权限管理
权限管理概述
ACL
ACL (Access Control List) 是权限控制中的一种常见机制,用于管理和控制对资源的访问权限。ACL 是一张表格或数据结构,它列出了用户或用户组对于特定资源的权限信息。通常,ACL 由以下两个要素组成:
- 主体(Subject):主体可以是用户、用户组或角色,它代表了一个实体或一组实体。
- 权限(Permission):权限定义了主体对资源可以执行的操作。常见的权限包括读取、写入、修改、删除等。
ACL 可以在资源级别或对象级别进行配置。在资源级别 ACL 中,ACL 条目直接与资源关联,用于控制对整个资源的访问权限。而在对象级别 ACL 中,ACL 条目与资源内的特定对象关联,用于细粒度地控制对对象的访问权限。
例如,假设一个文件系统使用 ACL 进行权限控制。以下是一个 ACL 的示例:
文件名: my_file.txt |
当有用户请求访问该文件时,文件系统会根据 ACL 检查用户的身份,并根据 ACL 条目决定是否允许该用户执行操作。ACL 提供了一种灵活且细粒度的权限控制机制,适用于各种应用场景,如操作系统、数据库、网络设备和 Web 应用程序等。
RBAC
RBAC (Role-Based Access Control) 是权限控制中一种常用的模型。它是一种访问控制策略,用于管理系统中用户对资源的访问权限。RBAC 的核心思想是基于角色的授权,将权限分配给角色,而不是直接分配给个别用户。
RBAC 模型中通常包含以下几个核心概念:
- 角色(Role):角色代表一组相似职责或行为的用户集合。例如,一个系统可能有管理员角色、编辑角色和读者角色等。
- 权限(Permission):权限是指可以执行的特定操作或访问的资源。权限通常以细粒度的方式定义,以便根据需要进行灵活的控制。
- 用户(User):用户是系统中的个体实体,可以与一个或多个角色相关联。用户通过与角色的关联而获得相应的权限。
- 授权(Authorization):授权是指将权限分配给角色或用户的过程。在 RBAC 中,管理员可以根据用户的职责和需求,将合适的角色和权限授权给用户。
通过使用 RBAC,系统管理员可以更好地组织和管理用户的权限,提高系统的安全性和可管理性。RBAC 模型提供了一种灵活而又可扩展的方法,适用于各种不同规模和复杂度的系统。
以一个简单的网上购物系统为例来说明 RBAC 的应用。在这个系统中,我们可以定义以下角色和权限:
- 管理员角色(Admin Role):
- 创建和管理用户账户(Create/Manage User Accounts)
- 添加、编辑和删除商品信息(Add/Edit/Delete Product Information)
- 处理订单和退款(Process Orders and Refunds)
- 访问系统日志(Access System Logs)
- 销售员角色(Salesperson Role):
- 创建和管理用户账户(Create/Manage User Accounts)
- 添加、编辑和删除商品信息(Add/Edit/Delete Product Information)
- 处理订单和退款(Process Orders and Refunds)
- 顾客角色(Customer Role):
- 浏览商品信息(View Product Information)
- 下单购买商品(Place Orders)
- 查看订单状态(View Order Status)
通过 RBAC,管理员可以创建并分配角色给系统中的用户:
- 用户 Alice 被分配了管理员角色,因此她具有创建和管理用户账户、添加、编辑和删除商品信息等权限。
- 用户 Bob 被分配了销售员角色,因此他具有创建和管理用户账户、添加、编辑和删除商品信息的权限,但没有访问系统日志的权限。
