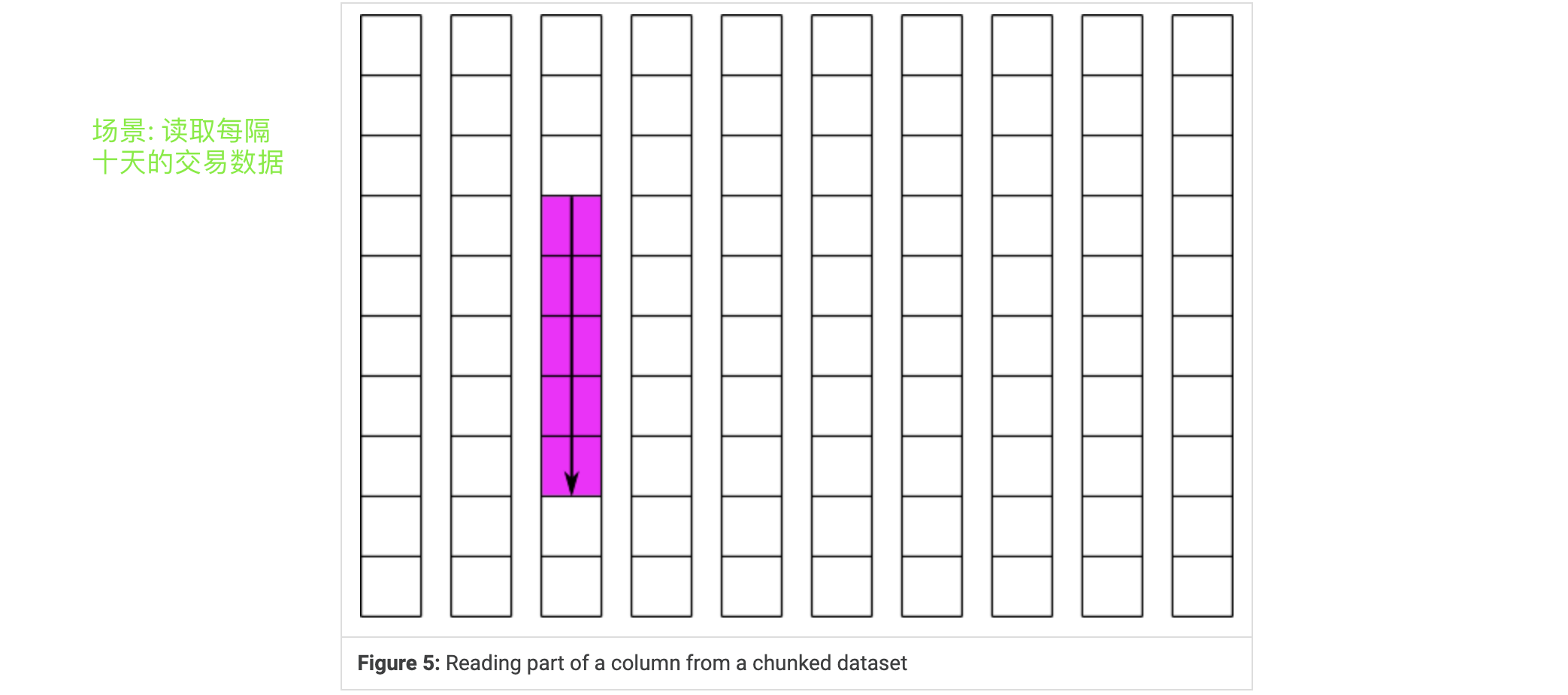
连续布局的进阶版是分块布局。而连续的数据集存储在文件中的单个块中,分块数据集被分割成多个块,这些块都单独存储在文件中。块可以在HDF5文件中以任何顺序和任何位置存储。然后可以单独读写块,从而提高在数据集子集上操作时的性能。
|
Chunking and Partial I/O
|
Chunk Caching
是数据集块的缓存。可以防止库多次从磁盘读取和写入数据, 在多次读取或写入相同块时显著提高性能.但是块缓存的当前实现不会自动调整其参数,因此必须手动调整参数以实现最佳性能。在某些罕见情况下,最好完全禁用块缓存方案。每个打开的数据集都有自己的块缓存,与所有其他打开的数据集的缓存分开。
从分块数据集中读取已选择的的区域时,首先将包含选择的块读入缓存,然后将那些块的选定部分复制到用户的缓冲区中。缓存的块一直保留在缓存中,直到它们被驱逐。这通常是因为需要在缓存中为新块腾出更多空间,但它们也可能被驱逐,如果哈希值冲突的话(稍后会有更多讲解)。一旦块被驱逐,如果必要的话,就会将其写入磁盘并从内存中释放。
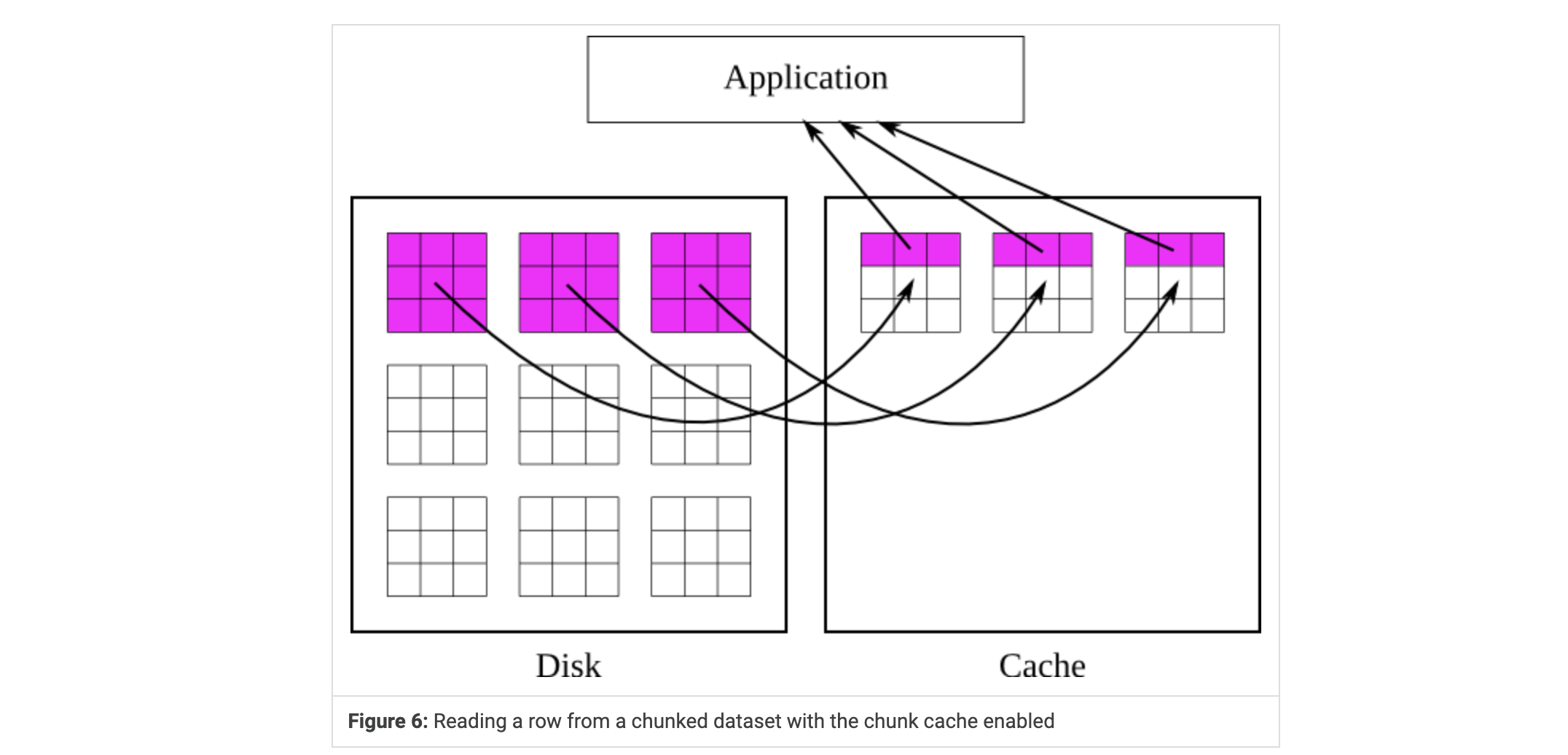
FIg6 应用程序请求一行值,库会将包含该行的块加载到缓存中,并从缓存中检索值。
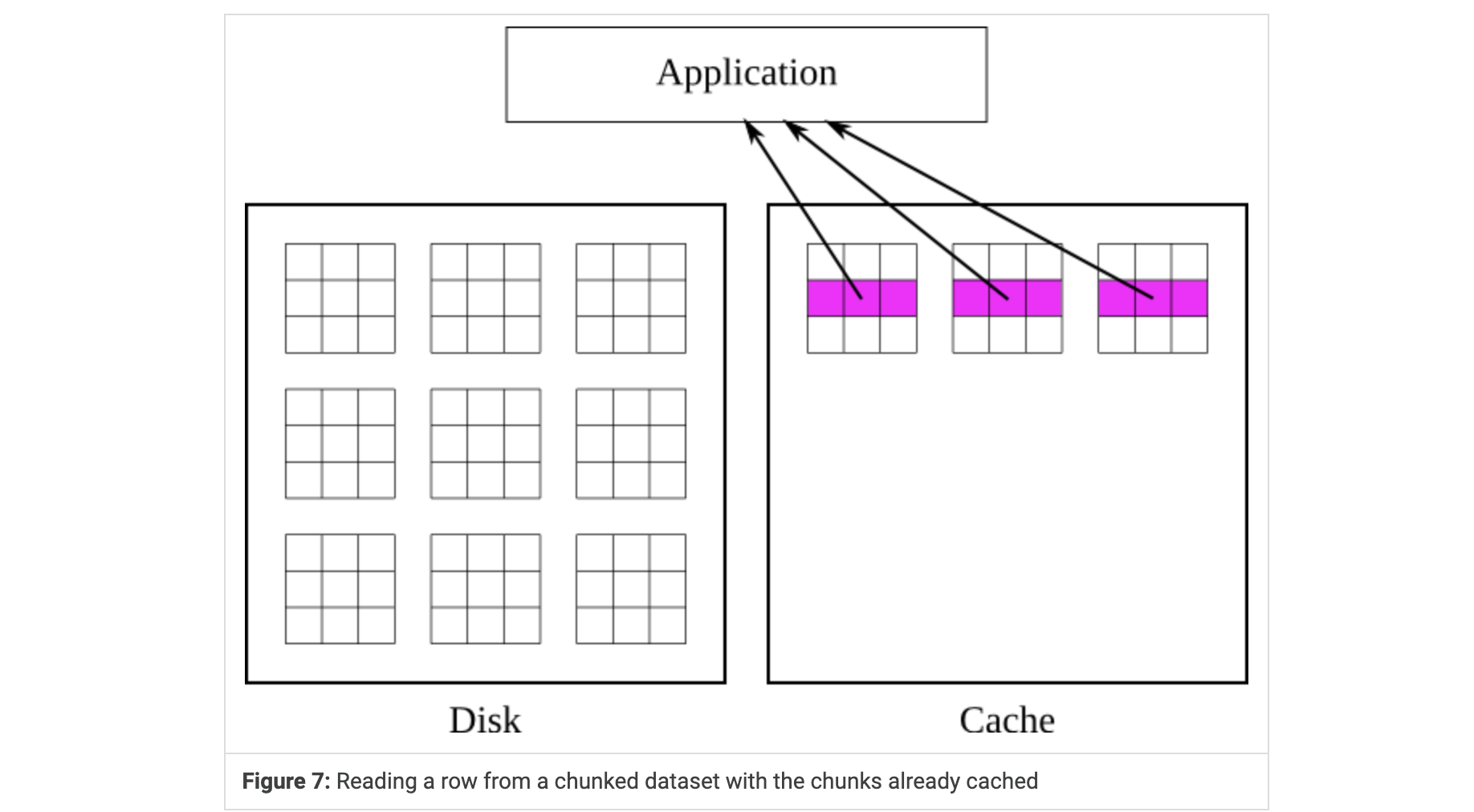
Fig7 此时如果应用程序请求一个不同的行,库就直接从缓存中检索值而不接触磁盘。
Chunk Flitering
由于每次将过滤器应用于整个块,所以在使用I/O过滤器(包括压缩)时,数据集分块也可以派上用场。过滤器应用于每个块,整个块一次性处理。每次将块加载到缓存中和将块刷新到磁盘时都必须应用过滤器。所有这些事实都使得选择适当的块缓存和块大小对于过滤数据集的性能尤为关键。
由于每次磁盘I/O发生时都必须过滤整个块,因此在向许多不同的块写入少量数据时并不能禁用块缓存,所以这是HDF5的性能瓶颈
为了实现可接受的性能,必须尽量减少在块被完全读取或写入之前将块从缓存中刷新的机会。这可以通过增加块缓存的大小、调整块的大小或调整I/O模式来实现
🌟 Q&A
1. 一个数据集中的数据可以有多种类型吗?使用过程中可以改变类型吗?
All elements of the dataset must have the same type
The datatype of a dataset is immutable
2. 数据集使用过程中可以改变其数据空间(dataspaces)吗?
可以
3.HDF5文件可以直接以二进制的形式写入其特定部分而不需要修改文件其余部分吗