- 用户 Carol 被分配了顾客角色,因此她只能浏览商品信息、下单购买商品和查看订单状态,没有管理权限。
通过 RBAC 模型,系统管理员可以轻松管理用户的权限,根据角色的职责和需求进行授权,确保系统的安全性和可管理性。此外,如果需要更多的角色或权限,可以根据系统需求进行灵活扩展。
Casbin
组件
- 模型(Model):模型定义了访问控制策略的结构和规则。它定义了角色(Role)、资源(Resource)、操作(Action)等概念,并规定了它们之间的关系和约束。模型使用一种类似自然语言的声明式语法来描述策略规则。
- 策略(Policy):策略定义了实际的访问控制规则。它包含了一组策略规则,每个规则指定了主体(Subject)、资源(Object)、操作(Action)和访问效果(Allow/Deny)之间的关系。策略可以存储在文件、数据库或其他存储介质中。
- Enforcer:Enforcer是Casbin的核心组件,负责实际的访问控制验证和决策。Enforcer接受模型和策略作为输入,并提供了各种方法来执行授权检查,例如判断主体是否具有对资源执行特定操作的权限。Enforcer还可以对策略进行动态更新和管理。
- 适配器(Adapter):适配器用于将策略从持久化存储(如文件、数据库)中加载到Enforcer中,并将Enforcer中的变更持久化回存储介质。适配器可以根据需求选择不同的存储介质和格式,例如文件适配器、数据库适配器等。
- 策略效果器(Effector):策略效果器决定了如何计算多个策略规则的结果以确定最终的访问效果。例如,当一个规则允许访问而另一个规则拒绝访问时,策略效果器可以根据优先级或其他规则进行计算,以确定最终的访问效果。
- 规则函数(Function):规则函数是一些可自定义的函数,用于在策略规则中进行条件判断。开发者可以根据需要定义自己的规则函数,以便在访问控制过程中执行更复杂的条件判断逻辑。
这些组件共同协作,使Casbin能够实现灵活而强大的访问控制功能。开发者可以根据具体需求配置和扩展这些组件,以构建适合自己应用场景的访问控制系统。
工作流程
- 策略加载:接下来,Casbin的Enforcer通过适配器(Adapter)从
basic_policy.csv中加载策略数据。适配器负责将策略数据转换为Enforcer能够理解的内部格式,并将其加载到Enforcer中。 - 授权检查:当需要进行授权检查时,开发者可以调用Enforcer提供的方法,例如
Enforce()。Enforcer会接受主体(Subject)、资源(Object)和操作(Action)作为输入,并根据已加载的策略和模型进行授权检查。 - 规则匹配:Enforcer根据模型和策略进行规则匹配,找出与主体、资源和操作匹配的策略规则。
- 策略效果计算:当存在多个匹配的策略规则时,策略效果器(Effector)会根据配置的规则计算方式来确定最终的访问效果。例如,根据规则优先级进行计算,或按照某些规则进行逻辑运算。
- 授权决策:根据计算得到的访问效果,Enforcer会返回授权决策结果,即是否允许或拒绝访问请求。
- 策略管理:开发者可以使用Enforcer提供的方法来进行动态的策略管理,例如添加、删除或修改策略规则。这些变更可以通过适配器持久化到存储介质中,以便下次加载时使用。
整个工作流程中,Enforcer作为核心组件负责调度和协调各个组件的工作。它通过模型文件定义访问控制模型,使用适配器加载策略数据,并在授权检查时执行策略匹配和效果计算。最终,Enforcer返回授权决策结果给应用程序。开发者可以根据需要使用Enforcer提供的方法来管理和操作策略规则。
Demo
|
杂
SVN和Git的区别
SVN(Subversion)和Git是两种不同的版本控制系统,它们在设计和工作方式上有一些重要的区别:
- 分布式 vs. 集中式:最重要的区别之一是Git是一种分布式版本控制系统,而SVN是集中式版本控制系统。在Git中,每个开发人员都拥有完整的代码仓库的副本,可以在本地进行提交、分支和合并等操作,而SVN需要连接到中央服务器来进行大多数操作。
- 速度:Git在速度方面通常比SVN更快。因为Git是分布式的,大多数操作都是在本地完成,无需网络连接,因此操作速度更快。而SVN需要依赖于中央服务器,对网络连接的质量和服务器的负载有一定的依赖。
- 分支和合并:Git在分支和合并方面更加强大和灵活。在Git中,创建、合并和切换分支非常快速和简便,开发人员可以轻松地在本地创建和管理多个分支。而SVN的分支和合并操作相对较慢和复杂,需要依赖于中央服务器,并且在合并时可能会出现冲突。
- 完整性和安全性:Git比SVN更具完整性和安全性。Git使用哈希值来标识每个文件和提交,从而确保数据的完整性和一致性。每个提交都有一个唯一的哈希值,使得检测和修复损坏的数据更容易。而SVN没有这种内建的完整性检查机制。
- 分布式开发和协作:由于Git是分布式的,开发人员可以在没有网络连接的情况下进行工作,每个人都可以拥有完整的历史记录和分支。这使得Git在分布式开发和远程协作方面更加灵活和强大。SVN在这方面相对较弱,需要依赖于中央服务器的连接。
总的来说,Git在速度、分支和合并、完整性和安全性以及分布式开发方面具有优势,而SVN在集中式控制和特定环境中的简单性方面可能更适合一些项目。选择使用哪种版本控制系统取决于具体的项目需求和团队偏好。
仓库中的分支管理
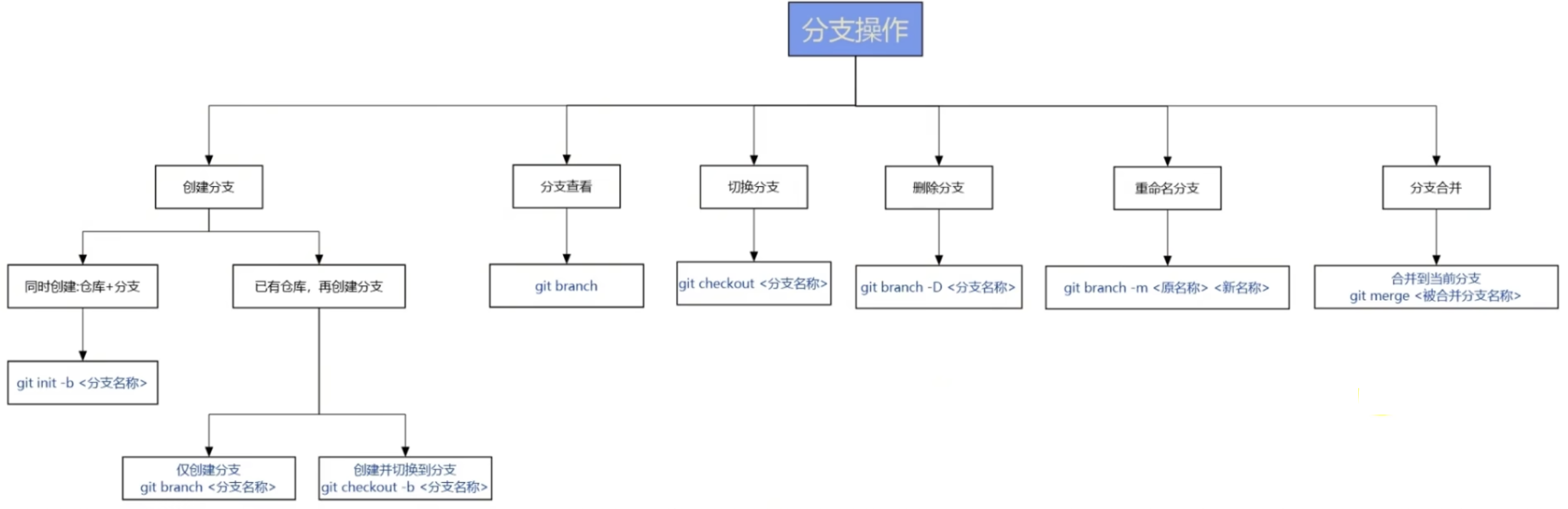
当你进行代码修改后,如果想要将这些修改提交到Git仓库,需要经过两个步骤:将修改的文件添加到暂存区
git add .然后再将暂存区的内容提交到仓库
git commit
fork + PullRequest
什么是fork?
fork 不是 Git 操作,而是一个 GitHub 操作,是服务端的代码仓库克隆。fork 后会在自己的github账户创建一个新仓库,它包含了原来的仓库 (即upstreamrepository,上游仓库)所有内容,如分支、提交历史等。你可以对 fork出的仓库 自由提交,并通过 PR(Pull Request) 贡献回 原仓库.由于fork出的新仓库是基于原仓库,但二者在后续开发中可能会大相径庭,所以被称为“分叉”
PullRequest
请求将修改应用到原仓库,需要原仓库主的批准
GIt 子模块
若项目根目录下有 .gitmodules 文件:
[submodule "ac/casbin-cpp"] |
# 从 url 初始化子模块至 path |
# 检查子模块状态 |
直接写.hpp与分别写 .cpp 和 .h 有何不同
防止头文件重复包含
#pragma once 和 #ifndef 是用于防止头文件重复包含的两种不同的机制。
#pragma once 是一种简洁的预处理指令,用于确保头文件只被编译一次。当编译器遇到#pragma once时,它会记住该文件已经被包含,并且在后续的包含中会跳过该文件,从而避免了重复包含的问题。这种机制在大多数主流的编译器中都被支持,是一种简单、直观的头文件保护方法。
#ifndef、#define 和 #endif 是传统的条件编译指令组合,也是防止头文件重复包含的一种常见做法。具体的使用方式是:
|
首先,#ifndef 检查是否已经定义了名为 H_FILE_NAME_H 的宏。如果该宏未定义,说明该头文件尚未被包含过,代码会继续执行。然后,通过 #define H_FILE_NAME_H 定义该宏,表示该头文件已经被包含。接下来,写入头文件的内容。最后,通过 #endif 结束条件编译块。
使用 #ifndef 的条件编译方式是一种传统、标准的头文件保护方法,广泛应用于各种编译器和项目。它的优点是兼容性好,可移植性强,但相对于 #pragma once,需要写更多的代码。