在HDF5中,数据可以以数据块(Data Chunk)的形式存储的。每个数据块是文件中的一个独立单元,可以单独读取或写入,而不需要修改文件的其他部分。因此,如果要写入的数据长度不超过文件中已有数据块的长度,则可以直接覆盖该数据块,而不需要修改文件的其他部分。这样可以提高数据写入的效率和速度,减少不必要的开销和资源消耗。
4.如果要写入的数据长度超过了文件中已有数据块的长度怎么办
如果要写入的数据长度超过了文件中已有数据块的长度,就需要对文件进行扩展。在HDF5中,数据块的大小是预定义的,当需要存储的数据大小超过了某个数据块的大小时,需要将数据分成多个数据块来存储。
- 获取当前文件中最后一个数据块的偏移量和长度信息。
- 计算要写入数据的长度和偏移量,以确定需要扩展文件的大小和位置。
- 使用HDF5库提供的API函数对文件进行扩展,并将要写入的数据写入新扩展的数据块中。
- 更新文件中的元数据,以便下一次读取文件时能够正确地识别和读取新扩展的数据块。
5.在HDF5中,数据以数据块的形式存储,这些块之间的顺序和解压出来的源文件顺序一致吗
不一定,这些数据块可以按照任意顺序存储在文件中,并且可以通过文件中的元数据来描述它们之间的关系。因此,这些块之间的顺序和解压出来的源文件顺序不一定一致。
具体而言,在HDF5文件中,每个数据块都有一个唯一的地址(Address)和长度(Length),可以通过这些地址和长度来定位和读取数据块。这些地址和长度信息存储在文件的元数据中,而不是存储在数据块本身中。因此,如果数据块在文件中的顺序发生改变,其地址和长度信息也会相应地被更新。
当读取HDF5文件时,HDF5库会根据文件中的元数据来识别数据块的地址和长度,从而将其按照正确的顺序解压出来。因此,即使数据块之间的存储顺序发生了改变,只要元数据正确,就可以保证读取的数据与源文件的顺序一致。
6.有一个a.csv.h5文件,该HDF5文件可以做到时间复杂度为O(1)的增删改查而不用先解压为a.csv再修改,重新生成HDF5文件吗
HDF5文件支持可变长度数据集(Variable-Length Data Sets)和扩展数据块(Extendible Data Sets)等特殊的数据类型,可以支持动态增删改查操作。如果将CSV文件转换为使用可变长度数据集或扩展数据块的HDF5格式,则可以实现O(1)的增删改查操作。这种方法可能会增加文件的大小,但可以提高文件的灵活性和可操作性。
7.一个全存浮点数的csv文件a.csv,其中浮点数长度各不相同,若将它存为a.csv.h5文件,该HDF5文件中所有浮点数的存储格式是怎么样的?
对于包含浮点数的CSV文件,如果浮点数长度各不相同,可以将它们转换为可变长度数据集,并将每个浮点数存储为一个变长的数据类型,例如VLFloat,这样可以有效地节省存储空间。VLFloat类型可以表示任意长度的浮点数,而不需要指定固定的长度。具体的存储格式可能会根据数据类型和存储选项的不同而有所差异,可以通过HDF5库的API函数来读取和写入这些数据。
但使用可变长度数据集存储浮点数可能会影响数据的访问效率,因为访问变长数据需要进行动态内存分配和释放操作。如果对数据的访问效率有较高的要求,可以考虑将浮点数按照一定的规则进行划分,或者使用固定长度的数据类型来存储数据。
8.如何在分块缓存中快速地找到已载入内存的块?
为了允许在缓存中快速查找块,每个块被分配一个唯一的哈希值,用于查找块。缓存包含一个简单的指向块的指针数组,称为哈希表。块的哈希值就是指向该块的指针在哈希表中的索引。虽然这个位置的指针可能指向不同的块,或者根本不指向任何东西,但哈希表中没有其他位置可以包含指向有问题的块的指针。因此,库只需要检查哈希表中的这一个位置来判断块是否存在
9.什么是HDF5中的过滤器
在HDF5中,FIlter是一种可选的、可插拔的组件,它可以在读写数据时对数据进行压缩、加密、格式转换等处理。过滤器可以分为两类:本地过滤器和外部过滤器。本地过滤器是由HDF5库本身实现的过滤器,例如shuffle和deflate等过滤器,而外部过滤器是由第三方库实现的过滤器,例如LZF和BZIP2等过滤器。使用过滤器可以大大减少磁盘空间和I/O带宽的消耗,同时也可以提高数据读写的速度。在HDF5中,过滤器可以通过数据集的属性列表进行配置。
10.HDF5的性能瓶颈
由于每次磁盘I/O发生时都必须过滤整个块,因此在向许多不同的块写入少量数据时并不能禁用块缓存,所以这是HDF5的性能瓶颈
过滤器:虽然过滤器可以通过压缩和优化数据来减少I/O操作,但过多的过滤器可能会降低性能。因此,在选择过滤器时,应仔细考虑其对性能的影响
缓存:虽然缓存可以减少磁盘访问,但较小的缓存可能会导致频繁的磁盘I/O操作,从而降低性能。因此,应根据数据集大小和访问模式等因素来选择适当的缓存大小
11.有哪些第三方库支持简化版HDF5操作?
PyTables是一个较高级别的库,提供了与HDF5文件交互的接口,包括高级索引和查询功能。
h5py是一个较低级别的库,提供了更直接的HDF5文件接口,使用户可以更高效地读写数据。
除此之外,还有一些插件可供常用可视化和分析工具使用,例如ParaView和VisIt。
具有基于HDF的表示的社区标准示例包括NASA的HDF-EOS5、NeXus、CGNS、Energistics的RESQML和SEG的H5EM-TS。Unidata的netCDF-4软件使用HDF5作为数据管理层。
源码
链接:https://github.com/HDFGroup/hdf5.git
目录:
bin: 该目录通常包含可执行文件或脚本。 |